
Escrito por Ramón Saquete
Índice
Los grandes modelos de lenguaje nos dan respuestas falsas o erróneas con una convicción desconcertante. Si empleas herramientas de IA para investigar, generar contenido o tomar decisiones, este comportamiento supone un verdadero problema de fiabilidad. Un reciente estudio publicado en arXiv identifica por primera vez las neuronas artificiales responsables de ese fenómeno y demuestra que es posible mitigarlo de forma quirúrgica.
Por qué los modelos alucinan
Cualquier arquitectura de IA que dependa de redes neuronales, como los transformers que usan los LLM, siempre estará sujeta a un porcentaje de error. Escalar un modelo (más redes y datos de entrenamiento) reduce ciertos tipos de error, pero no elimina las alucinaciones. El benchmark Omniscience de Artificial Analysis lo ilustra con claridad: incluso los modelos más grandes del mercado siguen generando respuestas incorrectas con alta confianza aparente.
Las alucinaciones se deben a varios factores:
- La calidad o la falta de datos de entrenamiento para determinadas preguntas.
- Los modelos se entrenan para predecir la siguiente palabra más probable, no la más veraz. La respuesta más repetida en los datos de entrenamiento suele coincidir con la correcta, pero no siempre. Recordemos el caso de Einstein, cuando cien científicos quisieron refutar su teoría de la relatividad, a lo que respondió: «¿Por qué cien? Si yo estuviera equivocado, con uno solo bastaría».
- Durante la etapa de ajuste fino supervisado (SFT o Supervised Fine-Tuning), el modelo se entrena con diálogos humanos para seguir instrucciones. Si en esos diálogos las personas fueron demasiado complacientes o evitaron reconocer que no sabían algo, el modelo imitará esos comportamientos.
- El RLHF (Reinforcement Learning from Human Feedback), un ajuste fino de los parámetros del modelo durante el postentrenamiento, introduce una distorsión similar: los revisores humanos tienden a validar respuestas que parecen correctas sobre respuestas honestas que admiten incertidumbre.
El resultado es un modelo que prefiere confabular antes que decir «no lo sé».
La neurociencia aplicada al cerebro de la IA
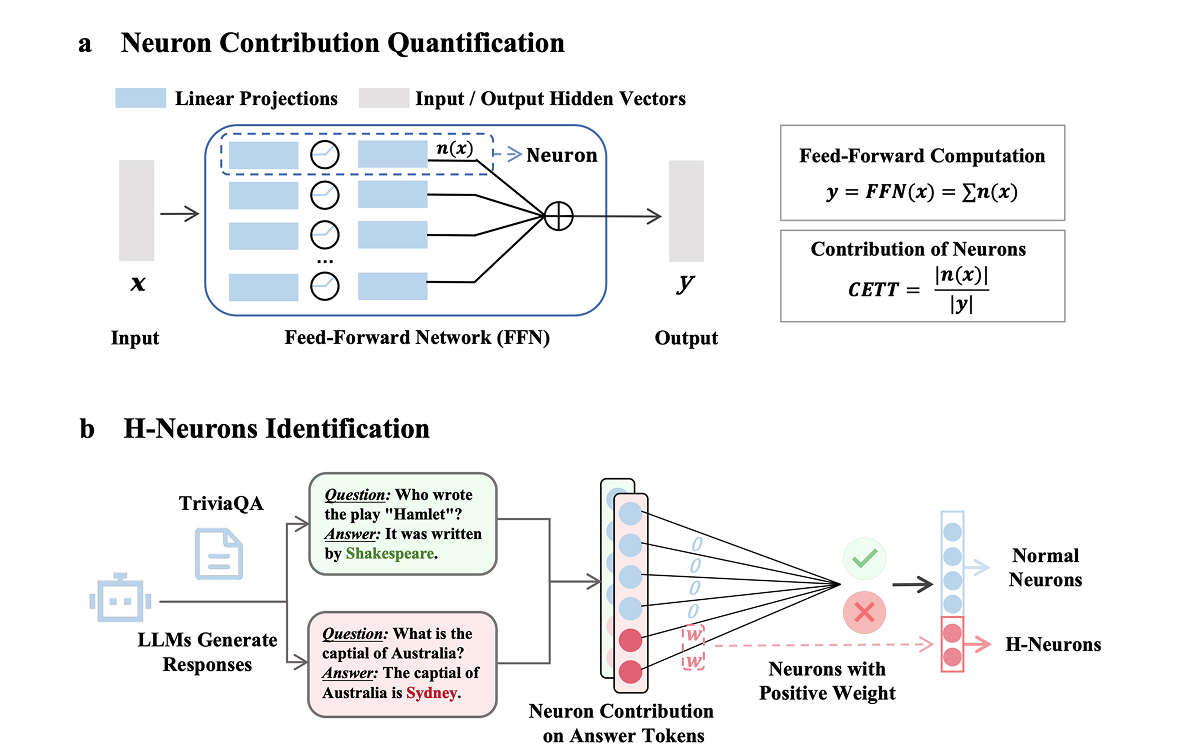
El estudio H-Neurons: On the Existence, Impact, and Origin of Hallucination-Associated Neurons in LLMs aborda el problema desde un ángulo diferente: en lugar de intervenir sobre los datos o el proceso de entrenamiento, los investigadores diseccionan el modelo ya entrenado para identificar qué neuronas artificiales son las responsables directas de las alucinaciones.
Para ello, configuran el modelo con la creatividad al máximo y le formulan repetidamente una misma pregunta de la que saben la respuesta y a la que el modelo siempre responde incorrectamente. En este análisis se obtiene de cada neurona la métrica CETT (Causal Effect on Token Trajectory), que mide la contribución de cada neurona al estado interno del modelo entre capas de neuronas. Haciendo un símil, sería como saber qué neuronas contribuyen más en cada paso de tus pensamientos subconscientes antes de llegar a una respuesta. Después se pasa la información del valor CETT de todas las neuronas del modelo a un clasificador lineal, que es un tipo de algoritmo de IA que, en este caso, separa las neuronas buenas de las que alucinan.
Al probar distintas preguntas, descubrieron que las H-Neurons (así denominan a las neuronas alucinatorias) son las mismas independientemente de la pregunta formulada.
Una proporción minúscula con un efecto desproporcionado
El número de H-Neurons es increíblemente pequeño, aproximadamente solo 1 de cada 100.000. Así, de los más de 100.000 millones de parámetros que tienen actualmente los grandes modelos de lenguaje, solo es necesario ajustar unos pocos para conseguir mejores respuestas.
El experimento también reveló una conexión que no estaba prevista: reducir los pesos o parámetros de estas neuronas (sería el equivalente a reducir la intensidad de las sinapsis entre neuronas en un cerebro biológico) no solo disminuye las alucinaciones, sino que hace al modelo menos complaciente. Al contrario, cuando se aumentan al máximo esos pesos, las alucinaciones se vuelven más frecuentes y aumenta la tendencia del modelo a dar la respuesta que el usuario parece querer escuchar, aunque sea incorrecta. Por tanto, las alucinaciones y la complacencia del modelo están intrínsecamente ligadas.
El estudio añade una implicación relevante para la seguridad: los modelos más complacientes también son más susceptibles a saltarse sus restricciones de contenido. Un modelo que prioriza la satisfacción del usuario sobre la veracidad es, estructuralmente, más manipulable.
A pesar del descubrimiento, no se pueden eliminar por completo estas neuronas alucinatorias y, con ellas, todas las alucinaciones, porque están interrelacionadas con la comprensión del lenguaje. Por tanto, extirparlas degradaría la capacidad del modelo para conectar palabras. Sí que se puede atenuar su efecto de forma considerable, pero debemos recordar que todavía podrían causar alucinaciones los otros factores que hemos comentado al principio del artículo.
El efecto corrector de alucinaciones de esta nueva técnica es mayor cuando el modelo es pequeño, donde hay menos parámetros y menos neuronas, por lo que la proporción de H-Neurons es mayor.
Qué cambia —y qué no— para los profesionales que usan IA
Este estudio no resuelve el problema de las alucinaciones en su totalidad. Las causas estructurales como la calidad de los datos de entrenamiento, optimización por probabilidad en lugar de por veracidad y los sesgos del RLHF permanecen intactas. Lo que aporta es una palanca de intervención precisa sobre el modelo ya entrenado, abriendo la posibilidad de que los próximos modelos incorporen este ajuste de serie y, por tanto, sean más fiables.
Aun así, nadie sabe si en el futuro se llegará a resolver del todo el problema. Para ello, probablemente sea necesario cambiar de forma radical la manera en la que se entrenan o se construyen estos modelos. Venga lo que venga, te mantendremos al tanto en nuestro blog y en nuestra newsletter.



