

Written by Fernando Maciá
Index
- What are large language models (LLMs) like ChatGPT?
- What is a Knowledge Graph and how does it differ from LLMs?
- What is Retrieval-Augmented Generation (RAG)?
- Anatomy of the results in the Google SGE Dashboard
- How does Google SGE affect traditional results?
- What type of queries Google SGE does not solve: YMYL
- How could Google SGE impact SEO?
- How we can prepare for Google SGE
- Should we block IAs?
- Some examples of Google SGE
- Conclusion
- Additional references
Although Google SGE is not yet available in the European Union, at Human Level we wanted to get a head start and investigate this new development as much as possible in order to be able to give our clients an answer on the impact it could have on their businesses. We have analyzed hundreds of searches and we tell you below our impressions: what is Google SGE, what impact it could have on users’ search habits, on Google’s role as a generator of quality organic traffic and on the way we do SEO. It’s a bit long, but I warn you, it’s worth it. Will you join me?
Google SGE (Search Generative Experience) is a new way of responding to user searches by combining the power of large language models (LLM) such as chatGPT with the real-time crawling capabilities of a search engine like Google to improve the reliability of responses and cite supporting documents.
Cathy Edwards was in charge of presenting Google SGE during the Google I/O conference on May 10 and until recently it was only available upon authorization to join the Google Search Labs program in the United States, India and Japan. Since last November 9, however, it has been deployed to 120 countries, although Canada or the European Union are not included, probably due to their more restrictive legislation on data protection and regulation of systems employing Artificial Intelligence (AI).
Accessing Google SGE results from a country not yet included in the program requires a Google profile authenticated by a local cell phone from one of those countries and browsing with a login IP consistent with this authentication.
Google SGE involves two key concepts in its development:
- Large Language Models (LLMs).
- Retrieval-Augmented Generation (RAG).
Let’s see what they are.
What are large language models (LLMs) like ChatGPT?
An LLM (Large Language Model) is a type of artificial intelligence model designed to understand and generate human language automatically. Basically, it works like an artificial brain that processes large amounts of text to learn language patterns and structures, and use that knowledge to predict and generate new text.
ChatGPT is a specific type of LLM called GPT (Generative Pre-trained Transformer) that was developed by OpenAI. GPT is a language model based on the Transformer architecture, originally created by Google, which uses neural networks to process large amounts of text and learn how to generate new text.
How LLMs are trained and learn
ChatGPT learns from the analysis and identification of patterns in large datasets provided by third parties or publicly available online. One of the articles that best explains how generative artificial intelligence works is this one from the Financial Times.
The datasets used to train GPT 3.5 are:
- Common Crawl: is a dataset created by a non-profit organization of the same name. Common Crawl employs a bot whose user-agent is CCbot/2.0 to crawl publicly accessible content online. CCbot respects the guidelines set forth in the robots.txt file as well as in the CCbot meta tag, providing a way to block crawling, indexing or tracking links on a page. However, blocking CCbot now does not mean that previously crawled content that is already part of its dataset will be removed. We would only be preventing the crawling of new content. It is important to note that datasets such as Common Crawl are employed by advertising companies to categorize content and segment the advertising that appears in it. Blocking CCBot access could have an impact on some advertising networks.
- WebText2: is an OpenAI proprietary dataset obtained from crawling websites with more than 3 votes on Reddit, on the assumption that the content of these sites is reliable and accurate. The original version of WebText contained about 15 billion tokens (minimum unit of information) while WebText2 is an extended version with 19 billion tokens and is the one that OpenAI has used to train GPT 3 and GPT 3.5. The WebText2 dataset is private and not publicly accessible. However, there is a publicly accessible OpenWebText2 version where we can check the source URLs of the data. It is not known which user-agent uses WebText, so it is not possible to block its access via robots.txt or at the server level.
- Books1
- Books2
- Wikipedia
Of these, only Common Crawl and Wikipedia have their direct origin in online data crawling.
GPTBot is the User-agent of ChatGPT. If we don’t want it to use our content as training data it can be blocked through robots.txt.
Currently, ChatGPT cannot crawl online content. Its responses are based on training from datasets collected up to a given date. However, there are already browser plug-ins that allow its models to read information directly from online sites, as well as other recently launched applications.
The ChatGPT model implemented by Bing uses the information obtained from a “traditional” search to summarize, synthesize and extract the most valuable information from the content found in those results.
LLMs fragment the contents crawled in these datasets into basic units of information or tokens which can be encrypted. They then observe when these units are more or less close to each other by analyzing large volumes of text. The process generates a vector that stores the probabilities of finding that word more or less close to other words. Finally, the Transformers process not single words, but sentences, paragraphs or even entire articles by analyzing the relationships between all their parts . By taking context into account, they can better understand the meaning of each word.
Before proceeding further, it will also be useful to understand what a Knowledge Graph is and how it differs from these large language models (LLMs).
What is a Knowledge Graph and how does it differ from LLMs?
Knowledge networks are a type of network. Graphs are simple structures that use nodes (or vertices) connected by relations (or edges) to create high-fidelity models of a domain.
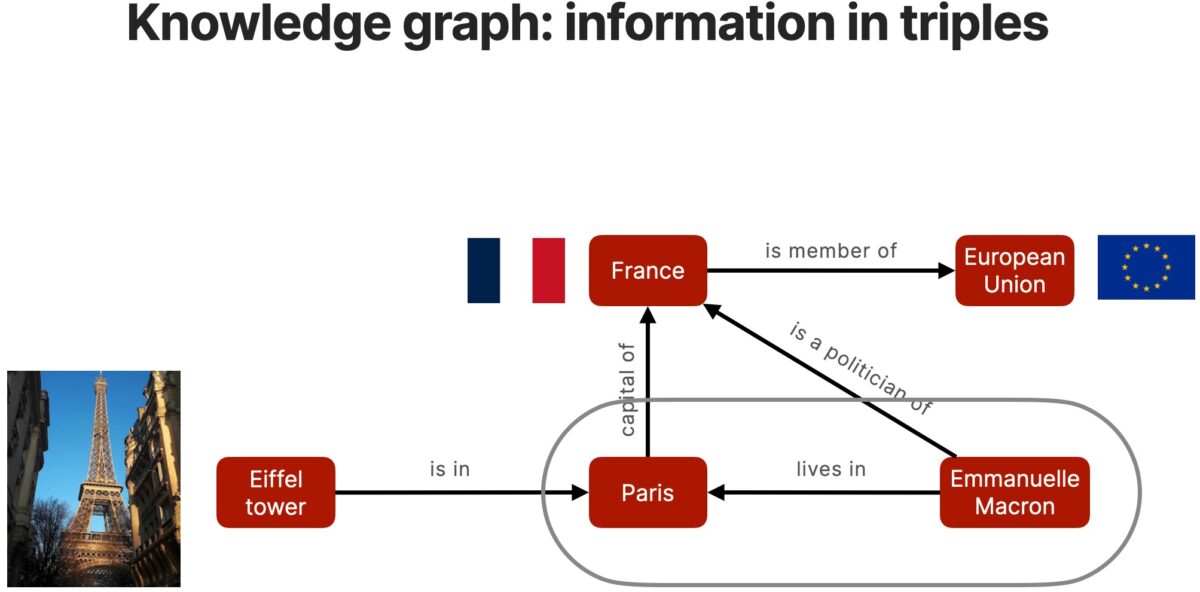
Google introduced Knowledge Graph formatted results in May 2012 and has gradually increased the type and number of entities for which it returns these types of results.
If we compare in parallel the results obtained from a large language model such as ChatGPT with those returned by Google’s Knowledge Graph, we can notice the main differences between these two ways of storing and retrieving information:
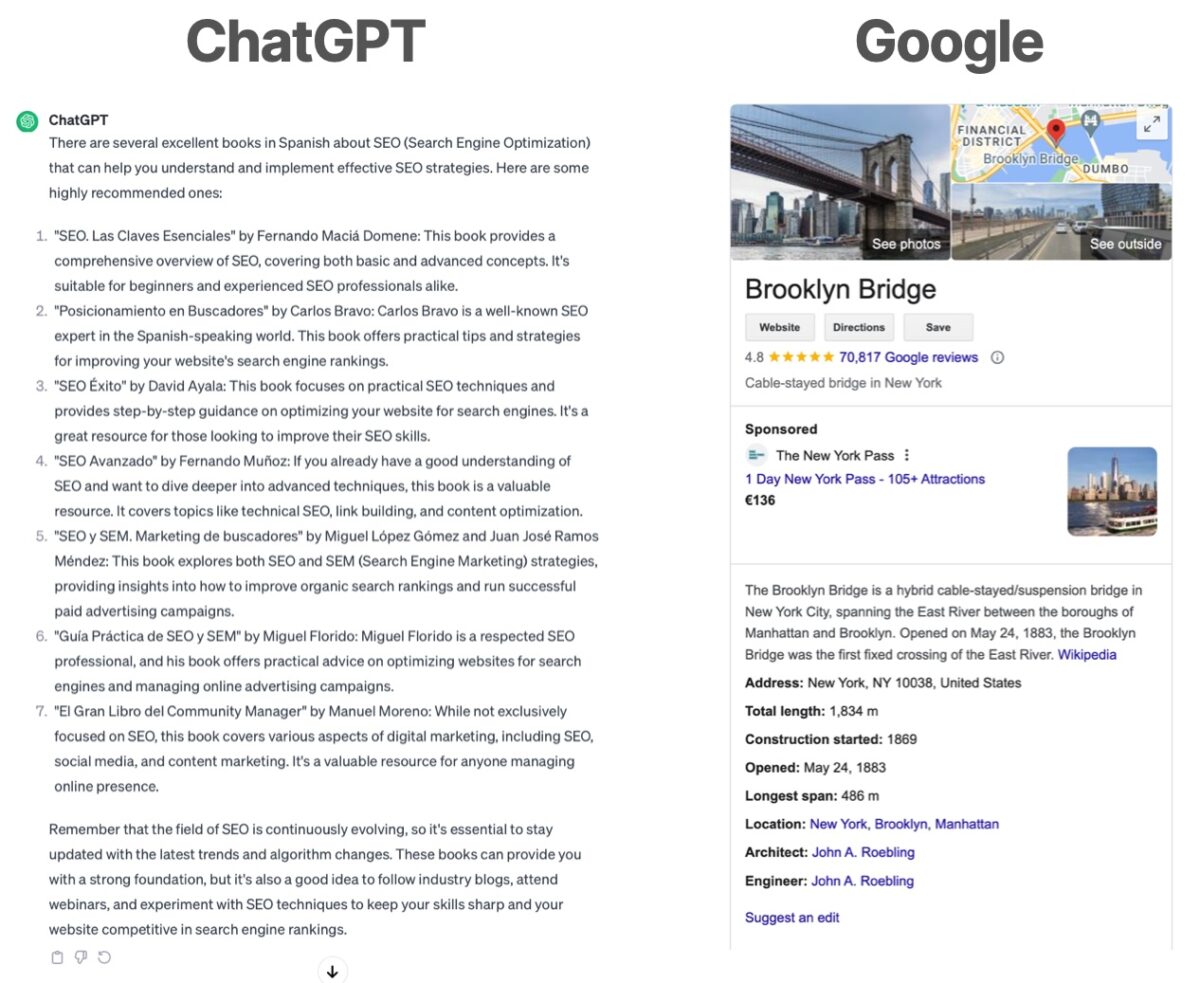
Some advantages of the knowledge graph over an LLM:
- General information vs. specific information: on the one hand, chatGPT and similar models are assumed, in principle, to have generic and global knowledge, while Google’s knowledge graph is only presented for informational searches of entities that Google has already recognized and whose relationships are based on data. We would have on the one hand an implicit knowledge on the part of LLMs while knowledge graphs present a more structured knowledge.
- Hallucinations vs. accuracy and reliability: LLMs are predictive language models that generate content from an instruction (prompt) but whose information may be totally erroneous (in the image above, most of the books referenced by ChatGPT do not actually exist and for those which do, authors are not the right ones). On the contrary, the information presented in Google’s Knowledge Graph is generally reliable and endorsed by the source websites linked from it.
- Black box vs. interpretable model: large language models apply neural networks that “learn” in a way that is difficult to predict and control, functioning as a “black box” while structured knowledge graph information is easy to interpret, validate and predict.
- Lack of updating vs. knowledge in permanent progression: large language models are trained on datasets existing at a given time, so they lack the possibility of updating their knowledge base in real time, while the information reflected by the knowledge graph can be permanently updated.
However, LLMs are ahead of knowledge graphs in some aspects as well:
- General knowledge vs. incomplete data: in principle, we can ask an LLM on any subject matter, whereas Google only presents the knowledge graph panel for a limited number of entities.
- Natural language understanding: by their very operation, large language models are capable of answering questions posed in natural language, even adjusting their response to user’s reasking. In contrast, a knowledge network only presents the information available for the identified entity, but does not give the user the option to ask follow-up questions.
Having seen the strengths and weaknesses of large language models (LLMs) with respect to other forms of information storage and retrieval such as knowledge graphs, let’s see what makes Google SGE different from chatGPT and why this difference is fundamental to:
- Safeguard Google’s reputation as a reference source of reliable information, minimizing the possibility of LLMs’ own hallucinations.
- Introduce generative artificial intelligence into search results while respecting intellectual property rights and the claims of content creators.
- Avoid losing prominence as a source of quality organic traffic for websites.
- Keep your own monetization model (Google Ads) intact.
All this has to do with recovery-augmented generation, or RAG.
What is Retrieval-Augmented Generation (RAG)?
Retrieval-augmented generation (RAG) is a paradigm in which relevant documents and/or data are collected from a knowledge graph based on a user’s query. This data is added as clues or reliable data to automatically create a more accurate prompt. This improves the accuracy and reliability of the language model response (LLM).
Google has applied this paradigm to SGE probably by combining different proprietary models such as REALM, presented in February 2020, RETRO, presented two years later, RARR, published in May 2023, FreshLLMs, published in a paper in October 2023.
The main advantages of applying the RAG paradigm are:
- Improves response accuracy and largely prevents hallucinations.
- It allows the attribution of the information provided to its original sources, as well as linking them to make it easier for the user to dig deeper into the desired aspects of the search.
- It avoids the limitation of LLMs to the last update date of the datasets they use as training data.
Anatomy of the results in the Google SGE Dashboard
The results returned by Google SGE take on different layouts depending on the search intent. Below we show what this result looks like for an informational search:

This arrangement, moreover, has been evolving since it was introduced. Initially it did not include links to the referenced websites, which triggered a large outcry from content creators. It was also clearly shaded to differentiate it from traditional organic results and, for those searches where it did appear, it was fully displayed from the start, occupying almost the entire above-the-fold.
Over the months that it has been in operation, we have seen how Google has included the secondary carousels of results accessible through links that display them under each paragraph. It has also been softening the initial shading until it is almost imperceptible and, finally, it shows the panel only partially unfolded and it is up to the user to decide whether to finish extending it or not.
Being a functionality still in testing and that can profoundly affect both the search habits of users, as well as Google’s own role as a generator of organic traffic and its main monetization mode, Google Ads, it is logical that they have tested multiple ways and solutions to integrate this new panel in the results pages.
How does Google SGE affect traditional results?
In some cases, the impact of Google SGE will be close to zero, while in others, it is expected to impact the click-through rate (CTR) in a similar way as the featured results have done, significantly decreasing the number of clicks on the first positions.
In the tests carried out, we have identified different cases:
- AI-powered snapshot not available: the SERP is the traditional one and does not present the possibility of generating an AI-powered snapshot.
- Google SGE results panel not shown at startup, but available through the Generate button.
- Google SGE results panel partially displayed at startup.
Previously, we detected two other cases that have now been unavailable for some weeks:
- Google SGE results panel not shown at startup, but available through the Converse button : this button is no longer shown.
- Google SGE results panel fully displayed on startup: we found no cases where the SGE results panel is fully displayed from start.
In a much larger sample of searches with a mix of informational, transactional and local keywords, Michael King recorded that Google featured the SGE panel in nearly 40% of searches.
What type of queries Google SGE does not solve: YMYL
In general, Google SGE does not show results for searches related to Your Money, Your Life, as in this case the results could have an impact on the physical or financial health of users. Since the content generated by Google SGE is not a verbatim copy of any external result, Google itself would be legally liable for the accuracy or reliability of the information displayed, which in these cases implies a great risk.
The topics directly affected are:
- Health or physical safety of the user.
- Financial security.
- Society as a whole: i.e. conflictive or controversial issues that may affect the stability of society, trust in public institutions, etc.
For example, if we search for“what type of mortgage is assumable,” Google does display the SGE results panel but includes a disclaimer message: “This is not professional financial advice. Consultation with a financial advisor for specific recommendations regarding your particular circumstances would be best.“. If, in addition, we further specify the search,“what type of mortgage is affordable if I am 50 years old“, then Google does not even present the SGE panel as an option.
Other examples:“what type of checking account should I open to save money” does present SGE panel accompanied by the aforementioned disclaimer. If I specify something else:“which credit card is better if I have a bad credit history“, then it no longer generates SGE results.
For more conflicting searches:“should I invest my savings in bitcoin”, obviously Google stays safe and does not show the SGE panel.
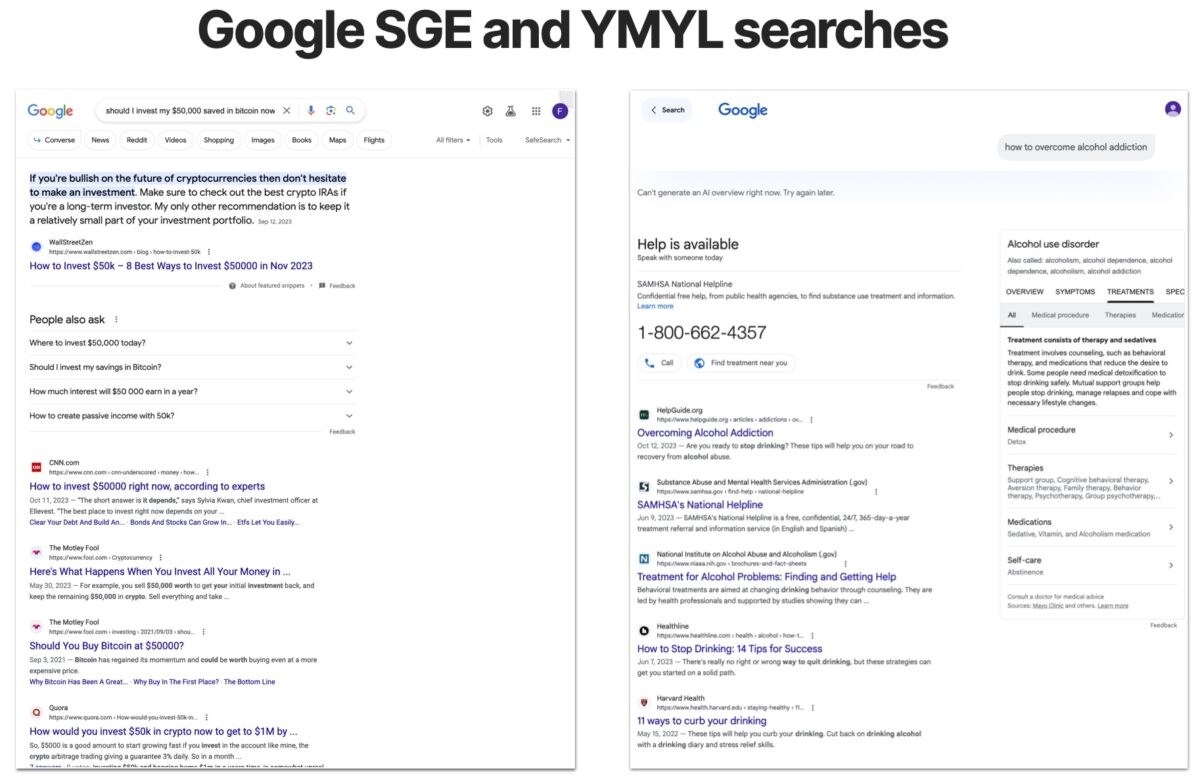
The same is true for searches for medical advice, for example:“how could I lose three pant sizes in two weeks” or controversial“why should the United States ban the sale of assault weapons“. In most cases, Google will not present the SGE results panel and when it does, it will always be accompanied by some sort of disclaimer message.
How could Google SGE impact SEO?
To really assess the impact of Google SGE we will have to wait until it is launched in more countries and available to the general public. At the moment, it is only available in 120 countries, not in Europe or Canada, and only for a group of users who have opted for the functionality in their Google profiles.
However, even if Google displays these types of results to the general public, we will encounter varying degrees of impact:
- To begin with, not all searches generate SGE results: for searches where no SGE results are generated or where the user must “force” the panel to appear by clicking on the button that generates them, the impact on organic traffic will be very small. Users will click on the result that most directly matches their search intent, before making an additional click and waiting a few seconds for Google to complete the SGE panel (in the cases where it finally does show it, which is not always the case).
- In direct response informational searches: we can expect a drop in CTR similar to what we get when Google presents aFeatured Result(featured snippet). In these cases, much will depend on whether the extract presented by Google in the SGE panel is considered sufficient to satisfy the user’s search intent or not.
- In transactional searches: the customer journey will be shortened. We can expect fewer clicks on product category pages (that part of the decision process is moved to the search engine pages) and more clicks on product detail pages, although with a higher conversion rate, since the user will have had the opportunity to compare and contrast advantages and disadvantages already in the SGE results panel itself.
- In any case, the CTR (even for position 1) will decrease, as the organic results are “pushed” further down by ads and the SGE panel. From now on, the objective of positioning is much broader and will consist of achieving visibility in the multiple formats and widgets that make up Google’s results pages. Gilad David Maayan expects a negative impact of 30 to 60% less traffic.
- The proportion of targeted searches will increase: search engines have “trained” us in a certain way to formulate our searches in order to obtain the results we want. The much more conversational interface of Google SGE, where we are encouraged to pose our questions or click on some of the suggested ones, and the results are also presented in a natural language will encourage the adoption of more targeted and natural searches. This means that product detail pages (PDP) or specific content pages (news, for example) will probably register a higher volume of organic traffic to the detriment of product family or content category (thematic) pages. Long-tail positioning will be much more important.
- Being in the first positions in organic results increases the probability of being one of the websites referenced in the Google panel. SGEIn the aforementioned study by Michael King, the sites ranked first, second and ninth most frequently appeared in the SGE results and, in most cases, Google includes up to six of the top ten results in this panel.
SEO tools will have to adapt: ranking in the top ten organic positions is becoming meaningless. It is an unknown how Google SGE will impact the expected CTR for each position and therefore the estimated clicks for each keyword.
How we can prepare for Google SGE
A new opportunity to achieve visibility
Google SGE is both a threat to the CTR obtained for the first organic results and an opportunity to gain visibility in a new result format that could mark the future of Google as a search tool. Everything we apply to position a website is still fully in force but, in addition, being one of Google’s reference sources to compose its AI-driven results becomes an additional key objective. In tests carried out by Human Level and other consulting firms, we have already found that the best positioned websites are the ones that most frequently become the reference cards in the various Google SGE carousels.
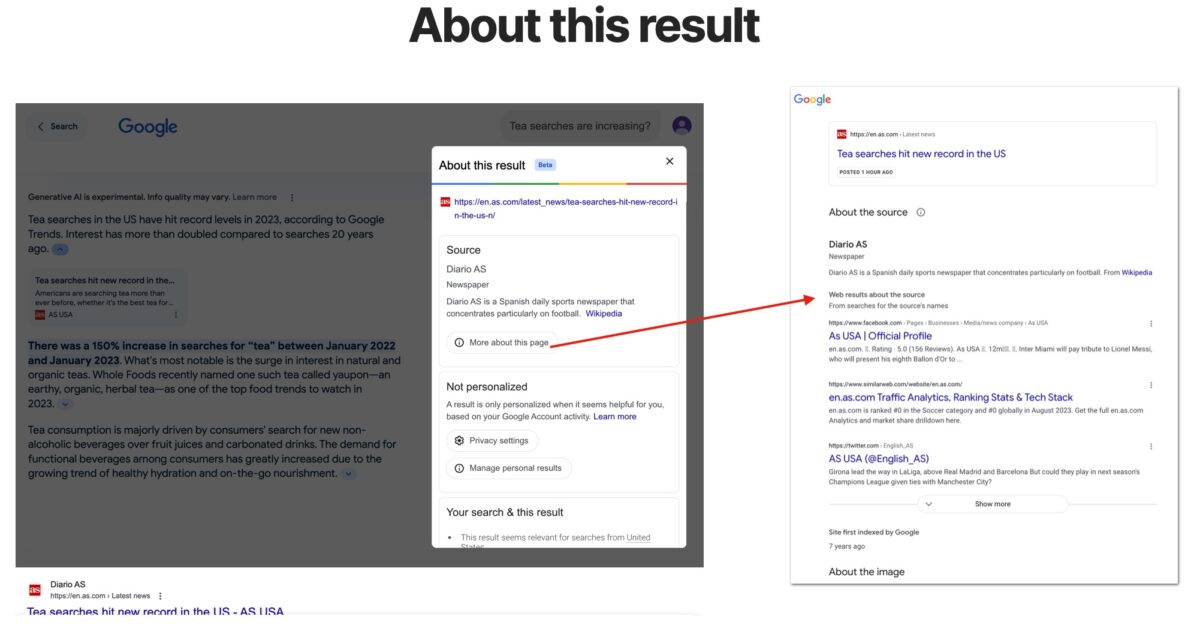
By clicking on the About this result option, Google displays information that justifies why that content and that website have been chosen as a reference and it is easy to see how the now famous E-E-A-T of experience, expertise, authority and trust are the indicators that can make the difference. Specifically for the media, we began to familiarize ourselves with these indicators through the Trust Project. And we see how these trust indicators have been extrapolated and applied to corporate, travel, e-commerce, market places, etc. sites as well. So we must know and apply as much as possible all the recommendations to improve the EEAT of our website.
More than an featured snippet
To some extent, the Google SGE panel is an evolution of the featured result or featured snippet. In the case of the featured result, Google selects what it considers to be the optimal result for a search, extracting the answer from its content and reproducing it verbatim at the top of the results. The Google SGE panel takes over this prominent position but, in this case, instead of extracting the information literally from a single result, it identifies the consensus among several websites that it takes as a reference and synthesizes the essence of the information provided by applying the generation of an LLM. In both cases, the key is to become Google’s reference as a source of this information, as this is the only way to place our link in this privileged area of the SERP.
Take advantage of the long-tail
As we said at the beginning of the post, Google SGE’s conversational interface will gradually accustom users to pose queries in a more natural and specific way for their needs. There is a great opportunity to position content for these specific searches that, although with lower search potential, will attract high quality visits. But not only that: let’s not forget the suggested or free follow-up questions with which Google encourages users to dig deeper into their searches. If the questions in the PAA (People Also Ask) blocks have inspired us to develop new content, the suggested follow-up questions will also help us to develop specific content to accompany our users in their purchasing decision process. We should carefully analyze the follow-up questions proposed by Google for each of our key searches where the SGE results panel does appear.
Control the CTR in your results
Check for discrepancies between average position and CTR achieved in Google Search Console:
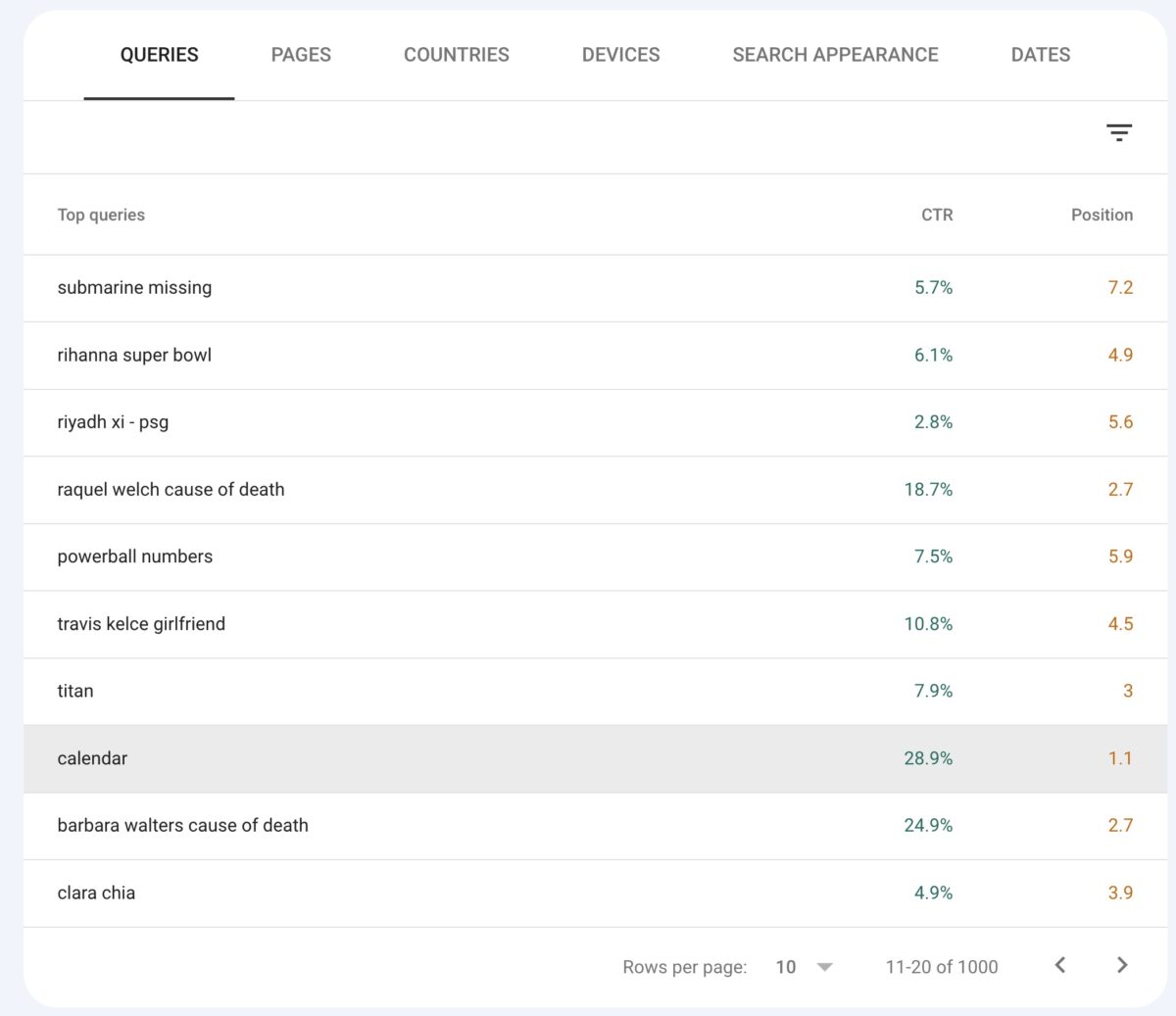
A good position with an unusually low CTR could indicate a high impact from either a featured result or a Google SGE panel.
Analyze for which searches does SGE appear and why
Monitor the results pages for each of your keywords and check when the Google SGE panel appears and when it does not. The biggest impact will obviously come from searches where Google SGE does appear.
Once you have checked these keywords, check which are the most frequently linked domains as a reference in the main carousel of the SGE panel or in one of the secondary carousels. Click on About this result and try to find out which indicators of trust and thematic authority are leading Google to take that domain as a reference:
Should we block IAs?
Finally, one might ask whether we should block LLMs and other artificial intelligences from accessing our content. At the moment, our opinion is no, for these reasons:
- We are in the early stages of using these AI models, and it has not yet been defined (let alone regulated) what should be an appropriate and fair use in relation to the intellectual property of the training data.
- Depending on how this is regulated, ChatGPT and the like could include attribution mechanisms and provide links to the original source of the content, acting as an additional source of web traffic.
- It is still too early to predict for which search categories LLMs may become a first choice for users. So far, the lack of updating of the datasets and the “imaginativeness” of many of their answers are arousing skepticism and making them appear as an unreliable source of information.
- Potential legal problems arising from the accuracy and reliability of the information provided could make attribution to third parties the best option to avoid possible lawsuits.
However, according to Originality.ai, 20% of the world’s top 1,000 websites are already blocking GPTbot as of September 2023. Among them, many online media sites and some of the most important e-commerce portals, such as Amazon or the New York Times.
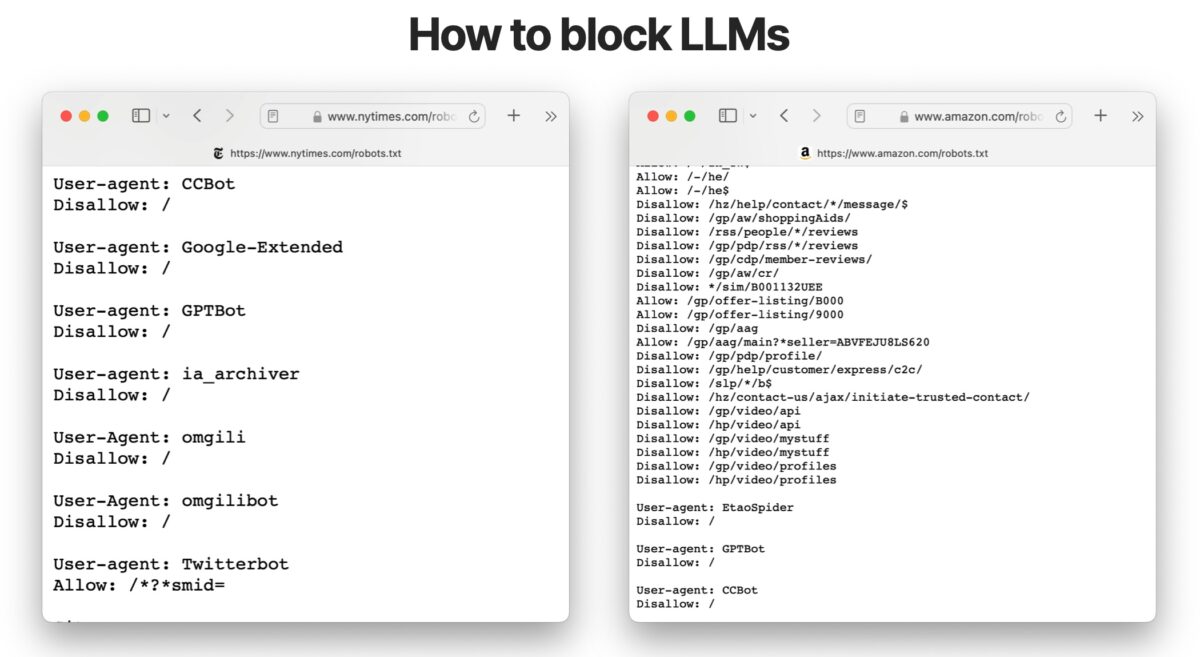
In any case, to prevent our website from appearing in the Google SGE panel we would have to block Googlebot completely, so that would also leave us out of the traditional organic results.
Some examples of Google SGE
The results panel presented by Google SGE does not have a unique layout, but adopts a different structure depending on the type of search entered. The most representative models are those shown for informational, transactional, local or travel-related searches.
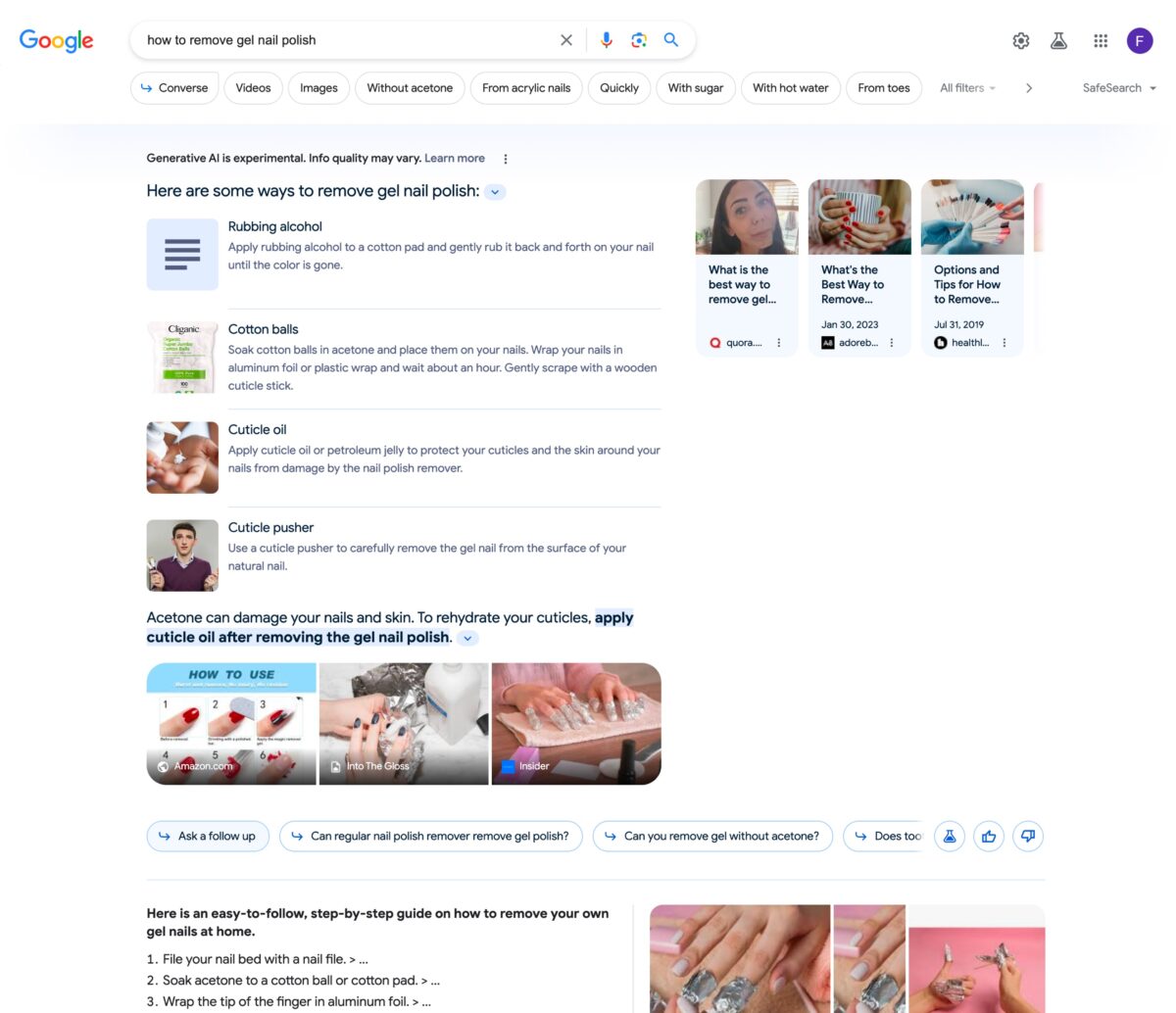
Information search
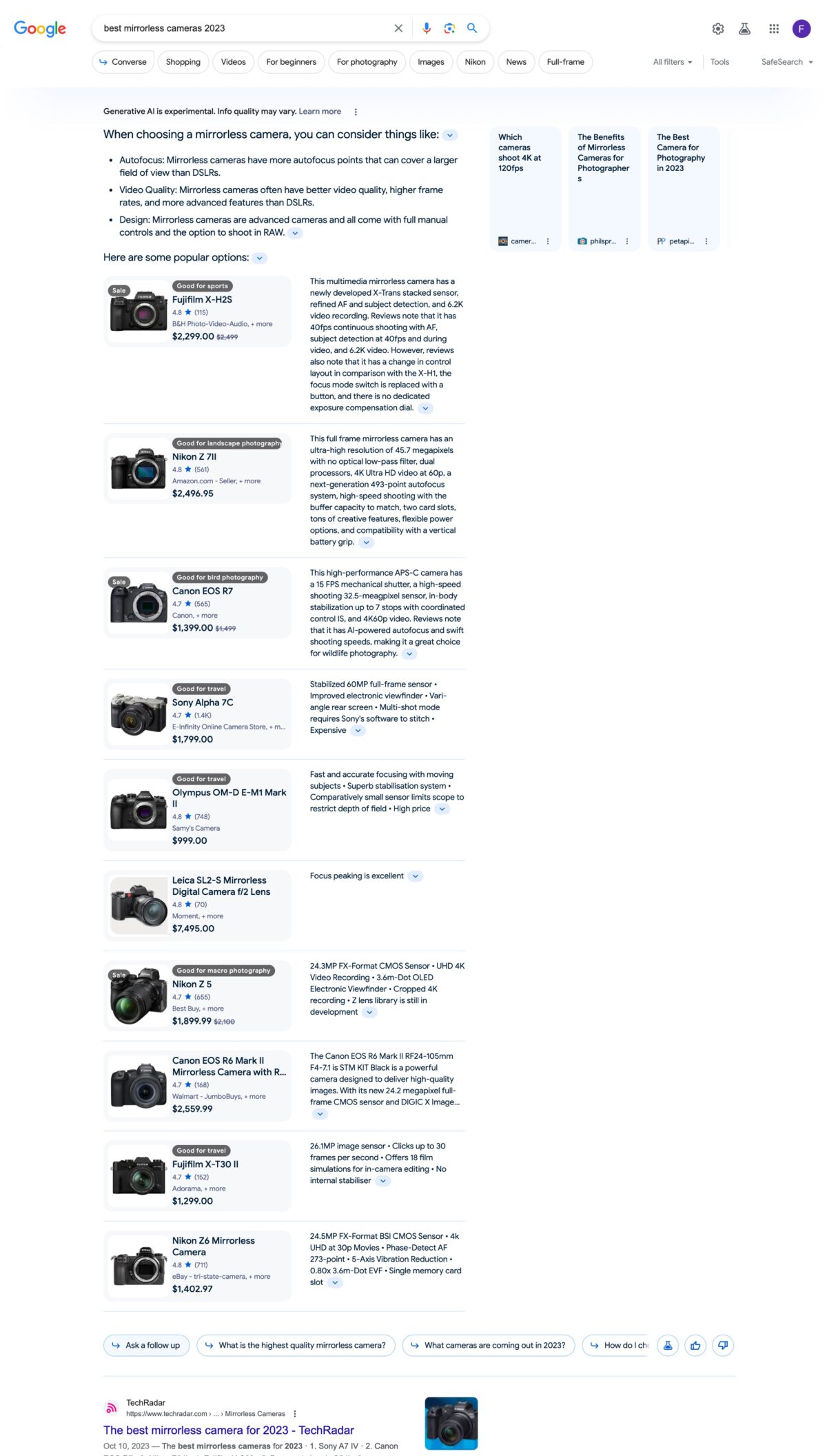
Transactional search
Local search
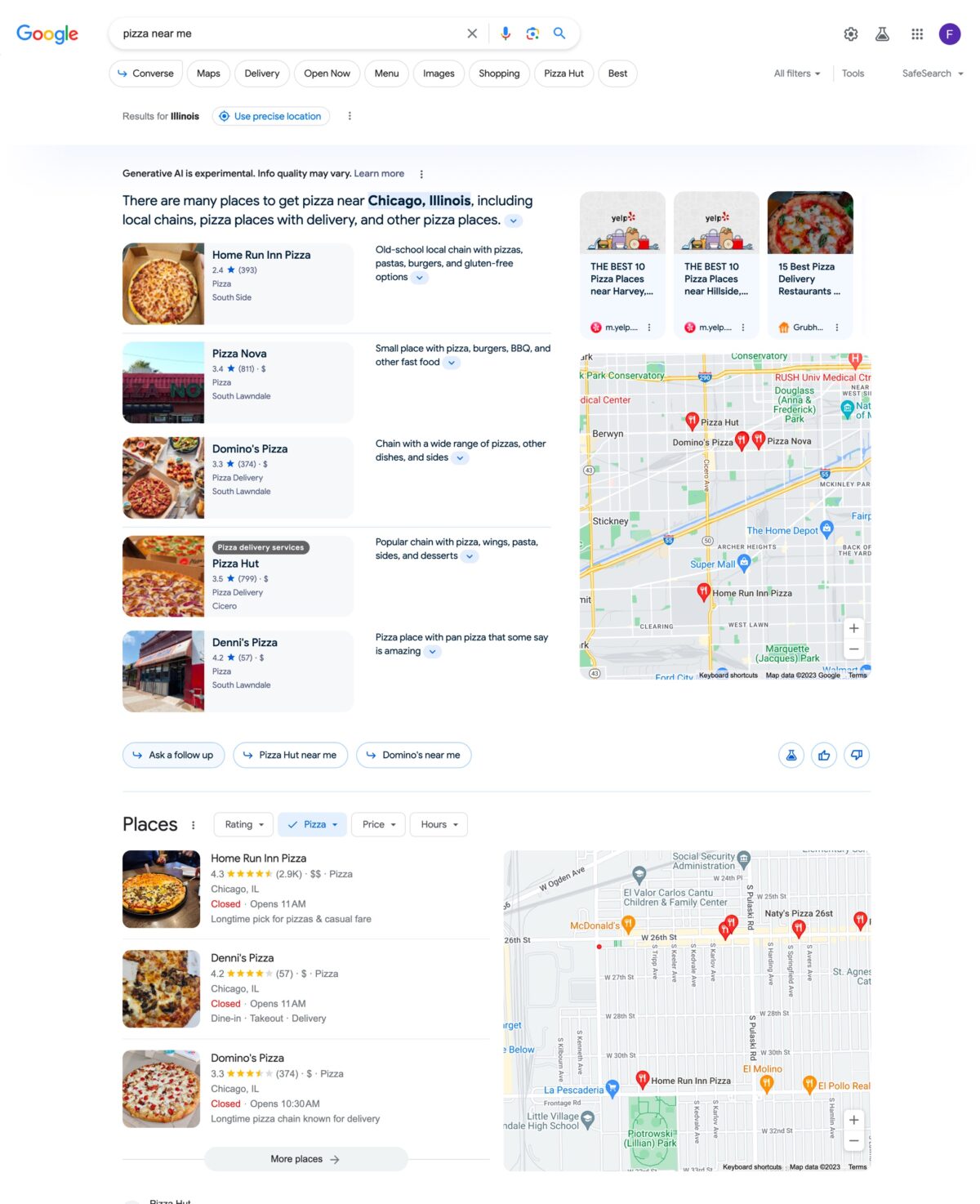
Search travel sector
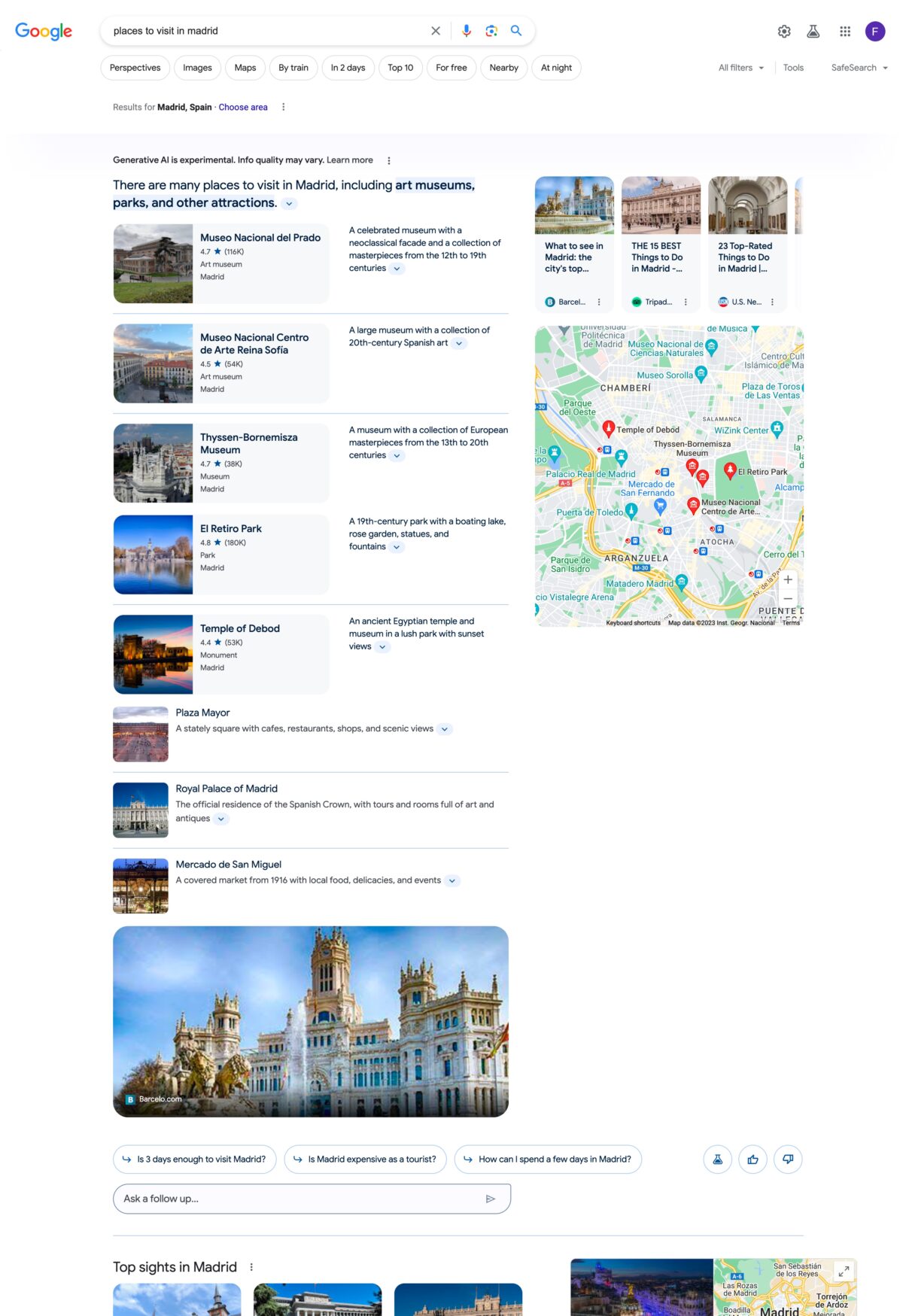
Conclusion
Although it has already been launched in 120 countries, it is not yet clear that Google will roll out the Google SGE functionality and make it accessible to the general public and the totality of searches. It is logical that Google preferred to massively test this new result format to understand how it impacts the search engine’s own usage habits, its advertising model, the difficult balance of relationships with content creators and broadcasters, etc.
It is possible that the Google SGE panel that will definitely be deployed will resemble the one we can analyze today, but it is also likely to undergo numerous evolutions and improvements, as we have seen in recent months. In the meantime, we will have to keep an eye on its evolution to anticipate its impact and prepare ourselves to compete in this new visibility space.
Additional references
- An SEO’s guide to understanding large language models (LLMs)
- Large Language Models and Knowledge Graphs: Merging Flexibility and Structure
- Transformers: the Google scientists who pioneered an AI revolution
- Google’s new A.I. search could hurt traffic to websites, publishers worry
- Google is ready to fill its AI searches with ads
- Twitter thread by Juan González about the patent behind Google SGE.




Nice study about Google SGE.
Still not available in France as you mentionned.
As an SEO tool editor, I keep a close eye on CTR trends. I’m going to implement a CTR prediction based on the semantics of the query, because in any case there are already huge variabilities linked to the universe of the query and its intention (informational, transactional).
The SEO profession is likely to change a lot… Right now, the market is focused on obtaining traffic on a specific query. With SGE, this query logic is transformed into a query “field” or “universe”. The answer will no longer be behind a blue link, but directly provided by Google’s LLM.
Thank you for your contribution, Sébastien. I agree with you that SEO will increasingly move away from a keyword-centric model and should focus on the entire purchase decision process, to fight for visibility both in search engines and anywhere else where the user is looking for inspiration, information, analysis, recommendations…..
Once again, SEO will have to adapt.
Great article, one of the best I’ve read about the topic so far. Well done!
Thank you so much, Grégory.