

Written by Jose Vicente
Index
The Web is an ecosystem that establishes relationships between its contents with links. Within a website this rule must persist, so that both the user and the search engine robots need crawlable links to be able to navigate between all the contents. But the bot also needs to establish the relationship and hierarchy between all its contents.
What are orphan pages?
If a page is disconnected from the rest because it does not receive links from any other page of a website, we are talking about an orphaned page. Orphan pages have no other pages to provide them with authority or relevance through link anchor texts.
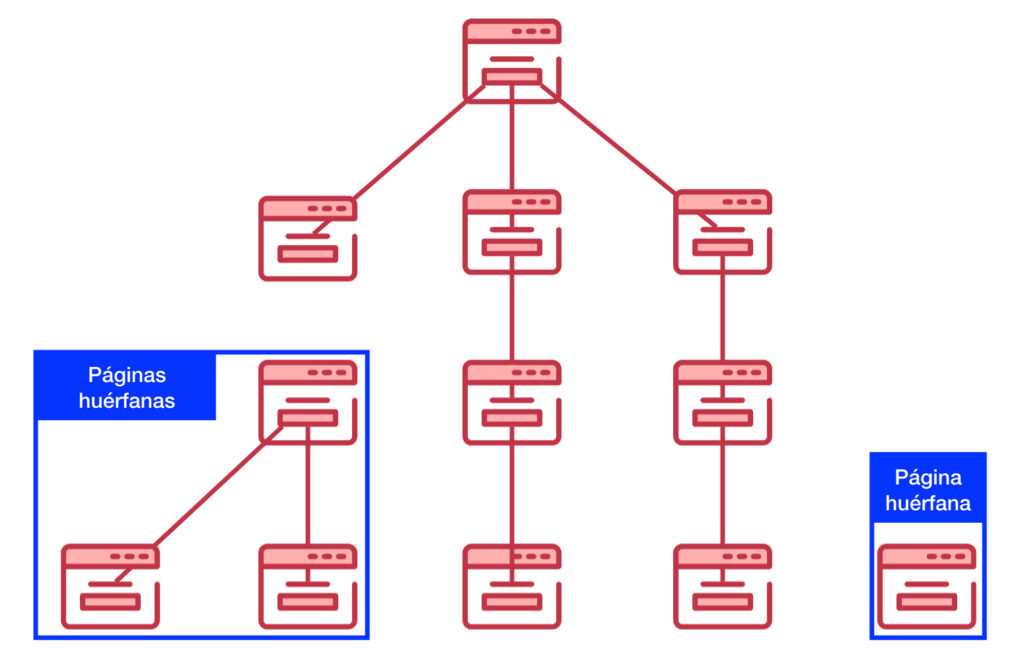
Even if search engine robots are able to reach this content from links coming from other domains, they will not be able to locate them conveniently within the architecture of the site to which they belong.
Are they a problem for SEO?
Orphaned pages are a problem for the SEO of our website not so much because of this disconnection from the rest of the domain content but because of the type of pages that tend to remain in this state. If a page has a good amount of quality content and loses links from the rest of the pages, it will still be a quality page by itself, but its individual ranking will be affected by the loss of links:
- General authority inherited from the rest of the pages.
- Relevance provided by link anchor texts.
- Capacity of periodic analysis by SEO tools, since we cannot access them, we will not be able to detect errors with a current crawl.
But the main problem is that the pages that are orphaned or published and not linked from other pages are often:
- Pages of specific campaigns in Ads or other advertising platform that act as a gateway but in many cases are not usually integrated into the navigation of the site.
- Obsolete pages that are unpublished: the CMS unlinks them from the categories in which they appear but does not delete them.
- URLs that the CMS generates by mistake and that are disconnected from the architecture.
- Tests and tests that are performed but then not removed and that represent in many cases duplicate content.
If this type of pages are repeated continuously and cumulatively, in the end this thin content can be a problem for the organic positioning of our website.
Therefore, orphaned pages can cause problems in getting SEO traffic because of these two different problems:
- Lack of links from the site itself, which will weigh down the positioning.
- Generation of thin content when its content is not of quality.
How to detect orphan pages
Having clear that this type of pages are not optimal for the organic positioning of our website, we must know how to detect them. A crawl with Screaming Frog or any crawler is not going to help us since these pages lack links, therefore, these tools are not going to be able to reach them.
Then we must try to detect by other ways this content that is not linked, we can do it in different ways:
- With an XML sitemap: in case our content manager is able to generate an XML sitemap file with the list of all the pages generated by our CMS.
- With Search Console: from this tool we will obtain the pages that generate impressions even if they do not generate SEO traffic. Therefore, it is a way to discover pages that, despite not being linked, are shown in the search results at some point.
- Google Analytics: we will obtain the pages that generate traffic from any source, not necessarily organic traffic.
- Importing externally linked URLs: these are pages that are linked from other domains, regardless of whether they generate traffic. We can do this with Google Search Console or any type of tool such as Majestic or Ahrefs.
- Obtaining the list of HTML URLs requested to our server from the server log.
With this we get to have all possible URLs and, above all, those that get traffic or receive authority from other domains. If we unify these URLs into a list and compare it with the list of URLs obtained from a full site crawl, we will identify as orphaned pages those pages that appear in the full list of pages but not in the crawl.

This is a task that, although we can solve relatively easily with an Excel file, is very laborious. This can be done more easily with crawlers such as Screaming Frog and Ryte.
With Screaming Frog
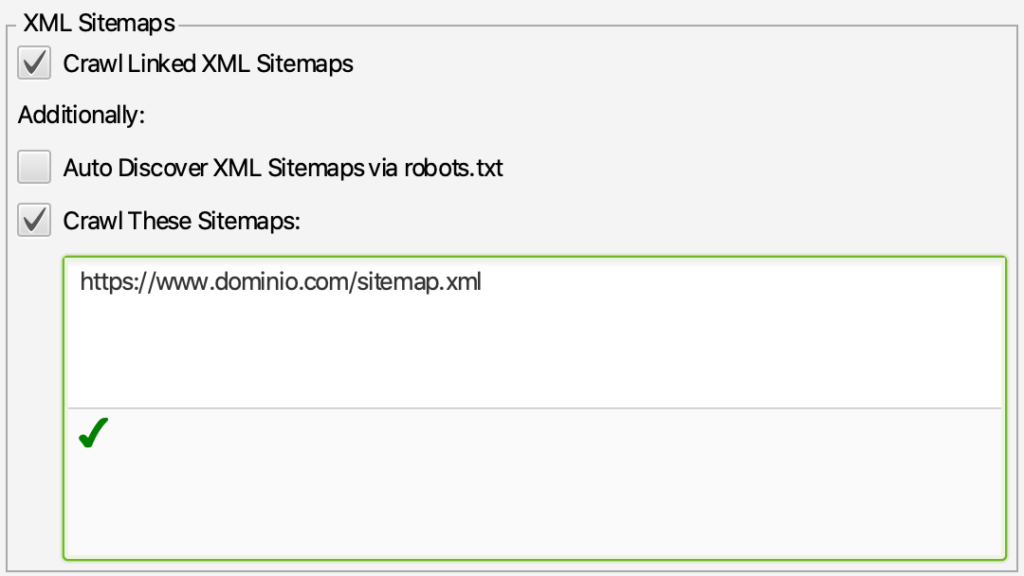
Screaming Frog allows us to select the XML sitemap file during the crawl to discover all the pages of our site, we just have to go to the Configuration menu -> Spider -> Crawl tab and in this dialog box scroll to the XML Sitemaps block where:
- Activate the Crawl Linked XML Sitemaps option.
- We activate Crawl These Sitemaps and in the box below we will enter the sitemap or sitemaps with the complete list of the URLs of our site.
But it also allows us to get more URLs from Google’s Search Console and Analytics tools. To do this we will have to go to the Configuration menu option and within this option we will have to deploy the different API Access options. Among these options we are interested in Google Analytics and Google Search Console, where we can connect Screaming Frog with both and select in both cases the option Crawl New URLs Discovered in the General tab of both menu options. In this way, Screaming Frog will crawl the URLs it discovers through both tools.
Once we have all the configuration, we only have to crawl our site with the addition of URLs from these three sources and, when finished, run a Crawl Analysis. Once the analysis is finished in the Sitemaps, Analytics and Search Console tabs, we can obtain the orphan URLs if we apply the Orphan URLs filter in all three cases. Thus, we will be able to know which orphan URLs have been detected from each data source.
With Ryte
The Ryte tool also has an option to download our XML sitemap. After the crawl and comparison with the list of URLs, we will get the orphaned pages in the menu option Website Success -> Links -> Pages without links.
In this case the tool does not allow to obtain URLs from other sources, but in most cases it will be enough to detect this type of pages without links as long as the XML sitemap file is correctly implemented.
How to fix orphaned pages
We will solve the pages without links in different ways depending on their chances of attracting traffic to our site:
- Pages with thin content or not relevant: if these pages are not necessary in our site, it is best to proceed with their de-indexing, deleting them from the CMS content inventory or simply unpublishing them. In either case, they should return a 410 or 404 code if an attempt is made to access them.
- Relevant pages on our website: in this case the solution is to stop them being orphans. It is necessary to integrate them into the information architecture of our site, linking them from the sections and contents that are relevant to it. This will increase the chances of attracting traffic with them.
- Halfway we will have the orphan pages that, although their content is not of quality, receive links from other domains: we will have to consider whether it is possible to improve their content and integrate them into the information architecture of our website. If we cannot improve them, it would be a good idea for the page to return a 301 code to the most similar page possible on our site to take advantage of its authority.
In short, it is about integrating into the information architecture the pages that are relevant to our site by including appropriate links to it from other sections of the website. In case we cannot do this, we will proceed to remove this content in the most friendly way for search engine robots.
These are relatively simple on page actions that will help us to make the most of our site’s traffic potential.



