

Written by Ramón Saquete
Index
After the appearance of AJAX, or, as it is now called, API Fetch, the frameworks SPA (Single Page Application) that by using Fetch requests generate part of the on the client, which prevents the spiders from being able to index correctly all the content and, above all, track it because, in addition, this type of websites can be implemented without trackable links through the use of URLs with fragments (use of #) or directly without using URLs in the links (which only work for the user when clicking on them).
With the term “SPA”, the term Multiple Page Application (MPA) is used to refer to the classic frameworks that generate all the HTML on the server, which is what the spiders need to be able to index and crawl the pages without problems.
 There are many, many SPA-type frameworks: on Google’s side we have Angular (formerly AngularJS), on Facebook’s side, React and countless more open source ones like Vue, Meteor, Lazo, Rendr, Ember, Aurelia, Backbone, Knockout, Mercury, etc. These frameworks could initially only be executed on the client, but we will see later that the best solution is not to do so.
There are many, many SPA-type frameworks: on Google’s side we have Angular (formerly AngularJS), on Facebook’s side, React and countless more open source ones like Vue, Meteor, Lazo, Rendr, Ember, Aurelia, Backbone, Knockout, Mercury, etc. These frameworks could initially only be executed on the client, but we will see later that the best solution is not to do so.

How does a SPA framework work without Universal JavaScript?
As I have already mentioned, the SPA frameworks are based on the use of the Fetch API, because work by loading in the browser together with a shell containing the parts that do not change during browsing in addition to a series of HTML templates, which will be filled with the responses of the Fetch requests that will be sent to the server. It is necessary to differentiate how this occurs in the first request to the web and in the navigation through the links once it has already been loaded, since the operation is different:
- First request: the Shell is sent over the network. Then, with one or more Fetch requests (which also travel through the network), the data to generate the HTML of the main content of the page is obtained. As a result, the first load is slowed down by the network requests, which usually take the longest time. Therefore, in a first load, it is faster to send all the HTML generated on the server in a single request, as the MPA frameworks do.
- Loading of the following pages after the first request: in SPA frameworks the loading is much smoother and faster, since the entire HTML does not have to be generated. In addition, transitions or loading bars can be added between the display of one page and another, which gives a feeling of greater speed. However, we have an additional major problem: when generating part of the HTML on the client with JavaScript after a Fetch request that is also done with JavaScript, spiders cannot index these pages especially when the user can reach pages where the spider does not even have a URL to index.
How did you try to make a SPA framework indexable before Universal JavaScript?
Initially, the idea of using a tool on the server that acts as a browser comes up. This browser on the server would go into action at the request of a spider. It would work as follows: first we would detect that the request comes from the spider by filtering it by the spider’s user agent (for example “Googlebot”) and then we pass it to a kind of browser inside the server itself. This, in turn, would request that URL from the web service, also within the same server. Then, when retrieving the response of the request to the web service, it would execute the JavaScript, which would make the Fetch requests and generate the entire HTML, so that we can send it back to the spider and cache it. Thus, the next request from the spider to that URL will be returned from the cache and, therefore, will work faster.
To do this well, in the links that launch Fetch requests, there must be friendly URLs (no obsolete techniques such as URLs with hashbang “#!” should be used) and when the user clicks on a link, the developer must paint the same URL with JavaScript, using the history API. This way we ensure that the user can share and save that URL in favorites. This URL should return the full page when requested by a spider on the server.
This is not a good technique, because it presents the following problems:
- We are cloacking, so our website will only be indexed by the spiders we have filtered.
- If we do not have the HTML cached the spider will perceive that the loading time is very slow.
- If we want the spider to perceive a faster loading time, we will have to generate a cache with the HTML of all URLS, which implies having a cache invalidation policy. This may not be feasible for the following reasons:
- That the information must be continuously updated.
- The time to generate the entire cache is unbearable.
- We do not have space on the server to store all the pages in the cache.
- We do not have the processing capacity to generate the cache and keep the page online at the same time.
- Note that the cache invalidation problem is very complex, since the cache must be updated when something in the database changes. However, in the cache, it is not easy to delete exactly the data that has been updated, because as it is not a database, but something simpler and faster, we cannot easily select what we want to regenerate, so strategies are followed that delete more than necessary or leave inconsistent data. Depending on the case, these problems may preclude opting for this solution.
- Finally: the tools that act as a browser on the server are paid (Prerender.io, SEO4Ajax, Brombone,…).
How to make a SPA framework indexable with Universal JavaScript?
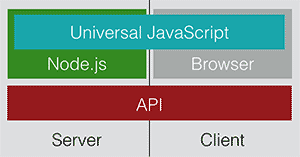
The idea of Universal JavaScript or isomorphic JavaScript (as it was initially called), is based on Facebook’s SPA framework (React), and consists of using a Universal API that underneath use Client browser JavaScript APIs or server JavaScript APIs with Node.JS, depending on whether this universal API runs on the client or on the server, respectively. This way, when writing JavaScript code using this API, we will be able to run it on both the client and the server. If we couple this with a SPA framework that is intended to run only on the client, we have a universal framework that can run on both the client and the server as follows:
First of all, we must take into account that we can distinguish between three different types of JavaScript code in our web development, depending on where it is going to be executed:
- Only on the customer.
- Only on the server, although this JavaScript could be replaced by any server language such as PHP.
- Both on the client and on the server (Universal JavaScript).
If we use JavaScript in the block of code that runs only on the server, we will be using this language for all three cases and, therefore, we are said to be using a Full-Stack framework.
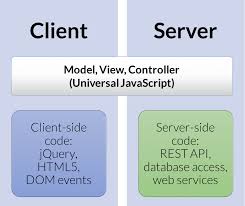
As when we did not have Universal JavaScript, the behavior will be different for the first and subsequent requests:
- First request: regardless of whether the request comes from a spider or a user, the entire HTML will be generated on the server making use of the Universal JavaScript block that launches Fetch requests to the JavaScript running only on the server. The operation is similar to when Universal JavaScript is not used, but with the difference that the Fetch requests are made from the server to itself and not from the client, saving the initial transfer of requests over the network.
- Loading of the following pages after the first request: if it is a user and he clicks on a link, the JavaScript running only on the client will intercept the click and pass the request to the Universal JavaScript (the same as in the previous point). It will make a Fetch request to the JavaScript that runs only on the server, with the requested URL, and when retrieving the data from the server, it will display the new page to the user. In this case, the Fetch request goes from the client to the server, preventing the entire page from reloading.
In this way we have pages that work fast both in the first load and during the subsequent navigation and the spiders have no problems indexing them, because for these pages the complete page will always be generated on the server without the need for cloacking.
Conclusion
If a development company offers you a web site with Angular, React or other SPA development framework, make sure they know Universal JavaScript and that they have a project that is indexing correctly, as they may not know of its existence or not know how to use it, since it is not uncommon for them to use an older version of the framework that does not have Universal JavaScript. In Angular, for example, it initially appeared as a standalone add-on called Universal Angular and was later incorporated into the framework. On the other hand, if they know about it, there will be no problem with the indexability of the site.
Another story is whether they know JavaScript, frameworks and the issues involved in this type of website well enough to make the code maintainable and bugs easy to test and fix. A good indication that they know what they are dealing with may be to know if they use other frameworks, in addition to those already mentioned, for manage application states, such as Redux or Ngrx. This is a task that, without this type of additional frameworks, can result in code with poor maintainability.



