

Escrito por Jose Vicente
Índice
Para hacer auditorías técnicas solemos recurrir a crawlers o herramientas SEO que extraen las etiquetas involucradas en el posicionamiento como el title, metas, etiquetas de jerarquía de títulos, etc. Por lo general, estas herramientas como Screaming Frog o Ryte extraen un gran número de estos factores, pero existen muchos tipos de sitios y cada uno de ellos tiene sus peculiaridades.
Es muy recomendable elegir una herramienta que nos permita configurar variables personalizadas que nos ayudarán a evaluar de forma más precisa cada proyecto. Esta configuración se suele hacer de diferentes formas, lo más común es usar expresiones regulares y selectores XPath que nos ayudarán a identificar qué queremos extraer en cada página.
Qué son las expresiones regulares y XPath
Las expresiones regulares nos permiten hacer búsquedas que cumplan un cierto patrón dentro de textos, que en este caso serán HTML. Aunque depende del programa que utilicemos, la mayoría de ellos cumplen con la especificación estándar que podemos consultar en muchos sitios como:
- Expresiones regulares en Wikipedia
- Expresiones regulares en Mozilla
- Herramienta de test de expresiones regulares
Dado que en muchas ocasiones no nos interesará simplemente buscar si aparecen ciertas cadenas de caracteres dentro de un texto, sino capturar el contenido o hacer un recuento de los que cumplan cierto patrón, deberemos recurrir al uso de expresiones regulares y selectores XPath.
Es muy recomendable conocer su sintaxis y entender su funcionamiento ya que podremos usarlas en muchas herramientas y nos ahorrarán mucho trabajo. Un ejemplo de ello es el uso en Google Analytics que ya vimos en este artículo.
XPath sigue una idea parecida a las expresiones regulares pero su funcionamiento es distinto ya que solo podremos aplicarlo a estructuras XML, lo que en este caso cumple el HTML. Por lo tanto su limitación es que no podremos aplicarlo a textos planos como en el caso de las expresiones regulares, pero veréis como para ciertos usos nos resulta más preciso porque podemos seleccionar ciertos elementos del de forma inequívoca.
Como en el caso de las expresiones regulares, podemos consultar mucha documentación de cómo se usan estos selectores:
Pero veamos cómo funcionan con un ejemplo.
Obtención de la canónica de cada página
Aunque esto es algo que podemos obtener con todos los crawlers SEO conocidos, pero nos hemos encontrado en muchas ocasiones con errores en ciertas configuraciones, por ejemplo, en Screaming Frog cuando una URL indicada es relativa al protocolo la reescribe dependiendo del protocolo con el que ha accedido. Si estamos revisando la implementación de la canónica y queremos revisar qué literal concreto han configurado los programadores en cada página del sitio para detectar errores, la funcionalidad por defecto de Screaming Frog no nos servirá.
Como ya sabéis la etiqueta de enlace rel canonical tiene la siguiente sintaxis:
<link rel=“canonical” href=“https://www.ejemplo.com/" />
Luego simplemente con la expresión regular <link rel=“canonical” href=“(.*)“ /> debería localizarnos ese patrón dentro del HTML y devolvernos el literal que aparece dentro de las comillas de atributo href. ¿Pero qué pasa si por ejemplo se intercambian los atributos rel y href o si se añade algún atributo adicional? Deberíamos tener en cuenta todas las posibles variaciones en la expresión regular que configuremos.
Esto debería solucionarse con la obtención del valor mediante XPath ya que se tratará simplemente de hacer referencia al atributo href del elemento de enlace cuyo atributo rel sea igual a canonical. El selector en este caso sería el literal //link[@rel=“canonical»]/@href , y así obtenemos el valor del atributo href de los elementos de enlace cuyo rel es canonical.
De esta forma no nos importa el orden en que aparezcan los atributos rel y href en este caso ya que el motor va a buscar el elemento de enlace link que cumpla la condición. Luego, aunque seguramente con expresiones regulares podríamos resolver todas las distintas opciones, en este caso sería más seguro hacerlo con XPath para cubrir todas las opciones posibles.
Obtención del ID de Google Analytics
Un caso muy distinto sería si quisiéramos por ejemplo capturar el código de seguimiento de Analytics presente en cada página del sitio. En este caso, puesto que el código debe estar dentro de un elemento script, no nos es posible seleccionar el XPath concreto del código UA. Por lo tanto tendríamos que buscarlo dentro del texto con una expresión regular como ua-[0-9]{6}-[0-9] en la que le indicamos que nos busque un texto que empieza por ua- y que sigue con 6 dígitos númericos, otro guión y por último otro dígito.
Ejemplos de extracción de variables personalizadas con Ryte
Para probar la extracción mediante expresiones regulares y Xpath vamos a usar como ejemplo Ryte, aunque es algo que podemos hacer con otras herramientas aplicando la misma lógica. Ryte ya maneja una gran cantidad de indicadores estándar relacionados directamente con el SEO, pero como ya hemos dicho, es de gran ayuda poder crear nuestros propios indicadores ya que cada proyecto tiene sus peculiaridades.
En este caso Ryte dispone de dos funcionalidades para poder crear Snippets personalizados:
- Recuento personalizado: nos permite contabilizar las ocurrencias del patrón introducido en cada página analizada.
- Campos personalizados: nos permite recopilar en una variable personalizada el texto o html que cumpla el patrón indicado.
Número de elementos de listados de categorías
En los tiempos que corren en el SEO este es un indicador muy interesante ya que nos permite detectar listados que muestren un número pequeño de elementos. Estas páginas suelen ser identificadas por Google como thin content y pueden poner en peligro el posicionamiento de nuestro sitio.
Con Ryte podemos hacer esto configurando un ‘Recuento personalizado’ del tipo de etiqueta que contienen cada uno de los elementos listados. Por ejemplo, en las etiquetas de un WordPress se suelen maquetar los artículos listados dentro de la etiqueta <article>. Luego solo tenemos que seleccionar la opción de Snippets personalizados en Ryte y dentro de ésta configurar un ‘Recuento personalizado’ como vemos a continuación.
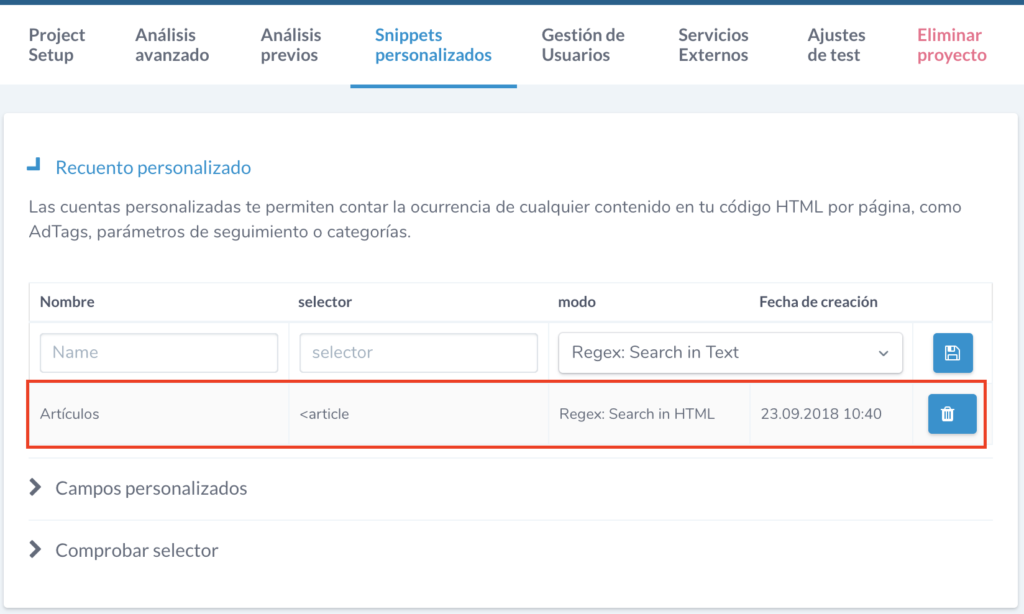
Una vez configuremos esto, en el siguiente rastreo que se haga del sitio obtendremos una variable personalizada llamada Artículos en la cual se contabilizarán el número de etiquetas <article> que aparecen en la página. Para acceder a ella vamos a la opción de menú Website Success > Contenido > Mis recuentos personalizados y dentro de esta opción encontraremos nuestra variable Artículos que mostrará el siguiente gráfico.
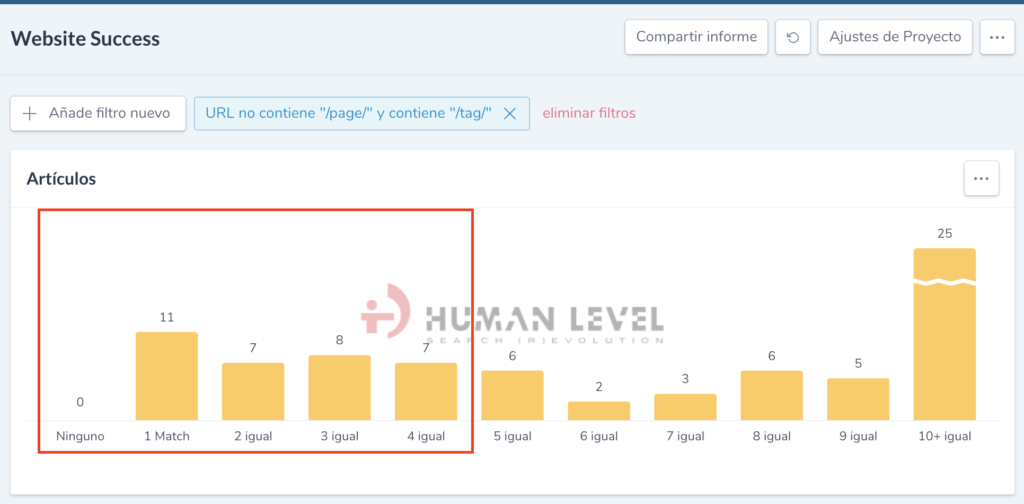
Este informe nos muestra el número de páginas en las que se ha encontrado un determinado número de elementos, por ejemplo podemos ver que habría 11 tags que listarían un solo artículo, 7 tags que listarían solo 2 artículos y así sucesivamente. Para afinar más el análisis hemos aplicado un filtro de modo que podamos ver datos de las tags, excluyendo el paginado.
Sería recomendable por lo tanto analizar los tags con menor número de artículos relacionados, en concreto para cada caso revisaremos:
- Si son necesarios y podemos aumentar la cantidad de contenidos o debemos desindexarlos.
- Si son prescindibles y podemos eliminarlos.
Como Ryte nos permite personalizar los informes añadiendo columnas de Google Analytics, sería interesante contrastar estos valores con el número de sesiones o páginas vistas. De este modo tendremos un dato más para apoyar nuestra decisión o bien analizar si hay una correlación directa entre el número de artículos listados y su rendimiento.
Número de comentarios de las fichas de productos o de los posts
Los comentarios son una valiosa fuente de contenido adicional para las fichas de productos de nuestra tienda online o artículos de nuestro blog. Además de la cantidad de contenido, su texto contiene un long tail que aporta el lenguaje propio de los usuarios y mayores alternativas de posicionamiento.
En nuestro sitio de ejemplo los comentarios están maquetados dentro de un elemento div cuyo id es igual a comments y dentro de este cada comentario se maqueta dentro de una etiqueta article. De modo que vamos a configurar un recuento de las etiquetas article que hayan dentro de este div con el siguiente selector de XPath //div[@id=’comments’]//article .
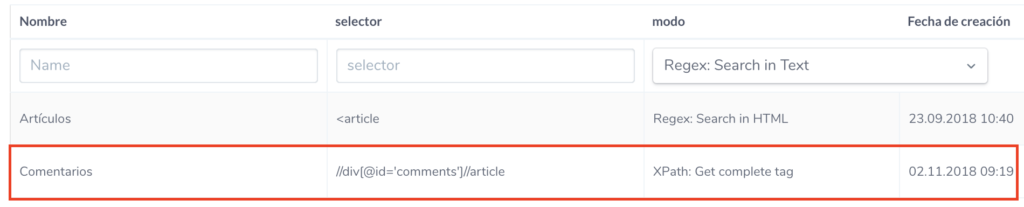
Esta forma es más precisa que la configuración anterior del recuento de Artículos ya que cuenta las etiquetas article que hay dentro de la cada de comentarios en cada página. En el caso anterior simplemente se comprueba cuantas veces aparece el literal <article en todo el HTML de la página sin tener en cuenta en qué parte de esta aparece.
Más métricas que pueden ser interesantes para el SEO
Hemos visto algunos ejemplos configurados en un caso concreto que os pueden ayudar a aplicarlo en vuestro caso concreto. Estas serían algunas ideas adicionales de métricas que valdría la pena analizar.
- Extensión de las descripciones de artículos, categorías o contenido de los artículos.
- Número de imágenes de producto o insertadas en el contenido de los artículos.
- Autor de los artículos.
Pero los indicadores pueden ser tantos como sitios distintos y en cualquier caso estas variables personalizadas nos pueden servir para evaluar nuestra web y establecer comparaciones con nuestros competidores.
Cómo probar la configuración antes de rastrear con Ryte
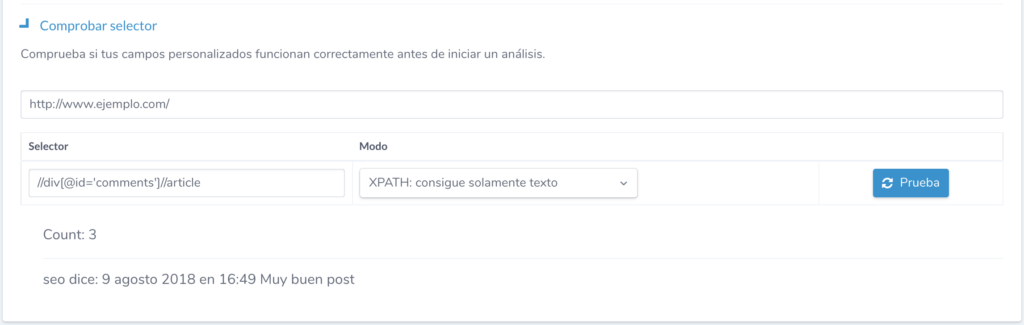
Para no tener que esperar a que Ryte rastree todo el sitio podemos comprobar previamente los selectores o expresiones regulares con la funcionalidad Comprobar selector dentro de la sección de Snippets personalizados. Solo tenemos que insertar una URL de prueba, el selector configurado y el modo en el que debe interpretarse para obtener el número de elementos que cumplen el patrón y un ejemplo del código que contiene el primero encontrado.
Aunque hay cientos de factores SEO aplicables a todo tipo de sitio web, hay características propias de cada sitio web que con la configuración estándar de las herramientas SEO no vamos a poder evaluar. Por lo que es importante contar con una que permita implementarlas y conocer a fondo sus posibilidades para analizar correctamente su rendimiento y posibilidades de mejora de la visibilidad.



