

Written by Ramón Saquete
Index

The fact that there is structured data in schema.org that is equivalent or almost equivalent to HTML5 semantic tags, makes one suspect that this information may be important for Google’s spider (remember that schema.org is partly created by them).
It is not known for certain if Google takes into account this type of structured data and semantic tags in5in which case the effect can only be positive, since would allow the spider to know how the pages are organized and how they are answer several questions you need to resolve in order to correctly index the contents.
Questions such as: “How do I separate the header and footer from the main content?”, “Is there content that is not part of the main content but only transversal to it?” or “Which groups of links serve to navigate between several pages and are not simply a list of links on a specific page?”.
In short, it allows us to better identify the main content of the pages, which is the one that should be positioned and stand out above the rest of the content of each of our pages.
Marking this information with HTML5 semantic tags and at the same time with their equivalent structured data may seem redundant, but as we do not know to what extent Google takes into account one and the other, we recommend implementing both.
The tags <header> and <footer>, are used to mark the header and footer of any root section or content section element in HTML5. When used, the most important ones are those that are placed as direct daughters of the root section element <body>, without intermediate content section elements (<nav>, <article>, <section> y <aside>), since they indicate that it is the header and main footer that is repeated throughout all pages of our site.
Interestingly, there are the structured data types https://schema.org/WPHeader and http://schema.org/WPFooter which equivalently represent the header and footer of the website. It would not be correct to use this type of structured data within tags. <header> y <footer> that were, in turn, within a content section element since they were, in turn, within a content section element since they were, in turn, within a content section element since they were, in turn, within a content section element because this structured data type is equivalent only for the main <header> and <footer> of the page.
Similarly, we can use the structured data https://schema.org/SiteNavigationElement for all elements <nav>, but the only really important one is the one containing the main menu of the page, although we could also mark the footer links. For breadcrumbs it is better to use the typehttps://schema.org/BreadcrumbList while paginators Google currently detects them without even specifying which is the next and previous page, so it is not necessary to apply it to this case either.
For the <aside> tag, used for any type of content transversal to the main content (whether it is in a sidebar or not), we have the type https://schema.org/WPSideBar. On the other hand, if the aside element contains only ads, the correct thing to do would be to use the type https://schema.org/WPAdBlock instead.
For <body> we have the data type http://schema.org/WebPage. Marking the body of the document seems not very useful, but there are structured types derived from it with which we can specify what type of page it is. For example a FAQ(https://schema.org/FAQPage), a contact page (https://schema.org/ContactPage) or an “About” (https://schema.org/AboutPage), etc.
But most importantly, the https://schema.org/WebPage type has several properties that mimic the meaning of the <main> tag, useful for marking the main content of the page.
The structured data properties equivalent to the tag <main>, are:
- The property mainContentOfPage property property of https://schema.org/WebPage, which must be of type https://schema.org/WebPageElement, that is, a wildcard structured data type applicable to any type of tag.
- The type https://schema.org/WebPage also has the property mainEntity property to mark the type of structured data that represents the main content of the page (for the cases in which such content uses some specific type of structured data).
- Alternatively, and equivalently to mainEntity and https://schema.org/WebPage, within the main structured data type of the page we can use the property mainEntityOfPage property property, which will take as value the current URL. Google recommends using this property with the type https://schema.org/Article when it is the main content of the page.
We will discuss each of these points with an example below.
Finally, for the old <table> element, we also have its equivalent in the structured data type https://schema.org/Table.
General recommendations for implementing these structured data types
JSON-LD
Let’s see an example of the use of this type of structured data with JSON Linked Data which is the format recommended by Google. To do this, let’s assume that we have several blocks of ads on the same topic scattered around the page. In this case we can put them all in the same class and associate it to the WPAdBlock type using the following code in JSON+LD:
…
Contenido de la página …
<aside class="anuncio">Anuncio 1</aside>
Contenido de la página …
<aside class="anuncio">Anuncio 2</aside>
…
<script type="application/ld+json">
{
"@context": "http://schema.org/",
"@type": "WPAdBlock",
"cssSelector": ".anuncio"
}
</script>
With the cssSelector property we specify the CSS selector that assigns the current data type to the selected element (it is also possible to specify an XPath expression with the xpath property).
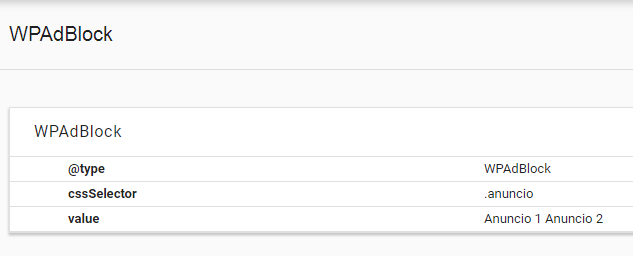
If we wanted to establish semantically independent blocks, for example, sidebars with different intentions, we would label them separately:
<body>
<main>
<aside id="sidebarInterior">Sidebar del contenido principal</aside>
</main>
<aside id="sidebarExterior">Sidebar de la web</aside>
….
<script type="application/ld+json">
{
"@context": "http://schema.org/",
"@type": "WPSidebar",
"cssSelector": "#sidebarInterior"
}
</script>
<script type="application/ld+json">
{
"@context": "http://schema.org/",
"@type": "WPSidebar",
"cssSelector": "#sidebarExterior"
}
</script>
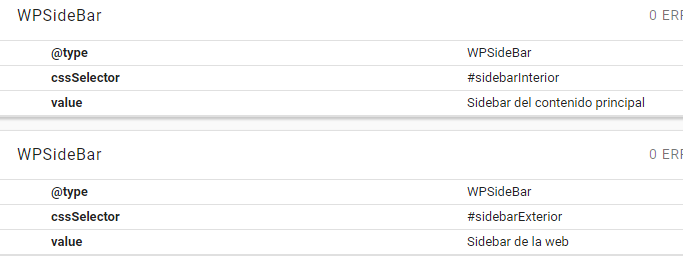
We can apply this form of implementation to all types derived from WebPageElement (they all inherit the cssSelector and xpath properties), that is: SiteNavigationElement, Table, WPAdBlock, WPFooter, WPHeader and WPSideBar. Taking care to create a single associated element for WPHeader and WPFooter.
Microdata
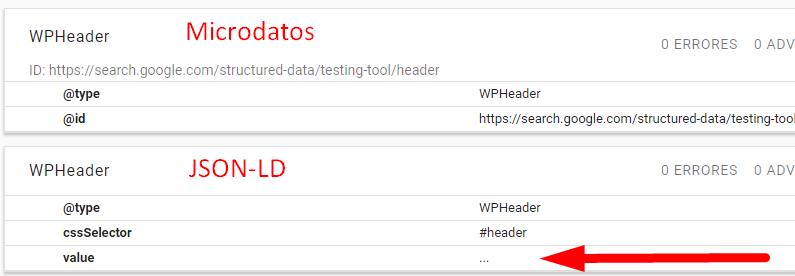
It is also valid to implement these data types with microdata as follows:
<header itemscope itemtype="https://schema.org/WPHeader" id="header"> ... </header>
This implementation is shorter for cases where the data type appears only once, as is always the case with the header and footer. It is also the way WordPress implements this structured data. However, Google’s structured data tool does not detect this type of implementation if the marked element does not carry an identifier as in the example (id=”header”). And, in addition, with this implementation the tool does not assign any value to the data type, while with JSON-LD it takes as value the content itself, so it seems more reliable the implementation with JSON-LD.
Implementation of the main content (tag <main>) with structured data
JSON-LD
Let’s see an example of how to use the mainEntityOfPage property:
<script type="application/ld+json"> "@context": "https://schema.org", "@type": "Article", "mainEntityOfPage": "https://www.humanlevel.com/articulos/indexabilidad/datos-estructurados-equivalentes-a-etiquetas-semanticas-de-html5", "author": "...", ... </script>
If we include this structured data type within the WebPage type we could express exactly the same thing in the following way with the property
mainEntity:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "WebPage",
"mainEntity": {
"@type": "Article",
"author": "...",
...
}
}
</script>
If we don’t have any structured data that we can associate with the main content of the page, we can implement it with WebPage y
mainContentOfPage in this way:
<main id="principal">
Lorem ipsum
</main>
<script type='application/ld+json'>
{
"@context": "https://schema.org",
"@type": "WebPage",
"mainContentOfPage":{
"@type": "WebPageElement",
"cssSelector": "#principal"
}
}
</script>
Microdata
Now let’s look at previous implementations with microdata:
Property mainEntityOfPage:
<main itemscope itemtype="http://schema.org/Article">
<meta itemprop="mainEntityOfPage" content="https://www.humanlevel.com/articulos/desarrollo-web/como-interpretar-schema-org-para-crear-datos-estructurados"/>
<p itemprop="author">…</p>
…
</main>
Property mainEntity:
<body itemscope itemtype="http://schema.org/WebPage">
<main itemprop="mainEntity" itemscope itemtype="http://schema.org/Article">
<p itemprop="author">…</p>
…
</main>
</body>
Property mainContentOfPage:
<body itemscope itemtype="http://schema.org/WebPage">
<main itemprop="mainContentOfPage" itemscope itemtype="http://schema.org/WebPageElement">
…
</main>
</body>
Conclusion
Structured data tags, in some cases, provide more information than HTML5 tags and Google’s robot is more likely to take them into account.when it comes to deciding how each page is organized and, above all, for to know what is the main content of it which is the part that should be positioned above the rest of the elements, so that it will always be better to have them implemented and preferably with JSON-LD.
Additional references
- HTML5
- JSON
- Google Structured Data Validation Tool
- Schema implementation validator with JSON markup
- Introduction to structured data – Google.
- What is structured data and schema.org – María Navarro.
- Structured data – questions and answers with Google.
- What are Featured Snippets – Rocío Rodríguez.
- Rich snippets to get more traffic – Jose E. Vicente.



