


Tabla de contenidos
- Qué son los grandes modelos de lenguage (LLMs) como ChatGPT
- Qué es un Knowledge Graph y en qué se diferencia de los LLMs
- ¿Qué es el Retrieval-Augmented Generation (RAG)?
- Anatomía de los resultados en el panel de Google SGE
- ¿Cómo afecta Google SGE a los resultados tradicionales?
- Qué tipo de consultas no resuelve Google SGE: YMYL
- ¿Cómo podría impactar Google SGE en el SEO?
- Cómo podemos prepararnos para Google SGE
- ¿Debemos bloquear las IAs?
- Algunos ejemplos de Google SGE
- Conclusión
- Referencias adicionales
- Mi presentación Impacto de Google SGE para Enpresa Digitala
Aunque Google SGE aún no está disponible en la Unión Europea, en Human Level hemos querido adelantarnos e investigar todo lo posible esta novedad para poder dar respuesta a nuestros clientes sobre el impacto que puede tener en sus negocios. Hemos analizado cientos de búsquedas y te contamos a continuación nuestras impresiones: qué es Google SGE, qué impacto podría tener sobre los hábitos de búsqueda de los usuarios, sobre el papel de Google como generador de tráfico orgánico de calidad y sobre la propia forma en que hacemos SEO. Es un poquito largo, pero te advierto que vale la pena. ¿Me acompañas?
Google SGE (Search Generative Experience o Experiencia de Búsqueda Generativa) es una nueva forma de responder a las búsquedas de los usuarios combinando la potencia de los grandes modelos de lenguaje (LLM) como chatGPT con la capacidad de rastreo en tiempo real de un buscador como Google, para así mejorar la fiabilidad de las respuestas y citar los documentos que la avalan.
Cathy Edwards fue la encargada de presentar Google SGE durante la conferencia Google I/O del pasado 10 de mayo y hasta la semana pasada solo estaba disponible previa autorización de ingreso en el programa de Google Search Labs en Estados Unidos, India y Japón. Desde el pasado 9 de noviembre, sin embargo, se ha desplegado a 120 países, aunque Canadá o la Unión Europea no están incluidos, probablemente debido a su legislación más restrictiva en materia de protección de datos y regulación de los sistemas que emplean Inteligencia Artificial (IA).
Para acceder a los resultados de Google SGE desde un país no incluido todavía en el programa se requiere contar con un perfil de Google autenticado mediante un teléfono móvil local de alguno de esos países y navegar con un IP de acceso consistente con esta autenticación.
Google SGE involucra dos conceptos clave en su desarrollo:
- Los grandes modelos de lenguaje (Large Language Models o LLMs).
- La generación aumentada por recuperación (Retrieval-Augmented Generation o RAG).
Veamos en qué consisten.
Qué son los grandes modelos de lenguage (LLMs) como ChatGPT
Un LLM (Large Language Model – gran modelo de lenguaje) es un tipo de modelo de inteligencia artificial diseñado para entender y generar lenguaje humano de forma automática. Básicamente, funciona como un cerebro artificial que procesa grandes cantidades de texto para aprender patrones y estructuras del lenguaje, y luego puede usar ese conocimiento para predecir y generar texto nuevo.
ChatGPT es un tipo específico de LLM llamado GPT (Generative Pre-trained Transformer) que fue desarrollado por OpenAI. GPT es un modelo de lenguaje basado en la arquitectura Transformer, creada originalmente por Google, que utiliza redes neuronales para procesar grandes cantidades de texto y aprender a generar texto nuevo.
Cómo se entrenan y aprenden los LLMs
ChatGPT aprende a partir del análisis e identificación de patrones en grandes conjuntos de datos (dataset) facilitados por terceras partes o disponibles públicamente online. Uno de los artículos que mejor explica cómo funciona la inteligencia artificial generativa es este de Financial Times.
Los conjuntos de datos utilizados para entrenar GPT 3.5 son:
- Common Crawl: es un cojunto de datos creado por una entidad sin ánimo de lucro homónima. Common Crawl emplea un bot cuyo user-agent es CCbot/2.0 para rastrear contenido públicamente accesible online. CCbot respeta las directrices establecidas en el archivo robots.txt, así como en la meta CCbot, ofreciendo una vía para bloquear el rastreo o que pueda seguir los enlaces de una página. No obstante, bloquear CCbot ahora no significa que los contenidos rastreados anteriormente y que ya forman parte de su conjunto de datos vayan a ser eliminados. Solo estaríamos impidiendo el rastreo de nuevo contenido. Es importante destacar que los conjuntos de datos como Common Crawl son empleados por empresas publicitarias para categorizar contenidos y segmentar la publicidad que aparece en ellos. Bloquear el acceso de CCBot podría tener un impacto sobre algunas redes publicitarias.
- WebText2: es un conjunto de datos propiedad de OpenAI obtenidos a partir del rastreo de sitios Web con más de 3 votos en Reddit, en el supuesto que el contenido de estos sitios es confiable y de calidad. La versión original de WebText contenía alrededor de 15 billones de tokens (unidad mínima de información) mientras que WebText2 es una versión extendida con 19 billones de tokens y es la que OpenAI ha utilizado para entrenar GPT 3 y GPT 3.5. El conjunto de datos WebText2 es privado y no está públicamente accesible. No obstante, existe una versión OpenWebText2 públicamente accesible donde podemos consultar las URLs de origen de los datos. No se conoce qué user-agent utilliza WebText, de forma que no se puede bloquear su acceso via robots.txt o a nivel de servidor.
- Books1
- Books2
- Wikipedia
De ellos, solo Common Crawl y Wikipedia tienen su origen directo en el rastreo de datos online.
GPTBot es el User-agent de ChatGPT y si no queremos que utilice nuestro contenido como datos de entrenamiento se puede bloquear desde robots.txt.
Actualmente, ChatGPT no puede rastrear los contenidos online. Sus respuestas se basan en el entrenamiento a partir de conjuntos de datos recopilados hasta una fecha determinada. Sin embargo, ya existen plug-in para navegadores que permiten a sus modelos leer información directamente de sitios online, así como otras aplicaciones lanzadas recientemente.
El modelo de ChatGPT implementado por Bing utiliza la información obtenida a partir de una búsqueda “tradicional” para resumir, sintetizar y extraer la información más valiosa a partir del contenido encontrado en esos resultados.
Los LLMs fragmentan los contenidos rastreados en estos conjuntos de datos en unidades básicas de información o tokens, que puede ser codificada. A continuación observan cuándo esas unidades se encuentran más o menos cerca de otras analizando grandes volúmenes de texto. El proceso genera un vector que almacena las probabilidades de encontrar esa palabra más o menos cerca de otras. Por último, los Transformers procesan no palabras aisladas, sino frases, párrafos o incluso artículos enteros analizando las relaciones entre todas sus partes. Al tener en cuenta el contexto, pueden comprender mejor el significado de cada palabra.
Antes de seguir avanzando, nos resultará también útil entender que es un grafo de conocimiento o Knowledge Graph y en qué se diferencian de estos grandes modelos de lenguaje (LLMs).
Qué es un Knowledge Graph y en qué se diferencia de los LLMs
Los grafos de conocimiento son un tipo de grafo. Los grafos son estructuras simples que utilizan nodos (o vértices) conectados por relaciones (o aristas) para crear modelos de alta fidelidad de un dominio.
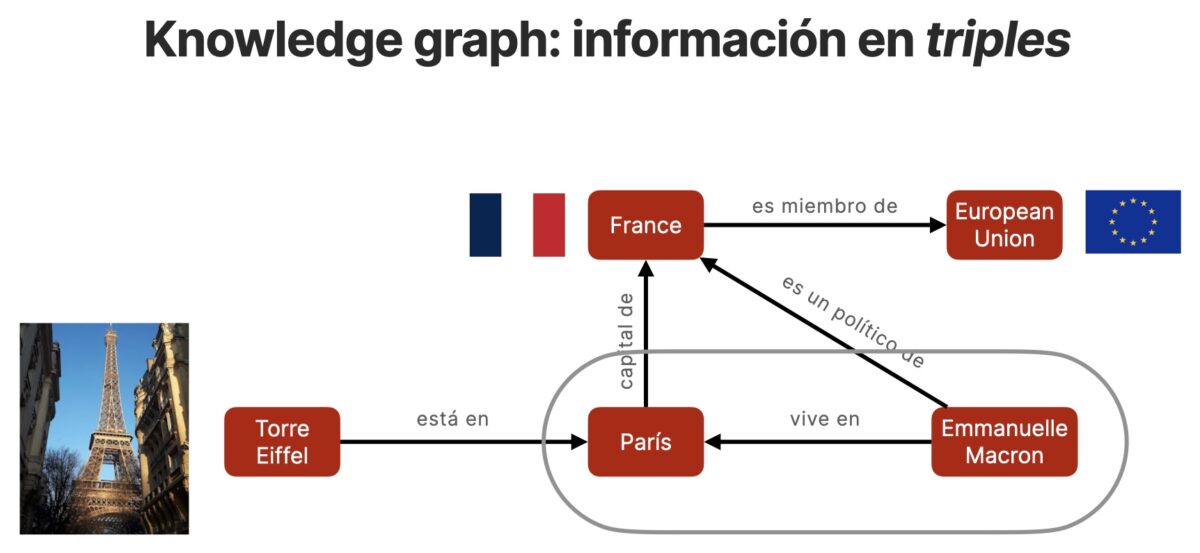
Google presentó los resultados con formato Knowledge Graph en mayo de 2012 y gradualmente ha ido incrementando el tipo y cantidad de entidades para las cuales devuelve este tipo de resultados.
Si comparamos en paralelo los resultados que obtenemos de un gran modelo de lenguaje como ChatGPT de los que nos devuelve un grafo de conocimiento de Google podremos advertir las principales diferencias entre estas dos formas de almacenar y recuperar información:
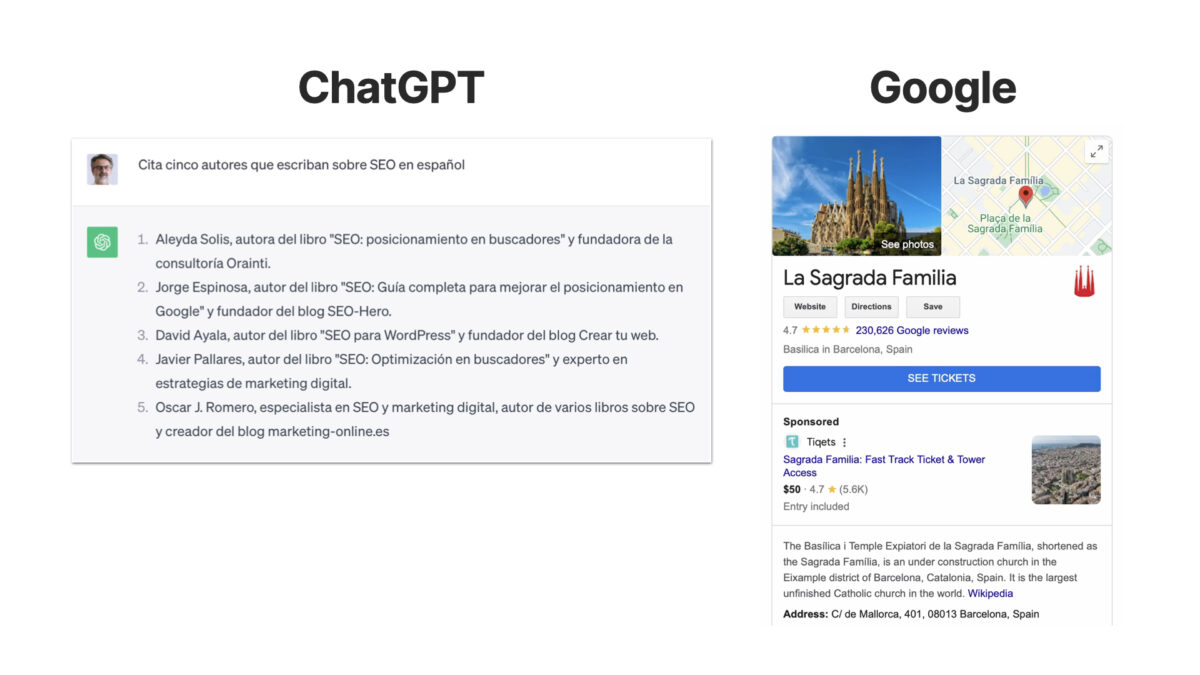
Algunas ventajas del knowledge graph respecto a un LLM:
- Información general vs. información específica: por un lado, a chatGPT y modelos similares se les supone, en principio, un conocimiento genérico y global, mientras que el knowledge graph de Google solo se presenta para búsquedas informacionales de entidades que Google ya tiene reconocidas y cuyas relaciones están basadas en datos. Tendríamos por un lado un conocimiento implícito por parte de los LLMs mientras que los knowledge graph presentan un conocimiento más estructurado.
- Alucinaciones vs. exactitud y fiabilidad: los LLMs son modelos de lenguaje predictivos que generan contenido a partir de una instrucción (prompt) de partida pero cuya información puede ser totalmente errónea (en la imagen anterior, ninguno de los libros referenciados por ChatGPT existen realmente, si bien es cierto que tanto Aleyda Solís como David Ayala han escrito otros libros de temática relacionada). Por el contrario, la información presentada en el grafo de conocimiento de Google es generalmente fiable y está avalada por los sitios web origen de la información enlazados desde la misma.
- Caja negra vs. modelo interpretable: los grandes modelos de lenguaje aplican redes neuronales que «aprenden» de una forma difícil de predecir y controlar, funcionando como una «caja negra» mientras que la información estructurada del knowledge graph es fácil de interpretar, validar y predecir.
- Falta de actualización vs. conocimiento en progresión permanente: los grandes modelos de lenguaje se entrenan sobre conjuntos de datos existentes en un momento dado por lo que carecen de la posibilidad de actualizar su base de conocimiento en tiempo real mientras que la información reflejada por el knowledge graph puede estar permanentemente actualizada.
Aunque los LLM aventajan a los knowledge graph también en algunos aspectos:
- Conocimiento general vs. datos incompletos: en principio, podemos cuestionar a un LLM sobre cualquier temática, mientras que Google solo presenta el panel de knowledge graph para un número limitado de entidades.
- Comprensión del lenguaje natural: por su propio funcionamiento, los grandes modelos de lenguaje son capaces de responder a cuestiones planteadas en lenguaje natural, incluso ajustando su respuesta a repreguntas del usuario. Por el contrario, un grafo de conocimiento solo presenta la información disponible para la entidad identificada, pero no da la opción al usuario de plantear preguntas de seguimiento.
Una vez vistas las fortalezas y debilidades de los grandes modelos de lenguaje (LLMs) respecto a otras formas de almacenamiento y recuperación de la información como los grafos de conocimiento, vamos a ver qué hace diferente a Google SGE de chatGPT y por qué esta diferencia es fundamental para:
- Salvaguardar la reputación de Google como fuente de referencia de información fiable, minimizando la posibilidad de las alucinaciones propias de los LLMs.
- Introducir la inteligencia artificial generativa en los resultados de búsqueda respetando los derechos de propiedad intelectual y las reivindicaciones de los creadores de contenido.
- Evitar perder protagonismo como fuente de tráfico orgánico de calidad para los sitios Web.
- Mantener intacto su propio modelo de monetización (Google Ads).
Todo ello tiene que ver con la generación aumentada por recuperación o RAG.
¿Qué es el Retrieval-Augmented Generation (RAG)?
La generación aumentada por recuperación (RAG) es un paradigma en el que se recopilan documentos y/o datos relevantes procedentes de un grafo del conocimiento a partir de la consulta de un usuario. Estos datos se añaden como pistas o datos fiables para crear automáticamente un prompt más preciso. De esa forma, mejora la exactitud y fiabilidad de la respuesta del modelo de lenguaje (LLM).
Google ha aplicado a SGE este paradigma probablemente combinando distintos modelos propios como REALM, presentado en febrero de 2020, RETRO, presentado dos años más tarde, RARR, publicado en mayo de 2023 o FreshLLMs, publicado en un paper de octubre de 2023.
Las principales ventajas de aplicar el paradigma RAG son:
- Mejora la precisión de la respuesta y evita en gran medida las alucinaciones.
- Permite la atribución de la información facilitada a sus fuentes originales, así como enlazarlas para facilitar que el usuario pueda profundizar en los aspectos de la búsqueda que desee.
- Evita la limitación de los LLMs a la fecha última de actualización de los conjuntos de datos (dataset) que emplean como datos de entrenamiento.
Anatomía de los resultados en el panel de Google SGE
Los resultados que devuelve Google SGE adoptan distintas disposiciones en función de la intención de búsqueda. A continuación mostramos cómo es este resultado para una búsqueda informacional:

Esta disposición, además, ha ido evolucionando desde que fue presentado. Inicialmente no incluía enlaces a los sitios Web de referencia, lo que desencadenó una gran protesta por parte de los creadores de contenido. También se mostraba sombreado claramente para diferenciarlo de los resultados orgánicos tradicionales y, para aquellas búsquedas en las que sí aparecía, lo hacía totalmente desplegado de inicio, ocupando la práctica totalidad del above-the-fold.
A lo largo de los meses que lleva funcionando, hemos visto cómo Google ha incluido los carruseles secundarios de resultados accesibles mediante enlaces que los despliegan bajo cada párrafo. También ha ido suavizando el sombreado inicial hasta hacerlo casi imperceptible y, por último, muestra el panel solo parcialmente desplegado y es el usuario quien decide si terminar de extenderlo o no.
Siendo una funcionalidad todavía en pruebas y que puede afectar profundamente tanto a los hábitos de búsqueda de los usuarios, como al propio papel de Google como generador de tráfico orgánico así como a su principal modo de monetización, los Google Ads, es lógico que hayan testado múltiples formas y soluciones de integrar este nuevo panel en las páginas de resultados.
¿Cómo afecta Google SGE a los resultados tradicionales?
En algunos casos, el impacto de Google SGE será nulo, mientras que en otros, es de esperar que sí impacte sobre el ratio de click (CTR) de una forma parecida a como lo han hecho los resultados destacados (featured snippets), es decir, disminuyendo significativamente el número de clicks en las primeras posiciones.
En las pruebas efectuadas, hemos identificado distintos casos:
- Instantánea potenciada por inteligencia artificial no disponible: la SERP es la tradicional y no presenta la posibilidad de generar
- Panel de resultados de Google SGE no mostrados de inicio, pero sí disponibles a través del botón Generate.
- Panel de resultados de Google SGE parcialmente desplegado de inicio.
Anteriormente, detectamos otros dos casos que no están ya disponibles desde hace algunas semanas:
- Panel de resultados de Google SGE no mostrados de inicio, pero sí disponibles a través del botón Converse: este botón ya no se muestra.
- Panel de resultados de Google SGE desplegado totalmente de inicio: no encontramos casos donde el panel de resultados SGE se muestre desplegado de inicio.
En una muestra mucho más amplia de búsquedas con mezcla de palabras clave informacionales, transaccionales y locales, Michael King registró que Google presentaba el panel SGE en casi el 40% de las búsquedas.
Qué tipo de consultas no resuelve Google SGE: YMYL
En general, Google SGE no muestra resultados para búsquedas relacionadas con “tu dinero o tu salud” (Your Money, Your Life), ya que en este caso los resultados podrían tener un impacto sobre la salud física o financiera de los usuarios. Dado que el contenido generado por Google SGE no es una copia literal de ningún resultado externo, Google mismo sería el responsable legal de la exactitud o fiabilidad de la información mostrada, lo que en estos casos implica un gran riesgo.
Las temáticas directamente afectadas son:
- Salud o seguridad física del usuario.
- Seguridad financiera.
- Sociedad en su conjunto: es decir, temas conflictivos o polémicos que pueden afectar a la estabilidad de la sociedad, la confianza en las instituciones públicas, etc.
Por ejemplo, si buscamos «qué tipo de hipoteca es asumible», Google sí muestra el panel de resultados SGE pero incluye un mensaje de exención de responsabilidad: «Esto no es un consejo financiero profesional. Consultar con un consejero financiero para recomendaciones específicas sobre tus circunstancias particulares sería lo mejor«. Si, además, especificamos algo más la búsqueda, «qué tipo de hipoteca es asumible si tengo 50 años«, entonces Google ya no «se moja» y directamente no presenta el panel SGE ni siquiera como opción.
Otros ejemplos: «qué tipo de cuenta corriente debería abrir para ahorrar dinero» sí presenta panel SGE acompañado de la mencionada exención de responsabilidad. Si especifico algo más: «qué tarjeta de crédito es mejor si tengo un mal historial crediticio«, entonces ya no genera resultados SGE.
Para búsquedas más conflictivas: «debería invertir mis ahorros en bitcoin», evidentemente Google se mantiene a salvo y no muestra el panel SGE.
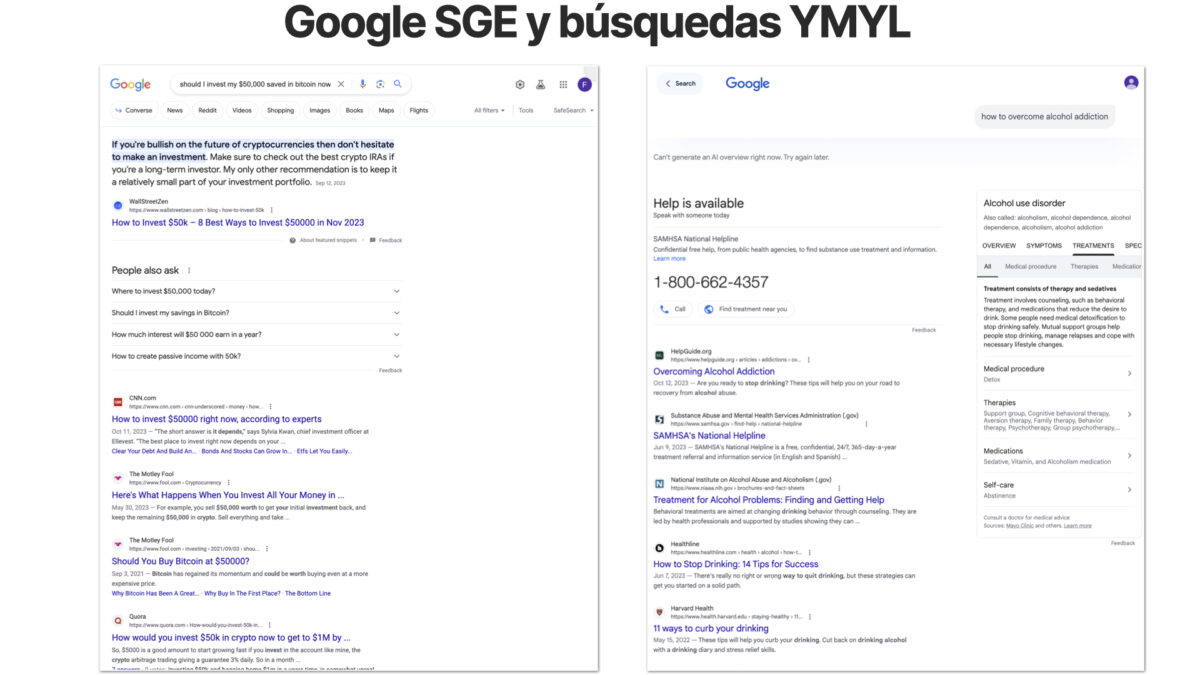
Lo mismo ocurre para búsquedas de consejo médico, por ejemplo: «cómo podría perder tres tallas de pantalón en dos semanas» o polémicas «por qué deberían los Estados Unidos prohibir la venta de armas de asalto«. En la mayoría de casos, Google no presentará el panel de resultados SGE y cuando sí lo haga, siempre irá acompañado de algún tipo de mensaje de exención de responsabilidad.
¿Cómo podría impactar Google SGE en el SEO?
Para evaluar realmente el impacto de Google SGE deberemos esperar a que se lance en más países y esté disponible para el público en general. De momento, solo está disponible en 120 países, no en Europa ni Canadá, y solo para un grupo de usuarios que han optado la funcionalidad en sus perfiles de Google.
No obstante, incluso si Google despliega este tipo de resultados al público en general, nos encontraremos con distintos grados de impacto:
- Para empezar, no todas las búsquedas generan resultados SGE: para las búsquedas donde no se generan resultados SGE o donde el usuario debe “forzar” la aparición del panel haciendo clic en el botón que los genera, el impacto sobre el tráfico orgánico será muy reducido. Los usuarios harán clic en el resultado que directamente más se ajuste a su intención de búsqueda, antes de hacer un clic adicional y esperar unos segundos a que Google complete el panel SGE (en los casos en que finalmente sí lo muestra, que tampoco es siempre).
- En búsquedas informacionales de respuesta directa: podemos esperar una caída en el CTR similar a la que obtenemos cuando Google presenta un Resultado destacado (featured snippet). En estos casos, dependerá mucho de que el extracto presentado por Google en el panel SGE sea considerado suficiente para satisfacer la intención de búsqueda del usuario o no.
- En búsquedas transaccionales: el viaje del cliente ser verá acortado. Podemos esperar menos clics en páginas de categoría de producto (esa parte del proceso de decisión se traslada a las páginas del buscador) y más clics en las páginas de detalle de producto, aunque con un ratio de conversión superior, ya que el usuario habrá tenido la oportunidad de comparar y contrastar ventajas e inconvenientes ya en el propio panel de resultados SGE.
- En cualquier caso, el CTR (incluso para la posición 1) disminuirá, ya que los resultados orgánicos son “empujados” más abajo por anuncios y el panel SGE. A partir de ahora, el objetivo del posicionamiento es mucho más amplio y consistirá en conseguir visibilidad en los múltiples formatos y widgets que conforman las páginas de resultados de Google. Gilad David Maayan aventura un impacto negativo de entre un 30 a un 60% menos de tráfico.
- Aumentará la proporción de búsquedas específicas: los buscadores nos «han entrenado» en una cierta forma de formular nuestras búsquedas para obtener los resultados que deseamos. La interfaz mucho más conversacional de Google SGE, donde nos anima a plantear nuestras preguntas o hacer clic en algunas de las sugeridas, y los resultados se presentan también en un lenguaje natural fomentará la adopción búsquedas más específicas y naturales. Esto significa que las páginas de detalle de producto (PDP) o de contenidos concretos (noticias, por ejemplo) registrarán probablemente un mayor volumen de tráfico orgánico en detrimento de las páginas de familia de producto o de categorías de contenido (temáticas). El posicionamiento long-tail tendrá mucha más importancia.
- Estar en primeras posiciones en resultados orgánicos aumenta las probabilidades de ser uno de los sitios web referenciados en el panel de Google SGE:en el citado estudio de Michael King, los sitios posicionados en primer, segundo y noveno puesto fueron los que con mayor frecuencia aparecían en los resultados SGE y, en la mayoría de casos, Google incluye hasta seis de los diez primeros resultados en este panel.
Las herramientas SEO tendrán que adaptarse: el ranking de las diez primeras posiciones orgánicas está dejando de tener sentido. Es una incógnita cómo impactará Google SGE sobre el CTR previsto para cada posición y, por tanto, la estimación de clics para cada palabra clave.
Cómo podemos prepararnos para Google SGE
Una nueva oportunidad de lograr visibilidad
Google SGE es tanto una amenaza para el CTR obtenido para los primeros resultados orgánicos como una oportunidad de ganar visibilidad en un nuevo formato de resultado que podría marcar el futuro de Google como herramienta de búsqueda. Todo lo que aplicamos para posicionar un sitio Web sigue plenamente vigente pero, además, ser una de las fuentes de referencia de Google para componer sus resultados impulsados por IA se convierte en un objetivo clave adicional. En las pruebas efectuadas por Human Level y otras consultoras ya hemos comprobado que los sitios web mejor posicionados son los que con mayor frecuencia se convierten en las tarjetas de referencia en los distintos carruseles de Google SGE.
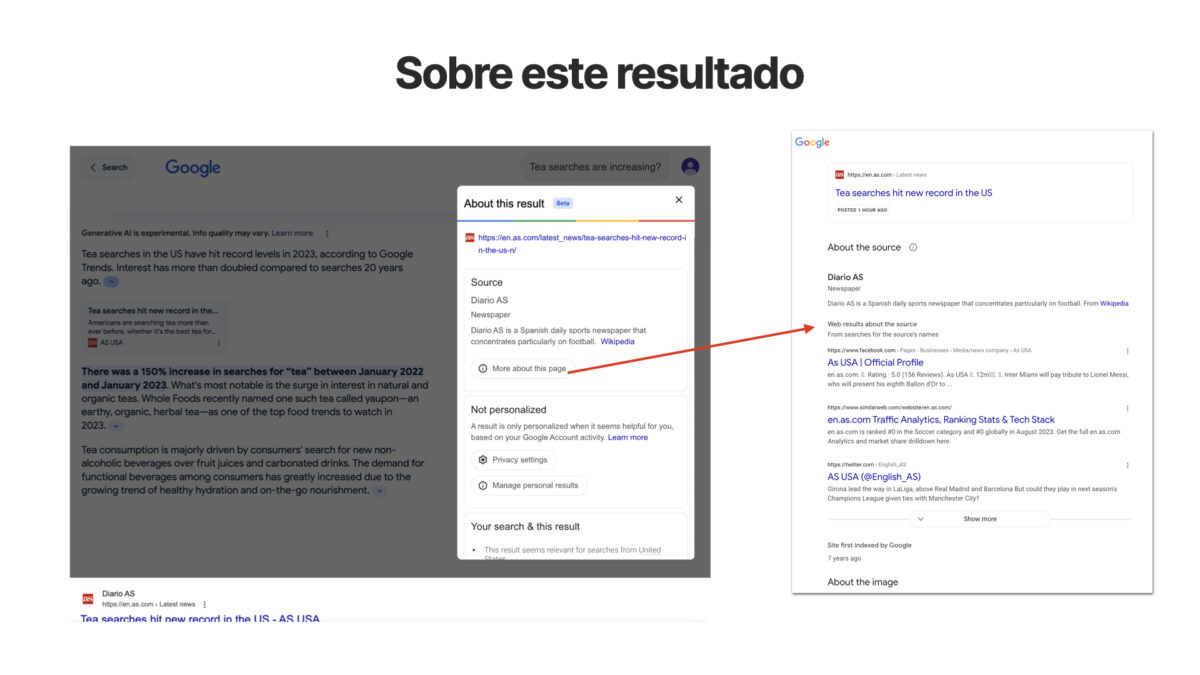
Al hacer click sobre la opción Sobre este resultado, Google muestra información que justifica por qué ese contenido y ese sitio Web han sido elegidos como referencia y es fácil comprobar cómo los ya famosos E-E-A-T de experiencia, expertise, autoridad y confianza son los indicadores que pueden marcar la diferencia. Específicamente para medios, comenzamos a familiarizarnos con estos indicadores a través del Trust Project. Y vemos cómo estos indicadores de confianza se han ido extrapolando y aplicando también a sitios corporativos, de viajes, comercio electrónico, market places, etc. De modo que debemos conocer y aplicar en la medida de nuestras posibilidades todas las recomendaciones para mejorar el EEAT de nuestro sitio Web.
Más que un resultado destacado
Hasta cierto punto, el panel de Google SGE es una evolución del resultado destacado o featured snippet. En el caso del resultado destacado, Google selecciona el que considera resultado óptimo para una búsqueda, extrayendo la respuesta de su contenido y reproduciéndola literalmente el inicio de los resultados. El panel de Google SGE pasa a ocupar esa posición destacada solo que, en este caso, en lugar de extraer la información literalmente de un único resultado, identifica el consenso entre varios sitios Web que toma como referencia y sintetiza lo esencial de la información aportada aplicando la generación de un LLM. En ambos casos, la clave es convertirnos en la referencia de Google como fuente de esa información, ya que es la única forma de situar nuestro enlace en esta área privilegiada de la SERP.
Aprovecha el long-tail
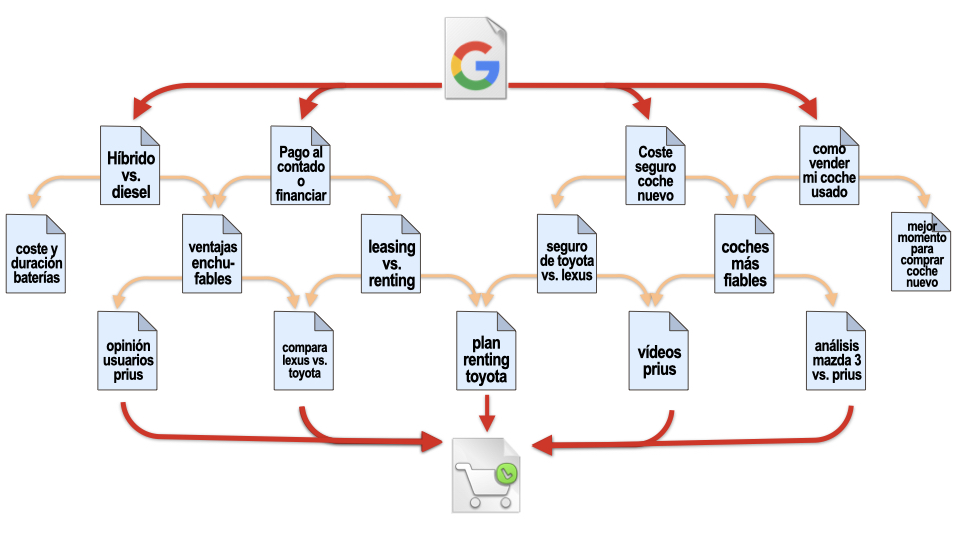
Como decíamos al inicio del post, la interfaz conversacional de Google SGE acostumbrará paulatinamente a los usuarios a plantear consultas de una forma más natural y específica para sus necesidades. Existe una gran oportunidad de posicionar contenido para estas búsquedas específicas que, aunque con menor potencial de búsqueda, atraerán visitas de mucha calidad. Pero no solo eso: no nos olvidemos de las preguntas de seguimiento sugeridas o libres con las que Google anima a los usuarios a profundizar en sus búsquedas. Si las preguntas de los bloques PAA (People Also Ask) nos han servido de inspiración para desarrollar nuevos contenidos, las preguntas de seguimiento sugeridas nos ayudarán igualmente a desarrollar contenidos específicos con los que acompañar a nuestros usuarios en su proceso de decisión de compra. Deberemos analizar con atención las preguntas de seguimiento propuestas por Google para cada una de nuestras búsquedas clave donde sí aparezca el panel de resultados SGE.
Esta recomendación ya aparecía en el siguiente ejemplo de una presentación mía de alrededor de 2013, en la que recomendaba analizar el customer journey de un potencial cliente y desarrollar contenidos específicos para cada fase del proceso de decisión de compra:
Controla el CTR en tus resultados
Comprueba discrepancias entre la posición promedio y el CTR logrado en Google Search Console:
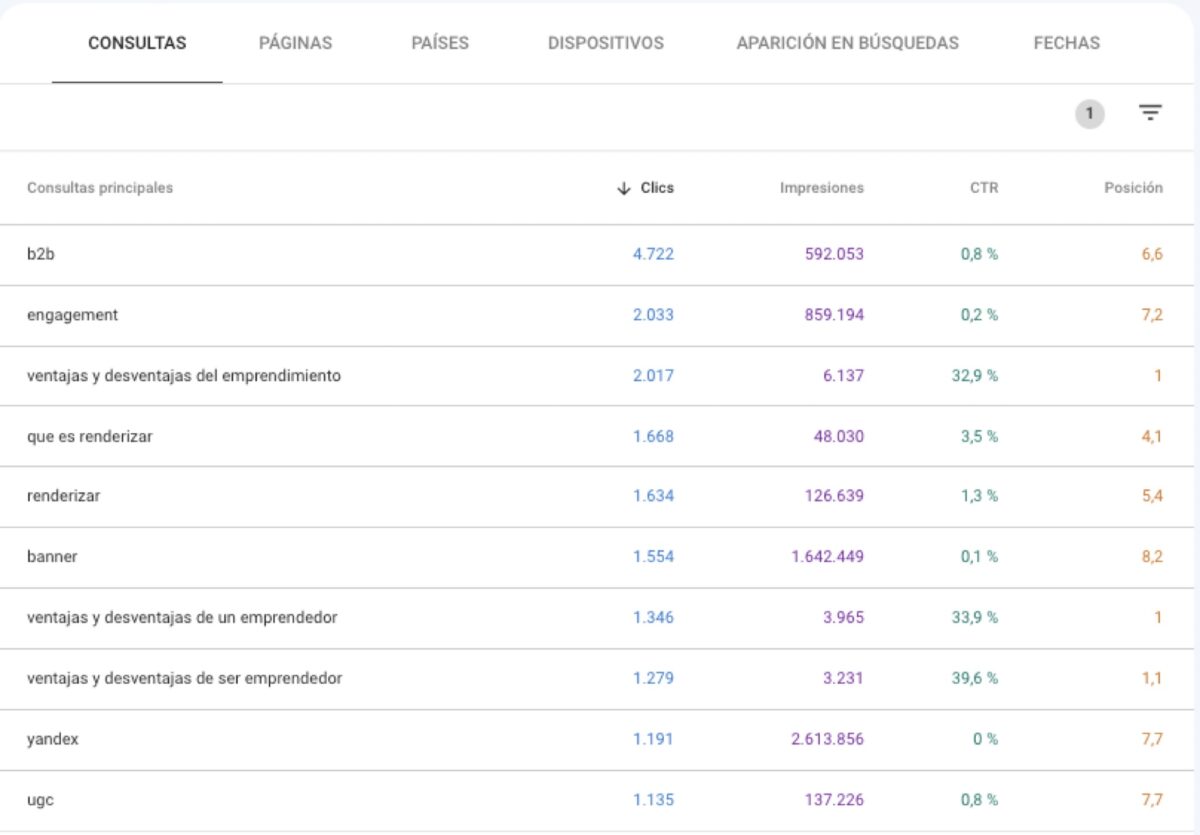
Una buena posición con un CTR inusualmente bajo podría indicar un alto impacto de un resultado destacado o bien de un panel de Google SGE.
Analiza para qué búsquedas sí aparece SGE y por qué
Monitoriza las páginas de resultados para cada una de tus keywords y revisa cuándo aparece el panel de Google SGE y cuándo no. El mayor impacto vendrá, evidentemente, de búsquedas donde sí aparece Google SGE.
Una vez comprobadas estas keywords, revisa cuáles son los dominios más frecuentemente enlazados como referencia en el carrusel principal del panel SGE o en alguno de los carruseles secundarios. Haz click en Sobre este resultado y trata de descubrir cuáles son los indicadores de confianza y autoridad temática que están llevando a Google a tomar ese dominio como referencia:
¿Debemos bloquear las IAs?
Por último, cabría preguntarse si deberíamos bloquear el acceso de los LLMs y otras inteligencias artificiales a nuestros contenidos. De momento, nuestra opinión es que no, por estas razones:
- Estamos en los primeros compases en el uso de estos modelos de IA, y no se ha definido todavía (y mucho menos regulado) cuál debería ser un uso adecuado y justo en relación a la propiedad intelectual de los datos de entrenamiento.
- En función de cómo se regule esto, ChatGPT y similares podrían incluir mecanismos de atribución y ofrecer enlaces a la fuente original de los contenidos, actuando como fuente adicional de tráfico web.
- Aún es pronto para predecir para qué categorías de búsquedas los LLMs se pueden convertir en una primera opción para los usuarios. Hasta ahora, la falta de actualización de los conjuntos de datos y la “imaginación” de muchas de sus respuestas están despertando el escepticismo y haciéndolos aparecer como una fuente de información poco confiable.
- Posibles problemas legales derivados de la exactitud y fiabilidad de la información dada podría convertir la atribución a terceros en la mejor opción para esquivar posibles querellas.
No obstante, según Originality.ai, 20% de los 1.000 sitios web más importantes del mundo ya están bloqueando GPTbot a septiembre de 2023. Entre ellos, muchos sitios de medios online y algunos de los portales de comercio electrónico más importantes, como Amazon o New York Times.
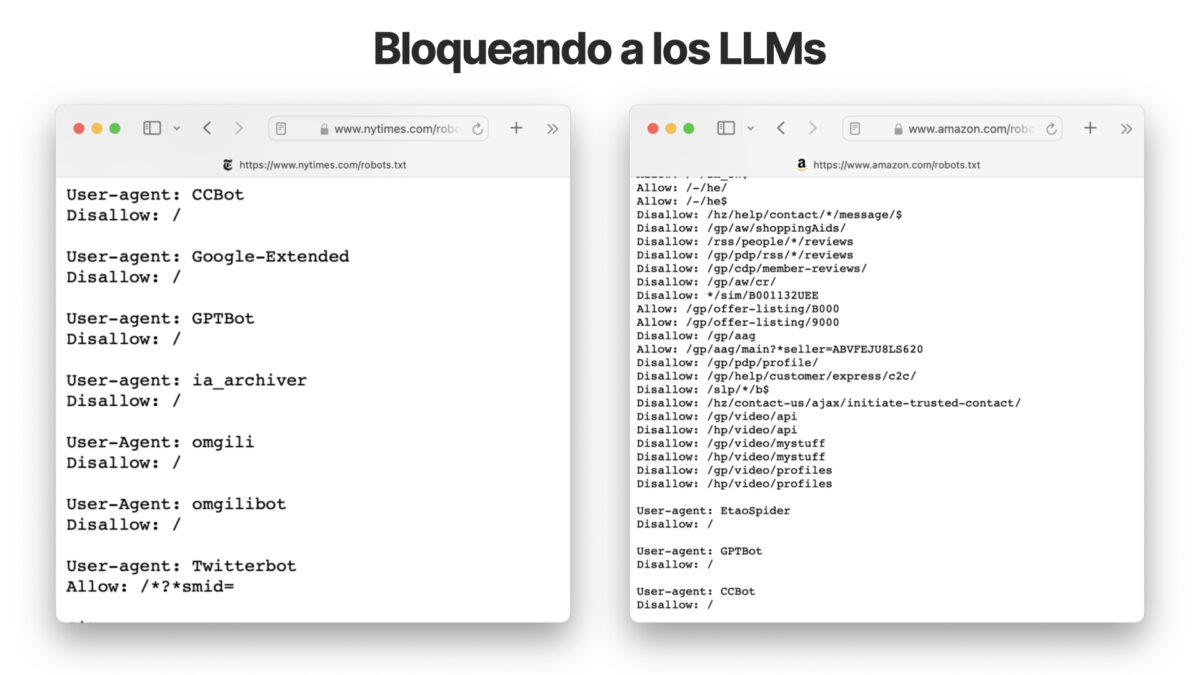
En cualquier caso, para impedir que nuestro sitio Web aparezca en el panel de Google SGE tendríamos que bloquear completamente a Googlebot, por lo que ello nos dejaría también fuera de los resultados orgánicos tradicionales.
Algunos ejemplos de Google SGE
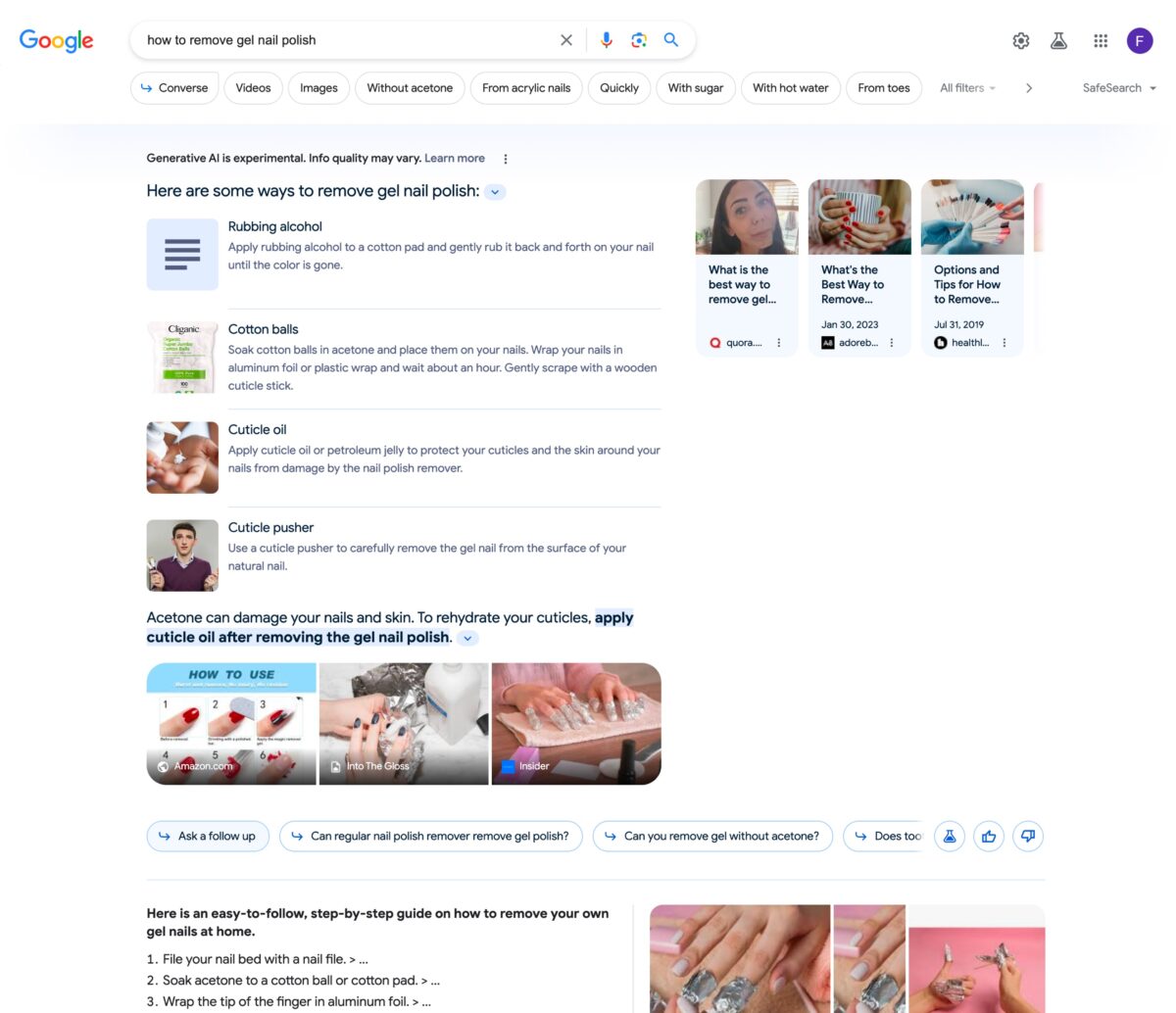
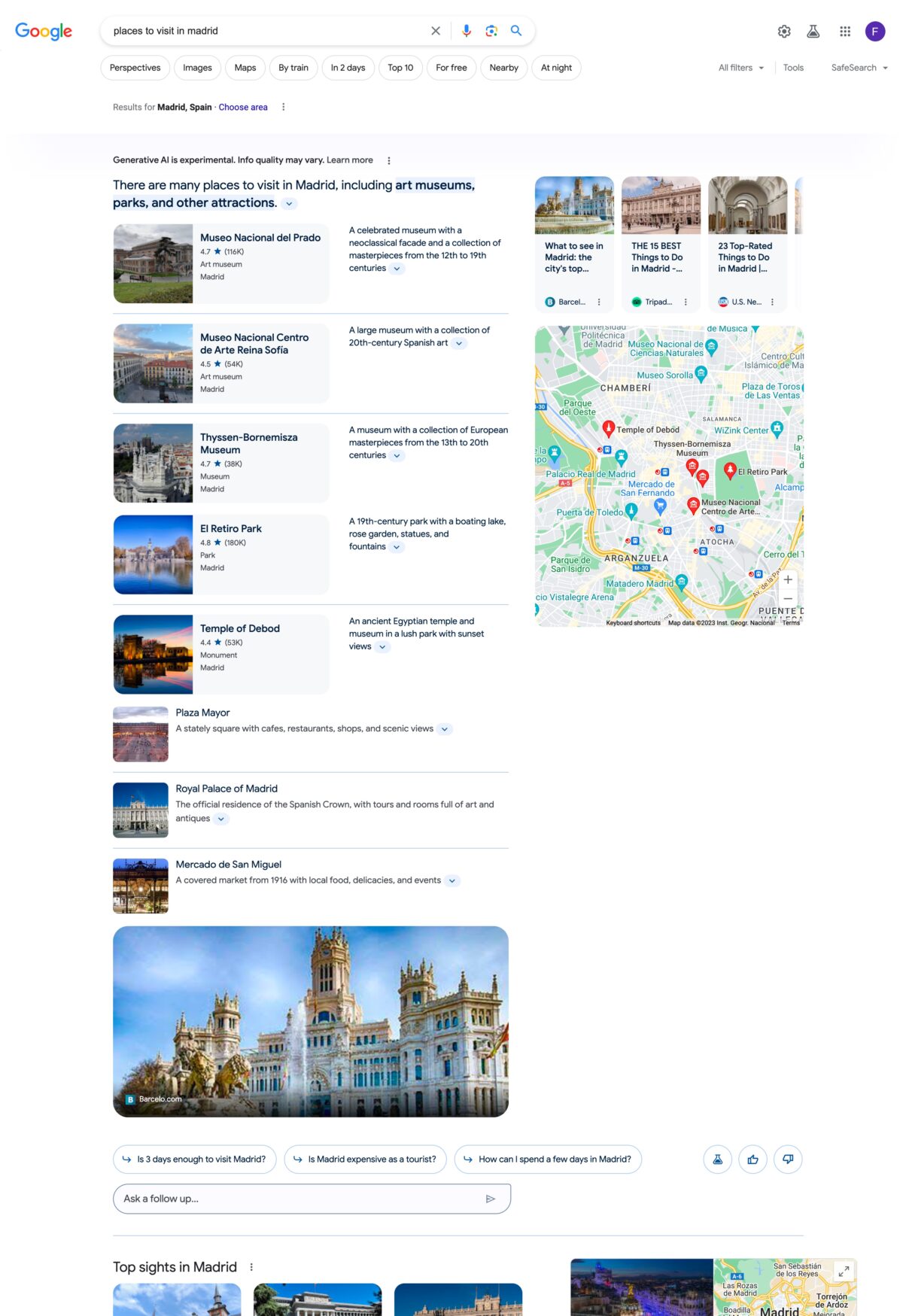
El panel de resultados que presenta Google SGE no tiene una disposición única, sino que adopta una estructura distinta en función del tipo de búsqueda introducido. Los modelos más representativos son los que se muestran para búsquedas informacionales, transaccionales, locales o relacionadas con el sector de viajes.
Búsqueda informacional
Búsqueda transaccional
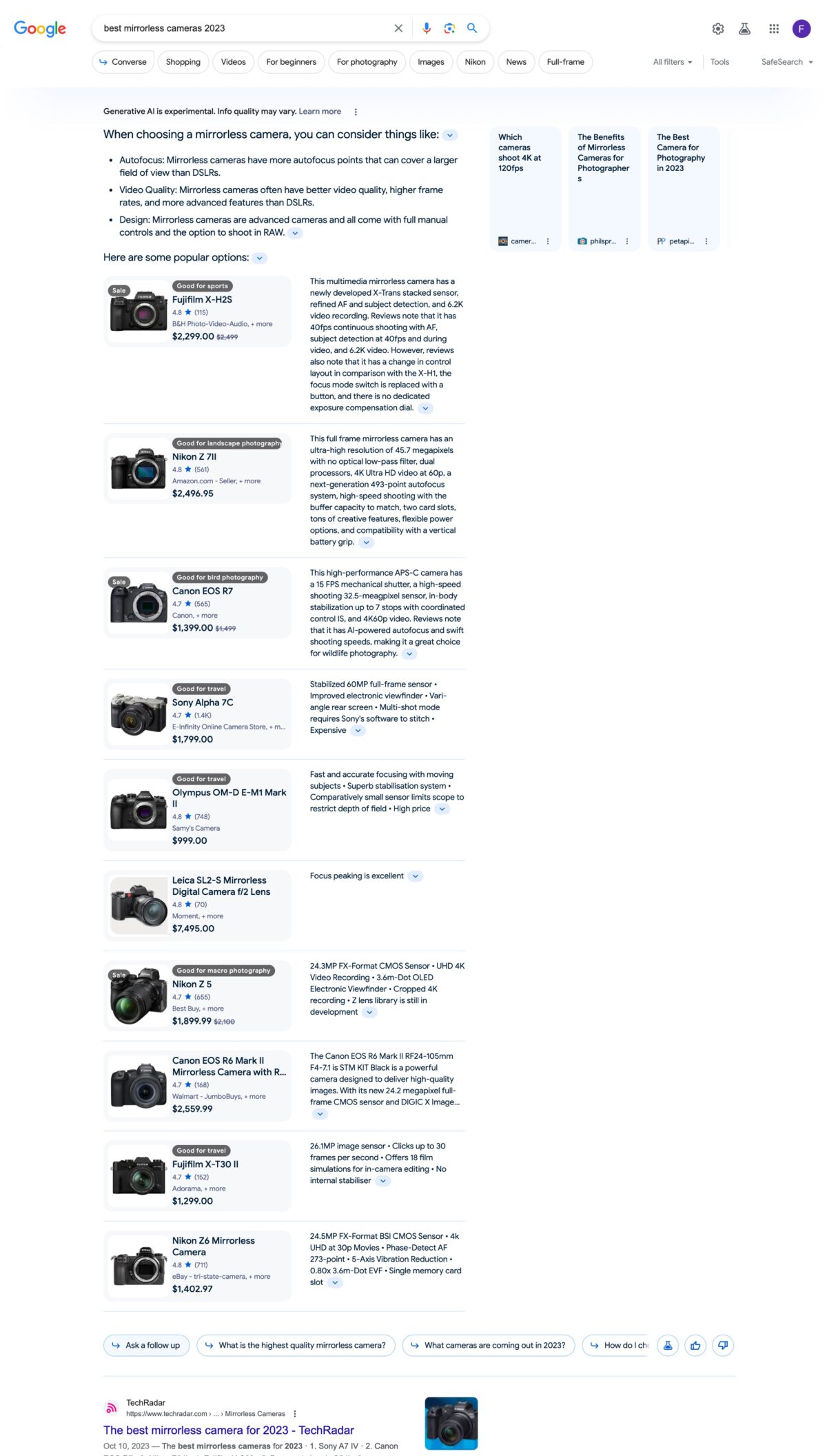
Búsqueda local
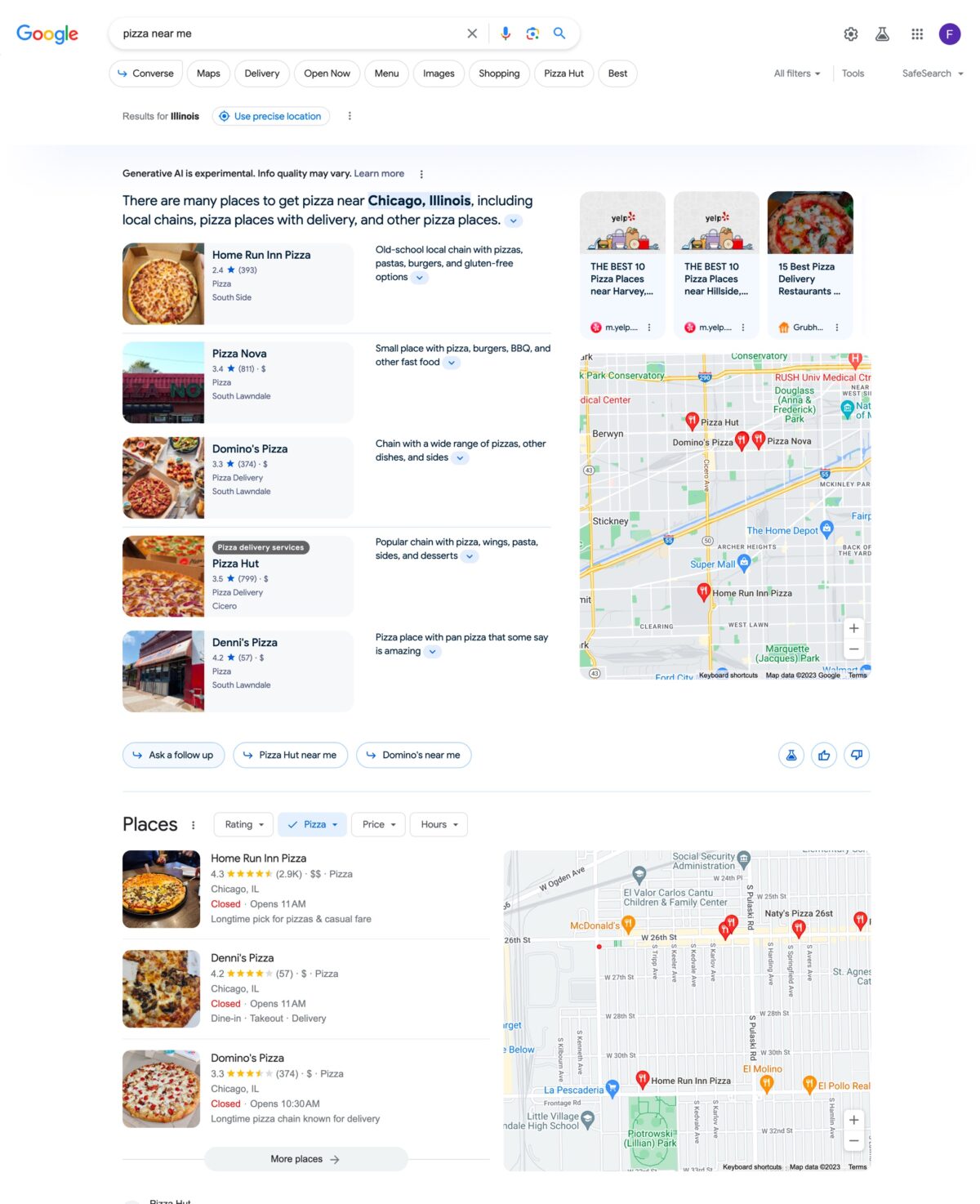
Búsqueda sector travel
Conclusión
Aunque ya se ha lanzado en 120 países, no está todavía claro que Google vaya a desplegar la funcionalidad de Google SGE y hacerla accesible para el público en general y la totalidad de las búsquedas. Es lógico que haya querido someter a este nuevo formato de resultado a un intenso test masivo para entender cómo impacta a los hábitos de uso del propio buscador, a su modelo publicitario, al difícil equilibrio de relaciones con los creadores y difusores de contenidos, etc.
Es posible que el panel de Google SGE que se despliegue definitivamente se parezca al que podemos analizar hoy, pero también es probable que sufra numerosas evoluciones y mejoras, como hemos podido comprobar en los últimos meses. Mientras, deberemos estar pendientes de su evolución para anticipar su impacto y prepararnos para competir en este nuevo espacio de visibilidad.
Y tú, ¿cómo piensas que podría afectar Google SGE a los hábitos de búsqueda y al SEO? Te leo abajo ?
Referencias adicionales
- An SEO’s guide to understanding large language models (LLMs)
- Large Language Models and Knowledge Graphs: Merging Flexibility and Structure
- Transformers: the Google scientists who pioneered an AI revolution
- Google’s new A.I. search could hurt traffic to websites, publishers worry
- Google is ready to fill its AI searches with ads.
- Hilo en Twitter de Juan González sobre la patente tras Google SGE.


