

Written by Ramón Saquete
Index
When moving our website from HTTP/1.1 to HTTP/2, some Web Performance Optimization techniques continue to perform their function, while other techniques, which with HTTP/1.1 improved performance considerably, with HTTP/2 offer a negligible improvement or some may even worsen performance. This is something to keep in mind, given the importance of WPO for positioning and user satisfaction.
To understand when these situations can occur we must first understand how the HTTP/1.1 and HTTP/2 protocols work.
Operation of the HTTP/1.1 protocol
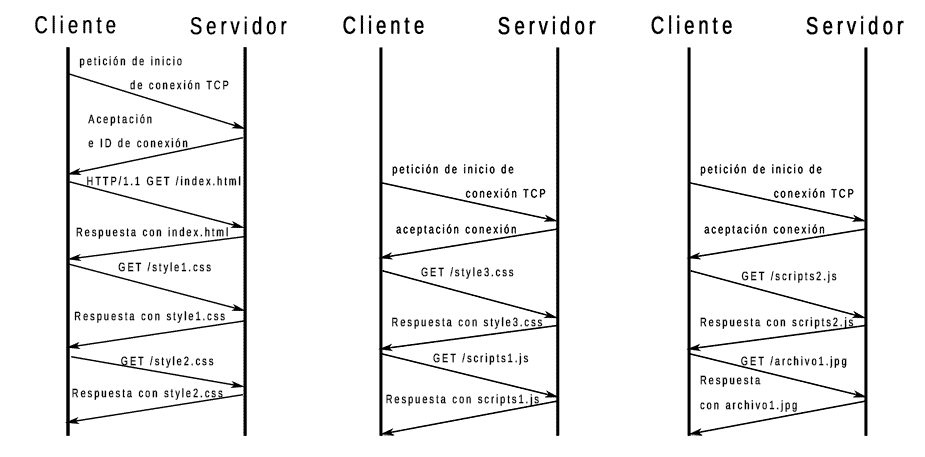
As you all know, web sites download many different files. When the HTTP/1.1 protocol has to request many files, it can only do so by requesting one after the other, so that if the browser knows that it has to request the files: file1.jpg, file2.jpg, file3.jpg, … what the browser does first is to request file1.jpg and until the request reaches the server and the server returns the complete file, the browser cannot request file2.jpg. Again, until file2.jpg arrives, it cannot request file3.jpg and so on. This causes the browser to spend quite some time stuck, unable to do anything, while the requests and responses travel through the network.
To try to minimize the amount of time the browser spends doing nothing with the HTTP/1.1 protocol, this parallelizes the download by opening several connections so that a browser with two open connections can request file2.jpg and file3.jpg at the same time, each for one connection, but it will not be able to request any more files until one of the two files has finished downloading, so that continues to spend time blocked. In addition, this solution causes open connections fight over the available transmission speed. The effect is worse the more open connections there are, so browsers limit the number of simultaneous connections to a low number, usually 5 or 6. The following image shows an example with three connections:
Operation of the HTTP/2 protocol
The HTTP/2 protocol allows requesting, at the same time and with a single connection, all the files needed by the web and returning them at the same time. Your network flow diagram looks like this:
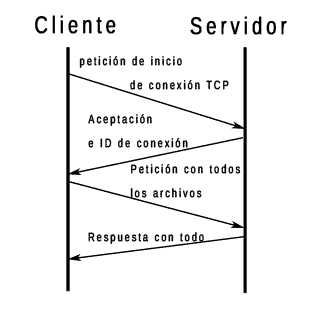
To do so, it applies serial multiplexing, which is a common technique in data transmission. This technique consists of splitting the files into pieces and sending a piece of each one, in this way and in this order: first piece of file1.jpg, first piece of file 2.jpg, first piece of file 3.jpg, …, second piece of file 1.jpg, second piece of file 2.jpg, etc.
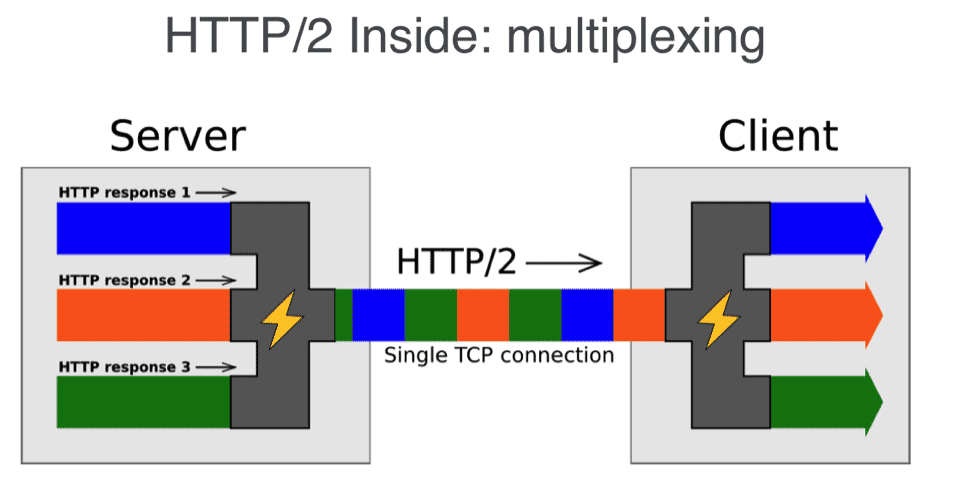
In this way and due to the way the protocol works, the browser does not spend so much time blocked and the transmission speed is used much better.
In addition, the browser can assign priorities to the transmission of files on those that are necessary to be able to paint the web as soon as possible, so that the server will send the most important pieces of files first. With the HTTP/1.1 protocol, something similar happened, since the files were ordered by priority in the browser request queue, but this did not ensure that they arrived in the same order at the server. With HTTP/2 files do not spend time waiting in the queue, but are sent directly and download priorities are managed much better, because the server knows which ones to send back first.
The HTTP/2 protocol introduces other optimization improvements, such as compressed headers, binary formatting and elimination of redundant information, which reduce the amount of information to be transmitted, but none of them are as effective as multiplexing. The only changes we have to take into account to know which optimization techniques are obsolete with this new protocol are multiplexing and the fact that HTTP/2 always keeps the TCP connection active.
When can HTTP/2 be used?
Both client and server must allow HTTP/2 for this protocol to be used. Currently all browsers allow HTTP/2, but this is not the case with the spiders used by search engines to crawl, including Googlebot, so the web will be indexed by downloading with HTTP/1.1. Another requirement is that the TLS protocol must be used under HTTP/2 to provide HTTPS. This is a restriction imposed by the browsers to promote the use of HTTPS, since it is the browsers that do not allow the use of HTTP/2 without security, while the specification and the servers do allow it.
In addition, it is necessary that the server allows the use of a TLS protocol extension named ALPN (Application-Layer Protocol Negotiation)which is used to negotiate the application layer protocol and in this particular case, to negotiate with the server whether to communicate with HTTP/2 or HTTP/1.1. Alternatively to this extension, the NPN (Next Protocol Negotiation) protocol was previously used for the same purpose but, on 05/31/2016, Google updated its browser to allow only ALPN and this forces servers to have an updated version of the operating system to use this and be able to enjoy HTTP/2. Google did this because ALPN is faster as it avoids round-trip cycles compared to NPN.
Despite all these requirements, HTTP/2 has already replaced HTTP/1.1 in more than 25% of websites and is growing at about 10% per year, and there are rumors that Googlebot could start using it any day now.
WPO techniques made obsolete by the use of HTTP/2 protocol
Add Keep-Alive header
The server response header “Connection: Keep-Alive” causes the HTTP/1.1 protocol to keep the TCP connection open after downloading a file, so that the TCP protocol does not have to open and close the connection with each downloaded file. This is important, because the TCP protocol causes a round-trip cycle to open and close the connection, in addition to the one needed to transfer the file with the HTTP protocol (round-trip cycles should be avoided because the transfer of data over the network is one of the tasks that takes the longest to load the web). This happens as follows:
- First cycle:
- The TCP protocol sends a request from the client to the server to open the connection (one-way).
- Returns the response from the server with acceptance and a connection identifier (return).
- Second cycle:
- The HTTP protocol requests a file from the client (one-way).
- The server returns the requested file (return).
- Third cycle:
- The TPC protocol requests to close the connection from the client (one-way).
- The server agrees to close the connection (return).
If you then need to download another file, all the steps are repeated, but if you leave the connection open, you only need to request the new file.
The HTTP/2 protocol always leaves the connection open and ignores the “Connection: Keep-Alive” header, so adding this header when our website uses HTTP/2 only makes the headers unnecessarily longer.
Reduce the number of requests
There are different WPO techniques to reduce the number of files requested. As I have already mentioned, when requesting several files with HTTP/1.1, the browser crashes, but with HTTP/2 this no longer happens, so these techniques are obsolete. But better, let’s analyze what happens with each of them:
Unify CSS and JavaScript files
Unifying CSS files is not going to be a major improvement with HTTP/2, as it was with HTTP/1.1, but if we are already doing it, we can leave it, because the HTML is slightly smaller with fewer file references. However, unifying JavaScript may make more sense, because this way we can load the unified file asynchronously in the header, without fear of errors due to dependencies between the files. So by unifying JavaScript, we gain nothing by reducing requests, but we gain by loading it asynchronously with the “async” attribute, since this way the painting is not blocked, whereas with synchronous loading, when the browser encounters the <script> you have to wait for JavaScript to run before you can continue parsing the.
CSS Sprites
This is a technique that consists of unifying several images into one and then cropping them by CSS and putting them in place on the page. This technique is no longer effective and the only thing we can achieve, if we are lucky, is that by unifying visually similar images, the unified file occupies a little less space than the individual images. But this improvement is usually negligible, so CSS Sprites is no longer a technique worth applying for optimization, but if you want to apply it for code organization issues, that’s another matter. If applicable, take care not to merge images that will not be used, increasing the file size unnecessarily. I personally do not recommend it, because when making changes, images that are no longer used in the sprites are often forgotten.
Embedding images with DATA URIs and CSS code in HTML
Embedding images with DATA URIS consists of embedding the images in text strings in the CSS file or directly in the HTML, instead of linking them from the CSS file. Likewise, including the CSS in the HTML with the tag <style>, avoids linking it in a separate file. These techniques can be applied for two reasons, to reduce the number of requests and/or to advance critical resources. The first reason is obsolete with HTTP/2 but advancing critical resources is not. Critical resources are those files that are going to be used for painting the important parts of the page (mainly what is seen above the fold or without scrolling down).
Embedding an image means that the browser does not have to request the file that was previously linked from it, thus avoiding a round-trip cycle. For example, suppose we have an HTML file, which links to a CSS file that links to an image. This generates three cycles with any protocol, since each file will necessarily be requested one after the other, since it is necessary to have the previous one to know which is the next one. But if we embed the image in the CSS, when we download it we will already have the image, so we save a cycle. Or we could embed the CSS in the HTML with the tag <style> and with the image, so that we would not have to download additional files, once the HTML is downloaded, saving two cycles. This technique has the problem that the images and CSS attached directly in the HTML are not saved in the browser cache, so it is not recommended for sites with many recurring visits. So these techniques, used well, still make sense.
There is a new technique for preempting critical resources to be downloaded with the HTML that does allow the browser to cache the preempted files. This technique is called HTTP/2 Server Push, but I will explain it in depth soon.
Parallelizing the number of simultaneous requests
As we have already seen, when browsers use HTTP/1.1, they parallelize requests by opening several connections which, depending on the browser, are limited to 5 or 6, with requests being launched at the same time for each of them. This limitation is made by the browser per domain, so we can increase the number of connections it uses if we use several domains. There are two techniques that do this:
Domain sharding
This technique consists of creating several subdomains to link the different resources of our website. For example, for www.humanlevel.com, we could have js.humanlevel.com, css.humanlevel.com, img1.humanlevel.com and img2.humanlevel.com. Thus we have a subdomain from which we will link the JavaScript files, another one for the CSS and two for the images.
By applying this technique with HTTP/1.1 we can obtain some improvement, being careful not to exceed the number of subdomains and testing, but with HTTP/2 not only we will not obtain any improvement but it will worsen the performance. This is mainly because this technique introduces additional time to resolve each of the subdomains to their corresponding IPs. With HTTP/1.1 this loss was compensated with the reduction of time spent by the blocked browser, but with HTTP/2 we do not have these blocks and we will waste time with DNS resolution of additional domains and establishing more connections unnecessarily. So if we use HTTP/2 and use this technique, it would be better to remove it.
CDN (Content Delivered Network)
A Content Delivered Network consists of a worldwide network of reverse cache proxies (servers that cache the content of a main server) connected directly to core routers with the same IP. The core routers are the Internet’s core routers, and since these proxies are directly connected, access is obtained faster than to any server, since to reach a server you have to go through a hierarchy of routers that goes from the core router to smaller and smaller routers, until you reach the router connected to the server’s network. In addition the core routers are configured to balance requests to the proxie cache of the fastest or nearest CDN.
So by using a CDN we will access the closest and fastest server of the client that is requesting the web, so this technique is still applicable with HTTP/2. However, CDN is usually used to serve only static files from various subdomains (images, CSS and JavaScript) and serve dynamic files (HTML) from our server. This is not interesting with HTTP/2, because we are doing the same as with domain sharding, which we had seen that it worsens performance, so we should avoid having several subdomains.
The ideal situation with HTTP/2 is that the CDN serves all resources under the same domain (the web domain itself). Although, serving HTML and all static files from the CDN is an advanced configuration that only some CDNs offer and should only be applied when we can cache the contents for some time.
If we have no choice but to use the CDN to cache only static resources, either because the CDN provider does not offer another service or because we want to have up-to-the-minute information, we should use a single subdomain of the CDN.
In any case, we must make sure that our CDN provider supports HTTP/2, so that the improvement provided by using the CDN is worthwhile.
Conclusions
HTTP/2 is a significant improvement in web performance, but to take advantage of this improvement we must avoid using domain sharding and CDNs under HTTP/1.1.
Instead, performance will improve when using a CDN, with HTTP/2 and the web domain itself or, it could improve, if using the web domain and a single subdomain. Embedding images and CSS in the HTML will also improve performance, if these techniques are used with critical resources and sites with few recurring visits. Likewise, it is a good idea to unify JavaScript files if the purpose is to be able to load them asynchronously.
The techniques of unifying CSS files and CSS Sprites, although they are obsolete and the improvement they offer is no longer worth it, will not harm us, so we can leave them if we already have them implemented and, in addition, spiders like Googlebot, still use HTTP/1.1, so if we continue using these techniques of file unification, we will be improving the performance for them.



