


Tabla de contenidos
Las cabeceras de cache del protocolo HTTP permiten controlar como se cachean cada uno de los tipos de archivo de una web en el navegador del usuario. Si se usan correctamente mejorará notablemente el rendimiento para los usuarios recurrentes de nuestro sitio, pero si no, podríamos cachear de manera indefinida y sin remedio, contenidos y redirecciones de los que, en realidad, queremos forzar su actualización.
Funcionamiento de la cache HTTP
Cachear es guardar un duplicado de los datos originales para acceder más rápido a ellos en un siguiente acceso. La cache HTTP consiste en guardar los archivos de una web en el navegador o en un proxy cache intermedio, de manera que las siguientes peticiones a los mismos archivos, no tienen que recuperarse del servidor de origen, si no que se obtienen o bien de la cache del navegador (lo que es bastante rápido porque la petición no tiene que viajar por la red), o se recupera de un servidor proxy (que en teoría debería estar más cerca o, al menos, ser más rápido sirviendo archivos que el servidor de origen). De esa forma, en una segunda carga, se acelera la obtención de todos los archivos de la web y se ahorran recursos de servidor.
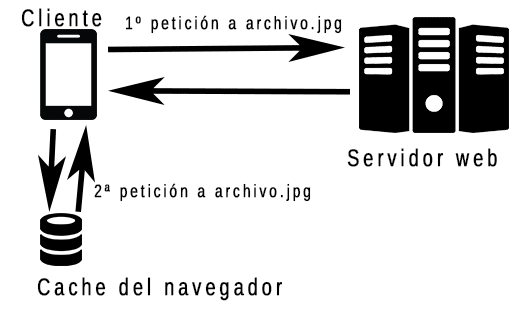
En un proxy intermedio se cachean los mismos archivos para varios clientes, de forma que un archivo pedido por un usuario puede que no sea necesario volver a pedirlo al servidor para otro usuario, pero hay que llevar cuidado de no cachear datos personales de un usuario que ha iniciado sesión, ya que no queremos que se le muestre a otro usuario datos que no son suyos. Podemos ver el funcionamiento visualmente en la siguiente imagen:
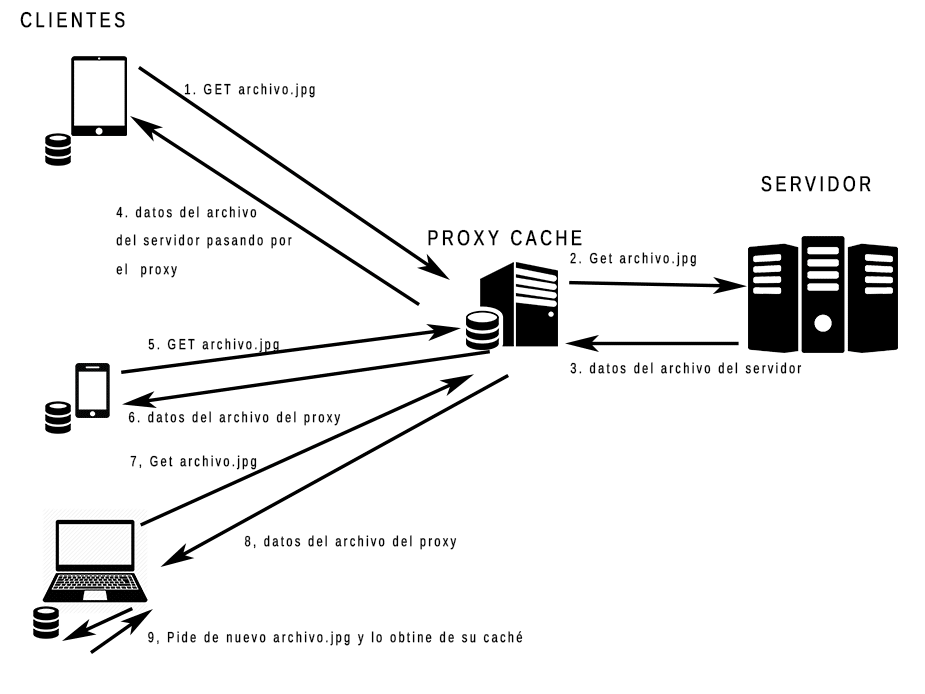
Si el proxy está del lado del servidor (no podemos llegar al servidor sin pasar por éste), se le llama proxy inverso. Si por el contrario está del lado del cliente (el cliente sale a Internet por éste), se le llama proxy directo.
Cabeceras de cache para las respuestas del servidor
La cache HTTP se configura con distintos parámetros que aportan información al navegador o al proxy cache intermedio sobre cómo se debe cachear o guardar el archivo. Dichos parámetros aparecen dentro de la cabecera del protocolo, encapsulando el archivo transmitido.
Sólo se ahorrará tiempo de carga, si hemos configurado correctamente los parámetros de la cabecera HTTP en el servidor. La configuración se puede hacer de muchas formas, se puede establecer que no sea necesario volver a pedir el archivo al servidor en una siguiente carga de la página, o podemos configurar los parámetros para que se pregunte al servidor si el archivo ha cambiado y, si no es así, el servidor no tendrá que devolver el archivo, sólo tendrá que indicar que el archivo no se ha modificado con un código de respuesta 304.
Veamos en profundidad que parámetros y opciones de configuración tenemos para cada uno de ellos, pero, si no te interesa profundizar, ve directamente a los casos de uso prácticos:
Cache-control
Sirve para definir el tipo de política de cache a utilizar. Se puede aplicar de forma individual a cada archivo, pero lo normal es establecer una política por tipo de archivo. Los valores o directivas que vamos a usar, en las respuestas que enviemos desde el servidor, son los siguientes:
- max-age: es el tiempo máximo en segundos que la respuesta se puede reutilizar en el cliente sin volver a pedirla al servidor. Por ejemplo «max-age=60» indica que el archivo se reutilizará desde la cache del cliente durante 1 minuto, a partir del momento que se realizó la petición. Esta directiva se aplica tanto a proxies como a clientes.
- s-max-age: igual que el anterior, pero sólo aplicable a proxies intermedios.
- no-store: indica que nunca se va almacenar la respuesta en el cliente así que siempre se descargará del servidor.
- no-cache: indica que siempre se debe comprobar si el archivo está actualizado en el servidor y si lo está, entonces descargarlo de nuevo. Con este valor «max-age» es ignorado. Lo lógico sería utilizar esta directiva o la anterior («no-store»), pero no los dos a la vez, aunque en muchas ocasiones verás que en algunas páginas usan las dos a la vez. Cuando esto ocurre los navegadores consideran que quieres utilizar la directiva más restrictiva «no-store», pero se ponen los dos porque Internet Explorer 6 usaba incorrectamente la directiva «no-cache» con el significado de «no-store», aunque hacer esto ya no es necesario porque este navegador ya está merecidamente extinguido.
- must-revalidate: indica que se debe forzar el cumplimiento de las otras directivas, aunque no conlleven una revalidación. Esta cabecera existe porque el cliente se puede configurar para aplicar su propia política de cache, como guardar las peticiones caducadas por un tiempo o puede dar respuestas caducadas si el servidor no responde. Con «must-revalidate» le decimos al cliente que ignore su configuración y obedezca a los parámetros que devolvemos desde el servidor. Esta directiva se aplica tanto a clientes como a proxies.
- proxy-revalidate: igual que el anterior pero sólo para proxies.
- public: la respuesta se puede cachear en servidores proxy intermedios ya que no contiene información privada de un usuario en concreto. Los proxies suelen asumir que esta es la opción por defecto.
- private: al contrario que la anterior indica que la respuesta contiene información privada y no debe almacenarse en un proxy intermedio. Podemos indicar el valor «public» o «private», pero no tiene sentido usar los dos a la vez.
- no-transform: un proxy intermedio no debe transformar la respuesta para, por ejemplo, optimizar la compresión de una imagen o minimizar un archivo CSS.
Hay más directivas pero son para la cabecera Cache-Control del cliente, los que nos interesan aquí son las que hemos visto, ya que son las que puede enviar el servidor.
ETag
Se llama token de validación. Es un hash del archivo (número en hexadecimal que cambia cuando el archivo se modifica). Por ejemplo, si el archivo caducó en la cache o si se ha establecido la política de revalidar siempre si está actualizado, el cliente envía el valor Etag al servidor en el parámetro «If-None-Match» y si éste ve que coincide con el que tiene almacenado, le envía una respuesta con código 304 (no se ha modificado), si no enviará el nuevo archivo con un nuevo Etag.
Last-Modified
Debe contener la fecha de la última modificación del archivo. Cuando existe el cliente, de forma similar al parámetro anterior, se envía en la petición la cabecera «If-Modified-Since» con el valor de la última fecha que recibió. Si el servidor tiene una fecha superior devolverá el archivo y si no una respuesta 304.
La existencia de Etag y Last-Modified es obligatoria para el funcionamiento de las políticas «no-cache», «max-age» y «must-revalidate», puesto que estos parámetros son necesarios para revalidar las peticiones. Así que debe existir al menos uno de ellos, aunque también pueden usarse a la vez. La no existencia de ninguna forma de validación, implica que siempre se devolverá la respuesta completa desde el servidor.
Vary
Indica si el contenido se debe cachear de forma independiente en función de si varia algún otro parámetro de la cabecera de la petición. Los valores que usemos dependerán de cómo se haya programado la web. Por ejemplo, «Vary: User-Agent» indica que si el parámetro User-Agent de la petición del cliente es distinto al de una petición anterior (esto ocurre, por ejemplo, cuando pinchamos en la opción «pedir sitio de escritorio» en un navegador móvil), entonces el navegador deberá cachear el resultado devuelto como un archivo distinto (así cacheamos la versión de móvil y de escritorio). Esto es necesario hacerlo en las webs adaptativas, en las que el HTML generado en el servidor cambia en función del User-Agent.
Otro ejemplo, si usamos el valor «Cookie», estamos diciendo que la respuesta es distinta si el cliente lleva una cookie diferente, lo cual se suele aplicar cuando la página cambia al modificar una cookie.
Así podríamos indicar cualquier parámetro de la cabecera HTTP, excepto «method» ya que sólo las peticiones que usan el método GET son susceptibles de cachearse. De hecho, si hacemos una petición por el método POST, PUT o DELETE de un archivo cacheado, esta se invalida y se lanza de nuevo la petición.
Con esta directiva siempre es recomendable usar el valor «Accept-Encoding» para evitar que los proxies intermedios devuelvan archivos con formatos de compresión incorrectos a clientes que no lo aceptan. Por ejemplo, si un cliente que acepta el formato de compresión brotli, se le devuelve un archivo en este formato, guardándose en la cache, y si el siguiente cliente sólo acepta gzip o incluso ningún tipo de compresión, en caso de que se le devuelva el mismo archivo cacheado en brotli, ocurrirá un error.
Age
Es sólo para proxies e indica el tiempo que estuvo el archivo en el proxy. Esto es necesario para controlar el tiempo que pasa el archivo en cache, ya que se debe contar desde que el servidor lo envió al proxy y no desde que el proxy lo envió al cliente.
Cabeceras de cache para el antiguo protocolo HTTP/1.0
Probablemente ya no existan clientes que soporten este protocolo, lo normal es encontrarnos con HTTP/1.1 o HTTP/2, así que actualmente no es necesario poner estas cabeceras. Sólo es necesario saber que significan por si nos encontramos con ellas.
Expires
Es la versión antigua del parámetro «Cache-control», y sólo permite establecer la fecha en la que caduca la respuesta. No es igual que el parámetro «max-age» de «Cache-control» que establece un tiempo a partir del momento en que se hizo la petición, pero si este último también aparece, entonces el valor de «Expires» es ignorado. Poniendo una fecha en el pasado, estamos diciendo que no se guarde en cache.
Pragma
Esta cabecera se usa con el valor «no-cache» para indicar que no se debe cachear en el navegador al igual que «Cache-control» con el valor «no-store».
Casos prácticos: ¿qué cabeceras de cache aplicar a cada tipo de archivo?
A continuación expongo los parámetros óptimos para los casos más habituales, pero para ajustarlo mejor a un caso concreto, es mejor que revises todas las opciones disponibles en el punto anterior, sobretodo en lo que respecta al parámetro Vary.
Archivos dinámicos
Esto son los archivos HTML que queremos que se actualicen en cuanto cambien, así que la cabecera que se debe establecer para estos archivos, seria:
Cache-Control: no-cache, must-revalidate Vary: Accept-Encoding Etag: "5a0ad72f-1396" last-modified: Tue, 14 Nov 2017 11:44:47 GMT
Dentro de Cache-Control, incluiremos la directiva public o private dependiendo de si la respuesta se puede compartir entre varios usuarios o no, respectivamente.
Otra opción sería cachear estos archivos por un tiempo muy limitado, aunque hayan cambiado, como por ejemplo, 5 segundos:
Cache-Control: max-age=5, must-revalidate
Esta solución es menos agresiva y ahorraría recursos en aquellas situaciones en las que el usuario recargue la página nada más cargar.
Archivos estáticos
Las imágenes (favicon incluido), archivos de JavaScript, CSS y fuentes se deben cachear por el máximo tiempo posible, ya que son recursos que cambian rara vez. Si queremos forzar la actualización de alguno de estos archivos, se puede cambiar el nombre y su referencia en el HTML. Hay herramientas de programación que permiten generar automáticamente un número de versión o un hash en el nombre del archivo e incluirla en el código, lo que es necesario para poder cachear por bastante tiempo y sincronizar la actualización de todas las caches de todos los archivos cuando queramos. Está técnica se le llama fingerprinting, si se usa un hash que es una fingerprint o huella digital del archivo. También se le llama revving si se usa un número de revisión. Cuando el desarrollador no usa una herramienta automática para generar el nombre del archivo y enlazarlo desde el código, en lugar del fingerprinting lo que hace, normalmente, es añadir una query string a la URL (por ejemplo: estilo.css?v=1), para evitar tener que cambiarle el nombre al archivo y refrescar la cache igualmente, pero no es la mejor opción porque los servidores proxy descartan el cacheo de URLs con query string.
El tiempo máximo que podemos indicar es de un año:
Cache-Control: public, max-age=31536000 Vary: Accept-Encoding Etag: "5a0ad72f-1396" last-modified: Tue, 14 Nov 2017 11:44:47 GMT
En este caso nos da igual que el cliente lo guarde en cache por más tiempo del necesario, porque si queremos actualizar cambiaremos el nombre al archivo y por eso no es necesario añadir la directiva must-revalidate.
Archivos que no se deben cachear
Esta situación sólo la tenemos con archivos que contienen información confidencial del usuario. Podemos usar:
Cache-Control: no-cache, no-store, must-revalidate
En este caso no es necesario indicar si se permite el almacenamiento público o privado porque estamos diciendo que no se debe cachear.
Por ser una cuestión de seguridad, aquí debemos ser más estrictos y añadir no-cache para guardar compatibilidad con IE6. Tampoco está demás si añadimos la vieja cabecera «expires» con una fecha en el pasado y «Pragma: no-cache».
Archivos de dominios externos
Si incluimos archivos de dominios externos sus parámetros de cache no dependerán de nuestro servidor, si no del servidor en el que están alojados.
Los archivos JavaScript de Google Analytics, Adwords y otras APIs, son archivos de dominios externos que no se deben cachear, ya que no sería práctico que todos los propietarios de páginas con estos scripts tuviesen que cambiar el nombre de archivo referenciado desde el HTML cada vez que Google saca una actualización.
Cuando hay scripts que no se cachean o tienen tiempos de cache pequeños, como en este caso, las herramientas automáticas de optimización Web como Google PageSpeed, dan un aviso de error a corregir, pero como la única solución para corregirlo es descargarse los archivos y servirlos desde nuestro servidor, es mejor no hacerlo porque si no tendríamos un problema cuando Google actualice el código. Este es uno de esos casos en los que es mejor sacrificar rendimiento en favor de la mantenibilidad y fiabilidad del código.
Evitar cachear redirecciones 301
En las redirecciones 301 y 307, puesto que son permanentes, también se tienen en cuenta los parámetros de Cache-control. Así que cuidado con esto, porque si ponemos una redirección 301 que no es correcta y el navegador del cliente la cachea durante un año, no habrá ninguna forma de forzar a que se actualice. Así que lo recomendable es que las redirecciones 301 no se guarden en cache (aquí podemos usar simplemente Cache-Control: no-store, must-revalidate). Además, nunca se sabe si querremos en un futuro, o después de una migración que ha ido mal, volver a las antiguas URLs. Si esto ocurre y tenemos las antiguas redirecciones cacheadas, al poner las nuevas podríamos provocar un bucle de redirecciones infinito en el navegador del usuario, en el que iría de una URL a otra, esa lo mandaría de nuevo a la anterior y así sucesivamente hasta que el navegador diese un error.
Las redirecciones 302, al ser temporales, no tienen este problema. Los parámetros de cache son ignorados.
Evitar cachear errores 404
Los errores 404 también se cachean, así que, al igual que con las redirecciones, es recomendable evitarlo, porque si en algún momento queremos que una URL que da 404 vuelva a devolver resultados, no queremos que algunos clientes mantengan cacheado el error.
Conclusión
Tal y como ya hemos visto en otras entradas como Optimización de CSS o Optimización de JavaScript los temas de WPO son complejos, sin embargo, la Cache HTTP es relativamente fácil de aplicar y se mejora considerablemente el rendimiento. El resto de técnicas, aunque son complejas, son necesarias para garantizar una buena experiencia de usuario, sobre todo en móviles, así que no dejar de aplicarlas en vuestros proyectos.
Referencias adicionales
- Cómo optimizar las fuentes de una Web
- Mejorando el WPO: la importancia de medir y optimizar el peso de los recursos estáticos



