

Written by Ramón Saquete
Index
Understanding schema.org documentation is not a simple task.to follow it, since we must have clear abstractions that are derived from the RDF data model and which are, to a large extent, comparable to the object-oriented data modelThis subject is studied transversally with software design, object-oriented programming and object databases. But if we have the concepts clear, we will be able to create the data structure that best fits the information on our web site and the schema.org data modelwithout being limited to what appears in the examples and without losing Google’s ability to understand the semantic information they provide.
Structured data allows us to tell the Google robot the meaning of the information on our website, so that it can display enriched results, incorporate information into the knowledge graph, better interpret the information to display more relevant results and even to directly answer questions in position zero. All this should bring us more good quality traffic.
Structured data also facilitates the task of scrapers who want to extract the content of our website to incorporate it into their databases. If we have information that may be valuable to others, we should avoid this by blocking “bad” bots from the server configuration.
Previously, the basic concepts about structured data and schema.org were explained in this blog, I recommend you to read it if you don’t know what I’m talking about here. If all this is already clear to you, let’s go deeper into the subject.
Basic concepts of the schema.org data model
Next, we are going to see the concepts of class, property and instance of a class that are basic to understand how information is modeled with structured data, since schema.org is a vocabulary restricted to a series of elements, where these concepts are used to define these elements.
Class
Structured data is used to define things, and these can be any kind or type of thing, such as: people, places, products, actions such as creating or searching, creative works such as a blog or a book, events such as concerts or games, and intangible things such as offers or services. These kinds of things, here we are going to call them simply classes, although you can also find them under the name of types or entities.
Property or attribute
The way to define each of the types of information or classes is by using properties to which we can assign the value we want. For example, if we have a kind of thing “product”, inside it could have a property “name”, which could be assigned the value “cup”, and another property “color”, which could be assigned the value “red”.
Each class can have different properties and schema.org will tell us what properties each of the classes of things we can define have. That is to say, for the product class, it will tell us that it has the property “name”, the property “color” and many others that are characteristic of the products. For another type of class such as “event”, we can have other properties such as “start date” and “end date”, which would not make sense in a product.
Object or instance of a class
When we take a class and assign values to each property for which we have information, it is said that what we are doing is creating an instance of the class. For example, if we give data to a concrete product, such as the red cup in the previous example, we would say that this cup is an instance or object of the product class.
So the classes are like templates that tell us what data to fill in and, when we fill them in, we have the concrete objects or instances we want to obtain.
Relationships by object composition
At this point let me introduce nomenclature that is more typical of object-oriented programming and data modeling than of the RDF model, but which helps to simplify the explanation.
We have already seen that we can assign values to a property, but these values can be of different types that here we are going to classify in: simple types or compound types. Simple types consist of assigning a value of a specific type. For your understanding, the easiest way is to take a look at the following list, where I list all the simple data types that schema.org allows:
- Boolean value: the property can be true or false. For example, the CreativeWork class has the isAccessibleForFree property, to which we can assign the value true or false, depending on whether it is free or not.
- Date type value: a date is assigned to the property in ISO 8601 format. For example, the Product class, has the property releaseDate (release date) to which we can assign the value 2018-01-30 which is equivalent to 30/01/2018.
- Date and time type value: a date and time is assigned to the property in ISO 8601 format.
- Value of type number: it can be an integer or a number with decimals.
- Text type value: this is an arbitrary text, such as the text “cup” that I have used in a previous example for the property “name”. This text can be of the URL type.
- Time type value with the format: hh:mm:ss[Z|(+|-)hh:mm].
The properties that allow the use of values with compound types, are those to which we can assign one or several objects, of one or different classes, so that within that property we will be able to define several other properties. Let’s look at an example: the class producthas the property review (review) to which we can assign a value, which will be an instance of class Review where, in turn, we can fill in the “author” property as an instance of the class Person where we could finally fill in the property name of the person with a simple text data type. So we can say that we have a product object which is composed of a review object which in turn is composed of an author. This is what is known in the object-oriented model as a composition relationship.

By creating an instance of a product, we could navigate through all possible composition relationships and get to specify the information needed to populate almost all classes that are defined in schema.org. But this would not be correct since the idea of structured data is not to add as much information as possible, but to define for Google only that information that we are showing to the user. It is therefore not advisable to add a JSON-LD with all the information we have just to define a product.

Sometimes we can find properties marked in blue, instead of red. These are properties that have not yet been approved, so they are more likely to give us problems when it comes to Google interpreting them correctly.
Schema.org tells us the type or types of data that each property can have, although it does not specify some things that Google takes into account on its part and that are the following:
- It is not clear when we can repeat the same property several times. When this occurs, each repetition can have values with instances of different classes.
- It does not specify when a property is mandatory or recommended for Google.
- It does not say when a compound data type can be replaced by a simple text data type and Google will have no problem reading it. Although this can almost always be done, despite the fact that the definition does not specify it.
It is normal that schema.org does not specify these aspects, since it is a vocabulary defined by several search engines and, afterwards, each one can add its own restrictions on this model.
In Google’s documentation on structured data we can find some of the information we would be missing in schema.org to make a correct implementation for Google.
Therefore, to know if the structured data we are writing based on schema.org, meet Google’s requirements, we have no choice but to check it after writing it, using Google’s tool to check structured data. And if we are interested in creating structured data to generate rich snippets, we can also use the rich results tool.
Class inheritance relationships
There are properties that are the same in several classes and to avoid having to define the same property several times in each class, schema.org makes use of a concept called class inheritance. This consists in the fact that one class can inherit from another, establishing a parent and child class relationship, so that the child class inherits all the properties of the parent class. Thus, a parent class can have several daughters that share the same properties.
In schema.org the parent class par excellence is the class Thing, which defines common properties such as: name, description, url and image. As all schema.org classes inherit from Thing, their properties can be defined on any object we instantiate. Example:

Likewise, we can find classes that inherit from another one and that in turn inherit from another one and so on, so that they inherit properties from several classes, as in the example:
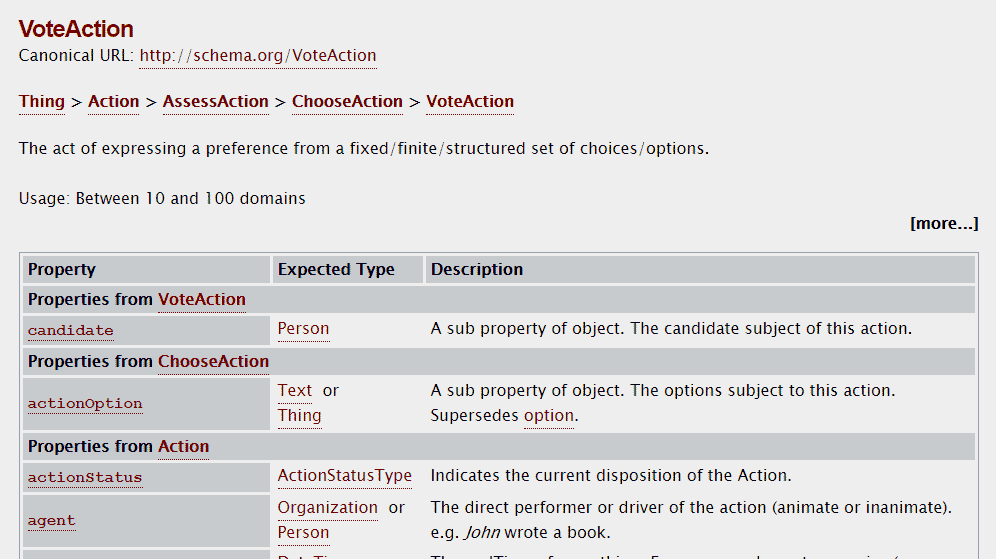
If we go to the end of the definition of a class, we can also see the child classes of the current class. In the following screenshot we see the child classes of the Product class:
In this link we have the complete class hierarchy. This resource is useful in helping us decide what kind of object class is the most appropriate for defining the information that appears on the web.
Polymorphism
Structured data allows for dynamic data types or polymorphic objects (from the Greek: that can take many forms). That objects are polymorphic means that a composite data type can take the form of any of its child classes or even a parent class. For example, the SocialMediaPosting class has the sharedContent property which is of type CreativeWork. This, on the other hand, inherits from Thing and has several child classes, such as Book, so we could assign an object of type Thing or Book to the sharedContent property (although the specification says that it is a CreativeWork) and it would not be incorrect.
This feature, which is rarely taken into account when modeling our data, offers a wide range of possibilities, allowing us to define our data in greater detail (using child classes) or, in less detail (using parent classes), if we are not clear about what they really are.
Types listed
The enumerated types are those that admit values from a list. For example, the bookFormat property of Book class, admits values of the BookFormatType class. If we go to its definition we see that it is not really a class, but an enumeration, because it inherits from Enumeration and also because enumerations usually have the word Type at the end of the name. If we go to the description, we see that we can assign the following types of enumerated values:
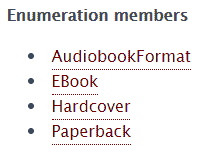
To assign an enumerated value to a property, we must write the URL that represents the value we want. For example: “bookFormat=http://schema.org/Paperback”.
There are enumerations that do not have the Type tag. These take values defined in another vocabulary different from schema.org called Good Relations
for example the type BusinessFunction type, but the operation is the same as any other enumeration.
We can also make up a text value and assign it, but then the robot will not understand the meaning of that value.
Moving from conceptual model to code
Once we have already chosen which class we are going to use, which properties we are going to fill it with and which data types we have chosen for each of the available properties, we have to convert this data modeling to one of the structured data formats understood by Google. Let’s see an example assuming that we have the following data modeling for a book object shared on a social network and we will also add the author of the book:
https://schema.org/SocialMediaPosting <= cogemos el tipo de datos publicación de red social
sharedContent = http://schema.org/Book <= aunque el tipo de datos de sharedContent es CreativeWork cogemos un tipo derivado haciendo uso del polimorfismo
name = Marketing online 2.0
isbn = 978-8441532649
bookFormat = http://schema.org/Paperback <= como bookFormat usa una clase que en realidad es una enumeración, le asignamos directamente el valor que le corresponde.
publisher = Anaya Multimedia <= según la especificación, la editorial debe ser de la clase organización o persona. Vamos a ver qué ocurre si nos saltamos la especificación y le asignamos un texto directamente.
author = https://schema.org/Person <= aquí la especificación nos dice que podemos poner una organización o una persona, así que ponemos una persona. Si fuera necesario, podríamos añadir varios autores y algunos podrían ser personas y otros organizaciones.
givenName = Fernando
familyName = Maciá
jobTitle = CEO
brand = https://schema.org/Organization
name = Human Level
There are many ways to express the conceptual data model, in the present case I have chosen this simple textual representation but I could have also represented it in UML.
If Google has this information it can answer, among other things, the question who is the author of the book Marketing online 2.0? But for that, we need to convert it to code, which can be JSON-LD, Microdata or RDFa. First we will see how to do it with microdata and then with JSON-LD, which is the format currently suggested by Google as the best option.
To transform it to microdata, we simply have to think of each class instance as being defined with “itemscope” and“itemtype=[URL de la clase en schema.org]”and properties with“itemprop=[nombre de la propiedad]”. When creating composition relationships, we will have to use “itemscope”, “itemtype” and “itemprop” at the same time, because we are declaring the type of class that we are going to use of a particular property. Below you have the above model written with microdata, so that you can compare it:
<div itemscope itemtype="https://schema.org/SocialMediaPosting">
<div itemprop="sharedContent" itemscope itemtype="http://schema.org/Book">
<p>Libro: <span itemprop="name"> Marketing online 2.0</span></p>
<p>ISBN: <span itemprop="isbn"> 978-8441532649</span></p>
<p>
Formato: Tapa blanda <link itemprop="bookFormat" href="http://schema.org/Paperback" />
</p>
<!-- cuando que tenemos que definir una propiedad que no aparece igual al usuario y tiene un tipo de datos URL, se debe usar la etiqueta link con el atributo href, si es del tipo de datos Text, usaremos la etiqueta meta con el atributo content !-->
<p>Editorial: <span itemprop="publisher">Anaya Multimedia</span></p>
<div itemprop="author" itemscope itemtype="https://schema.org/Person">
<p><span itemprop="givenName">Fernando</span>
<span itemprop=" familyName">Maciá</span>
</p>
<p>
<span itemprop="jobTitle">CEO</span> de
<span itemprop="brand" itemscope itemtype="https://schema.org/Organization">
<span itemprop="name">Human Level</span>
</span>
</p>
</div>
</div>
</div>
If we run this code in Google’s structured data tool, we don’t get any errors, just a couple of recommended property warnings, so Google would be able to interpret it correctly.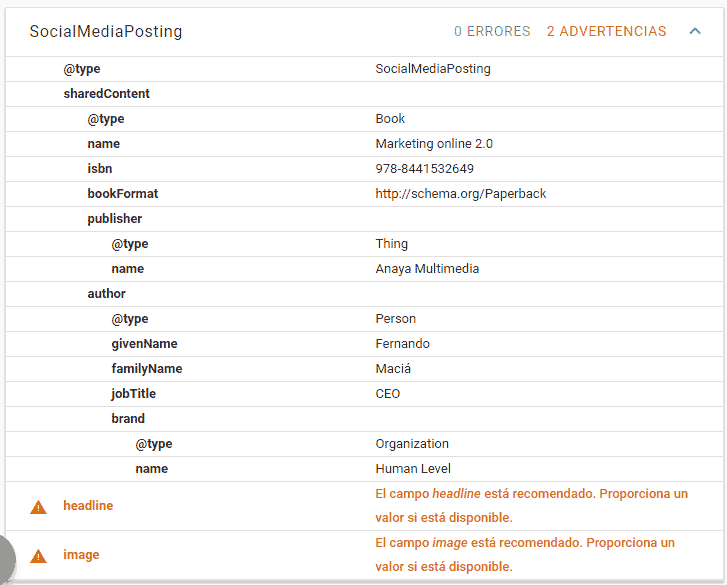
Another thing to take into account in this example is that the property Publisher, according to schema.org should be of the class Organization or Person, however, when assigning a simple type value directly, the tool to check structured data does not give us an error, but assigns the class Thing, making use of polymorphism without realizing it. So Google doesn’t know if it’s an organization or a person but it knows it’s the publisher. This is useful to know, for when we ourselves are not sure what meaning to give to some property.
With JSON-LD the code is simpler, here is how the code equivalent to the one above would look like:
<script type="application/ld+json">
{
"@context":"https://schema.org/",
"@type":"SocialMediaPosting",
"sharedContent":{
"@type":"Book",
"name":"Marketing online 2.0",
"isbn":"978-8441532649",
"bookFormat": "Paperback",
"publisher":"Anaya Multimedia",
"author":{
"@type":"Person",
"givenName":"Fernando",
"familyName":"Maciá",
"jobTitle":"CEO",
"brand":{
"@type": "Organization",
"name": "Human Level"
}
}
}
}
</script>
Here we define the name space of the vocabulary at the beginning “https://schema.org/”, so there is no need to repeat it later in the rest of the code. It would also be valid to put “http://schema.org”, even if the page is under HTTPS, since this is not a link, but a way of saying that all the classes we are going to use belong to schema.org.. Namespaces are used in RDF to prevent two classes with the same name and from different vocabularies from getting confused, but here, for the time being, we will always have only one namespace.
If in some property we have several values, in microdata we would simply repeat it, but in JSON-LD we put it with square brackets. Suppose we want to define a book with several publishers and several authors, let’s see how it would look with microdata and its equivalent JSON-LD:
<div itemscope itemtype="http://schema.org/Book">
<p>Editorial: <span itemprop="publisher">editorial1</span>,
<span itemprop="publisher">editorial2</span></p>
<div itemprop="author" itemscope itemtype="https://schema.org/Person" >
<p><span itemprop="name"> autor1</span></p>
</div>
<div itemprop="author" itemscope itemtype="https://schema.org/Person" >
<p><span itemprop="name"> autor2</span></p>
</div>
</div>
<script type="application/ld+json">
{
"@context":"https://schema.org/",
"@type":"Book",
"publisher": ["editorial1", "editorial2"],
"author":[
{
"@type":"Person",
"name":"autor1"
},
{
"@type":"Person",
"name":"autor2"
}]
}
</script>
Conclusions
Structured data (or semi-structured as it should technically be called), is difficult to model, but would be even more so if we were to use other vocabularies defined with RDF or OWL. I am referring to semantic web vocabularies, such as FOAF, SIOC, SKOS or Dublin Core, since they contain more complicated relationships than those we have already seen in the vocabulary proposed by the search engines in schema.org. So by applying schema.org correctly, we will have it easier and, with Google’s tools, we can be sure that the robot will know how to interpret the meaning of our data.
Additional references
- Structured data equivalent to5 semantic tags – Ramón Saquete.
- HTML5
- JSON
- Google Structured Data Validation Tool
- Schema implementation validator with JSON markup
- Introduction to structured data – Google.
- What is structured data and schema.org – María Navarro.
- Structured data – questions and answers with Google.
- What are Featured Snippets – Rocío Rodríguez.
- Rich snippets to get more traffic – Jose E. Vicente.



