

Written by Ramón Saquete
Index
- When do we want links that are recognizable by Google?
- When will we want links unrecognizable by Google?
- How not to apply Link Sculpting?
- How to apply Link Sculpting without applying rel=”nofollow”?
- Is it black hat SEO to use buttons that behave like links?
- Is it also possible to avoid URL discovery?
- Conclusion
Knowing the answer to this question is very useful to know if the indexable contents are crawlable and to apply the Link Sculpting technique. Understanding it helps to improve the positioning and indexing of our web pages. Let’s see why.
Next, we will differentiate between two types of links or hyperlinks: those that are detected by Google and those that are not. Its behavior towards the user will remain the same, i.e., to take the user to another page, but will have different effects on positioning. We will choose one or the other depending on the situation.
When do we want links that are recognizable by Google?
We will want crawlable links when the URLs they point to are interesting for positioning, are indexable and, therefore, we want to transmit part of the popularity flow from the page where they are linked to.
When will we want links unrecognizable by Google?
Sometimes, we have useful pages for users, such as sorting filters or price ranges, that do not add value to the positioning of the site. If we have done our SEO homework, we will avoid indexing those pages by adding the robots meta tag with noindex value.
However, other problems remain and one of them is exactly what Link Sculpting is trying to solve. It is the one related to the way in which Google distributes equitably the popularity score or PageRank of the page among all outgoing links. If these links include pages that are not interested in positioning, the result is that the rest of them will score less.
Another problem that Link Sculpting is trying to solve, is the linking to indexable pages to which we do not want to pass more PageRankfor not to give them more importance than they already havewhen they are already linked from other parts of the web or from the page itself and have only been added for usability.
Therefore, Link Sculpting consists in choosing certain links to make them unrecognizable to Google and thus force the PageRank to flow towards the links we are interested in.
Although it is not often named these days and seems somewhat outdated, Google still uses PageRank internally, as Gary Illyes states in this December 10, 2020 podcast.
How not to apply Link Sculpting?
Links with the rel=”nofollow” attribute are not suitable for Link Sculpting. The attribute for user-generated content (rel=”ugc”) and the attribute for ad and sponsor content (rel=”sponsored”) are also useless, as they have the same effect as rel=”nofollow”.
Therefore, the only way to do Link Sculpting is to add links that are not really taken into account as such.
How to apply Link Sculpting without applying rel=”nofollow”?
You can corroborate this information both at the 2018 Google I/O annual developer conference and in the following tweets from John Mueller:
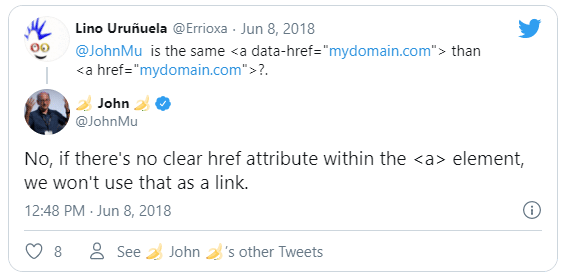
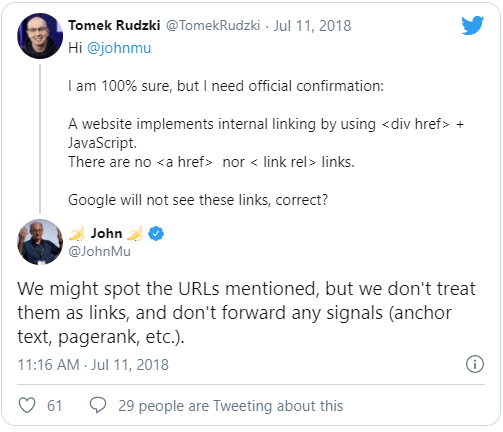
Therefore, if we have a tag < a > without href attribute or a label <button>, <span>, <div> or any other that requires JavaScript to send the user to the requested page by clicking on it will not count as a link and we will not lose PageRank.
By this definition, let’s look at examples of what Google considers a link and what it doesn’t. Some are from the 2018 Google I/O, others from this 2020 WMConf talk and others “homegrown”.
Links that really are
<a href="/enlace-real">Pasa PageRank</a>
Normal link with its tag < to > and href attribute.
<a href="/enlace-real" onclick="funcionDeJavaScript('/enlace-real')">Pasa PageRank</a>Link with <tag to> and href attribute. The additional elements do not cause the code to generate problems.
<a href="/enlace-bueno#fragmento">Pasa PageRank a la URL sin fragmento</a>
The snippets (the # part of the URL) are ignored by the spiders, so if they change the content of the landing page, they would not be indexable, but their links would pass PageRank to the main URL without the snippet. Only rarely are snippets displayed in search results when they are used in a table of contents as an anchor to a part of the document.
False links: are implementations that behave as links, although they are not.
The following examples involve the use of JavaScript to change pages. We assume that we have a function “changePage” that sends the user to the URL passed as a parameter. This function can be implemented as follows (if you don’t know JavaScript you can skip it, as it is not necessary to understand what is important):
<script>
function cambiarPagina(enlace){
window.location = enlace;
}
</script>
Or if we want to open the link in a new tab or page, we would use the following function instead:
<script>
function cambiarPagina(enlace){
var win = window.open(enlace, '_blank');
win.focus();
}
</script>
These are not the only ways to implement this function. For example, in a SPA (Single Page Application) we would make a fetch or AJAX request to retrieve the new content and change the URL with the history API to JavaScript, without having to reload the page.
Let’s see some examples of false links using the above function:
<span onclick="cambiarPagina('/enlace-falso')"> No pasa PageRank </span>It is not considered a link because it does not use the tag < a >. Instead of <span> we could have used <button> or any other tag.
<a onclick="cambiarPagina('/enlace-falso')"> No pasa PageRank </a>It is not considered a link because it has no href attribute.
<a data-href="/enlace-falso" onclick="cambiarPagina(this.dataset.href)"> No pasa PageRank </a>
It is not considered a link because it also has no href attribute.
<div href="/enlace-falso" onclick="cambiarPagina(this.getAttribute('href'))"> No pasa PageRank </div>In this case there is an href attribute but it is not an anchor tag (< to >), so it does not pass PageRank either.
<a href="javascript:cambiarPagina('/enlace-falso')">No debería pasar PageRank</a>This link is tagged <a> and href attribute but does not have a URL to pass PageRank to. In this case, although there is no clear information about it, it is possible that the source page does provide PageRank, and therefore it is better to use one of the above implementations when we want to fake links.
If in any of the above examples, when loading the page, we transform with JavaScript the link code to one of the implementations of a real link (with a valid URL, with its href attribute and tag <a>), then it will be considered a link and will pass PageRank, provided that Google successfully executes the corresponding JavaScript code in the second indexing pass.
We must remember that if we find any of the above examples without the onClick attribute, they will still not be links, since the onClick event can be assigned from an external JavaScript without using that attribute. If this event does not exist in the HTML or in the external JavaScript anyway, nothing will happen when clicking on them. In other words, they will still not be links and will not function as such.
Currently Google does not specify whether it can be considered black hat SEO to use JavaScript buttons or links instead of using a normal link.
If we consider that no we are visually hiding links (which would be considered black hat SEO) but by placing buttons that are visible and behave as such, need not be seen as a fraudulent attempt to manipulate the results, since these buttons are used to link to pages or functionalities whose indexing would not provide any benefit to users and worsen the quality of search engine results. This leads us to believe that there is no reason why applying these techniques should ever be considered black hat SEO.
Is it also possible to avoid URL discovery?
Using unrecognizable links does not prevent crawling, only the loss of PageRank for the other links on the page where they are located, since Google can still discover the URL (e.g. if it is included in the Sitemap file by mistake or through external links). If discovered, it will include it in the crawl queue and index it as an orphaned or unlinked URL (as long as it is not blocked from indexing with the “robots” meta-tag, with value “noindex”).
To prevent the discovery of a URL within our own site, we can use many hiding and obfuscation techniques. The more we use, the more difficult it will be for a spider to detect it and the more complicated the development will be. However, it is always possible that a user may copy the URL somewhere and share it, so the only 100% effective way to prevent the discovery of a URL is that it does not exist and this is implemented AJAX loading the content that would display the link, without changing URLs.
If, however, we want to avoid the discovery of the URL on our own website, even if Google can discover it later by other means, we will apply the following techniques:
- When clicked, the URL to be hidden is retrieved with an AJAX or Fetch request . Since Google does not execute the clicks, it will not see the URL. If instead of AJAX, we send a message with a WebSocket, even better, because Google is not able to index this technology in any way.
- If we have chosen to use an AJAX request, for further concealment, we could block the URL of the request with the robots.txt file (without blocking requests needed to render the page). We would also add the HTTP header parameter “X-robots-tag:noindex” and send the request via the POST method instead of GET, since Google only crawls GET requests.
- If in addition, from the response to the AJAX request or WS message, we return the obfuscated URL with some kind of encoding or encryption, even better.
- Finally, we obfuscate the JavaScript that performs all of the above, so that the code is indecipherable without executing it.
Let’s look at a fairly simple implementation example with the Fetch API. The following code should be in an external JS file:
function cambiarPagina(id){
fetch('/get-url-from-id.php', {
method: 'POST',
body: id
})
.then(response => response.text())
.then(function(texto) {
window.location = atob(texto);
});
}
In this example, the Fetch request would return the URL that corresponds in the database to the identifier passed as a parameter. This URL would be base64 encoded. It could be, for example, for URL identifier 31: “aHR0cHM6Ly93d3cuaHVtYW5sZXZlbC5jb20v”. Then, this string would be decoded by the “atob” function and the URL “https://www.humanlevel.com/” would be left, to which we will redirect the user.
Finally, using a JavaScript obfuscation tool, the code would look like this:
<script>
var _0x31d5=['then','location','/get-url-from-id.php','POST','text'];(function(_0x49ef13,_0x340068){var _0x31d5a4=function(_0x1edee6){while(--_0x1edee6){_0x49ef13['push'](_0x49ef13['shift']());}};_0x31d5a4(++_0x340068);}(_0x31d5,0xdb));var _0x1ede=function(_0x49ef13,_0x340068){_0x49ef13=_0x49ef13-0x11e;var _0x31d5a4=_0x31d5[_0x49ef13];return _0x31d5a4;};function cambiarPagina(_0x476133){var _0x1333d0=_0x1ede;fetch(_0x1333d0(0x121),{'method':_0x1333d0(0x122),'body':_0x476133})[_0x1333d0(0x11f)](_0x168e00=>_0x168e00[_0x1333d0(0x11e)]())['then'](function(_0x57eaf4){var _0x5e0eb6=_0x1333d0;window[_0x5e0eb6(0x120)]=atob(_0x57eaf4);});}
</script>
The HTML of the button could be the following (although it would be even better to bind the event from the JavaScript, let’s leave it like this for simplicity’s sake):
<button onclick="cambiarPagina(31);">URL indetectable</button>
Obfuscation can be as complicated as you want, but the more obfuscated the code is, the harder it is to maintain, so unless you are participating in a JavaScript obfuscation competition, I don’t recommend going too far if you choose this route.
Conclusion
You already know how to detect links that pass PageRank and are indexable and links that are not, in order to validate if you are using the correct implementation in each case and change it accordingly, provided that you have previously made the appropriate SEO decisions to establish in which of these situations it is convenient to use each one.



