


Tabla de contenidos
La Web es un ecosistema que establece relaciones entre sus contenidos con enlaces. Dentro de un sitio web esta regla debe persistir, de modo que tanto el usuario como los robots de los buscadores necesitan enlaces rastreables para poder navegar entre todos los contenidos. Pero además el bot también necesita establecer la relación y jerarquía entre todos sus contenidos.
¿Qué son las páginas huérfanas?
Si una página está desconectada del resto porque no recibe enlaces desde ninguna otra página de un sitio, estaremos hablando de una página huérfana. Las páginas huérfanas no tienen otras páginas que les aporten autoridad o relevancia a través de los textos de anclaje de los enlaces.
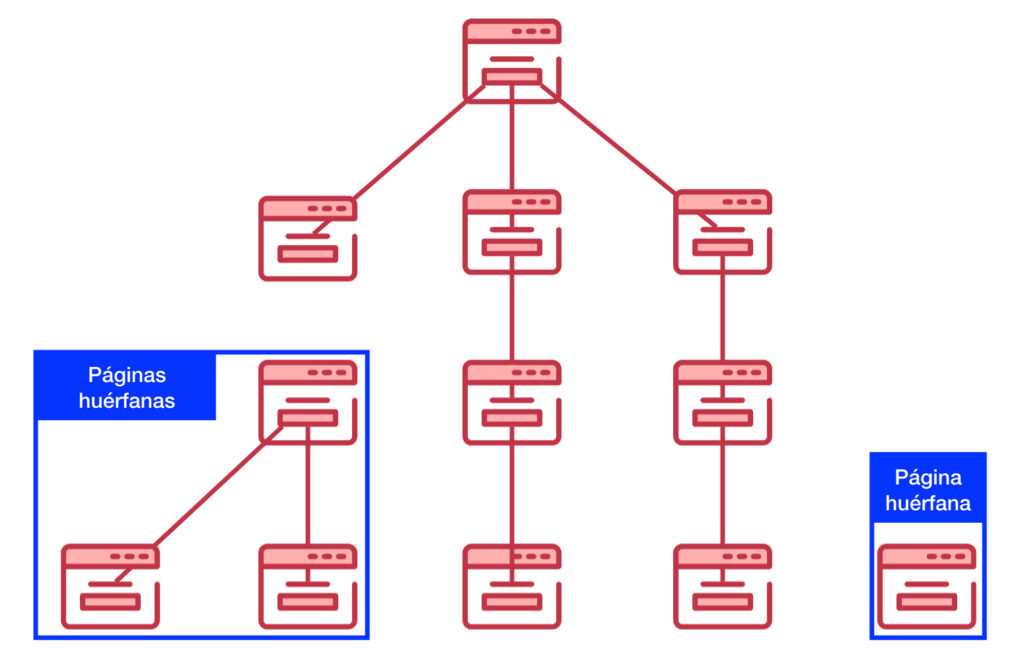
Aunque los robots de los buscadores sean capaces de llegar hasta este contenido desde enlaces provenientes de otros dominios, no serán capaces de localizarlos convenientemente dentro de la arquitectura del sitio al que pertenecen.
¿Son un problema para el SEO?
Las páginas huérfanas son un problema para el SEO de nuestro sitio no tanto por esta desconexión del resto de contenido del dominio sino por el tipo de páginas que suelen permanecer en este estado. Si una página tiene una buena cantidad de contenido de calidad y pierde los enlaces desde el resto de páginas, seguirá siendo una página que por sí misma es de calidad, pero su posicionamiento individual se verá afectado por la pérdida de:
- Autoridad general heredada desde el resto de páginas.
- Relevancia que aportaban los textos de anclaje de los enlaces.
- Capacidad de análisis periódico por parte de herramientas SEO, ya que al no poder acceder hasta ellas no podremos detectar errores con un rastreo corriente.
Pero el principal problema reside en que las páginas que quedan huérfanas o que se publican y no se enlazan desde otras páginas suelen ser:
- Páginas de campañas puntuales en Ads u otra plataforma de publicidad que actúan como puerta de entrada pero que en muchos casos no se suelen integrar en la navegación del sitio.
- Páginas obsoletas que se despublican: el CMS las desvincula de las categorías en las que aparece pero no las elimina.
- URLs que genera el CMS por error y que están desconectadas de la arquitectura.
- Pruebas y tests que se realizan pero después no se eliminan y que representan en muchos casos contenido duplicado.
Si este tipo de páginas se repiten de forma continua y acumulativa, al final este thin content puede suponer un problema para el posicionamiento orgánico de nuestro sitio.
Por lo tanto, las páginas huérfanas pueden generar problemas a la hora de conseguir tráfico SEO por estos dos problemas distintos:
- Falta de enlaces desde el propio sitio, lo que lastrará el posicionamiento.
- Generación de thin content cuando su contenido no es de calidad.
Cómo detectar páginas huérfanas
Teniendo claro que este tipo de páginas no son óptimas para el posicionamiento orgánico de nuestro sitio, debemos saber cómo detectarlas. Un rastreo con Screaming Frog o cualquier crawler no nos va a servir puesto que estas páginas carecen de enlaces, por tanto, estas herramientas no van a ser capaces de llegar hasta ellas.
Luego debemos intentar detectar por otras vías este contenido que no está enlazado, podemos hacerlo de distintas formas:
- Con un sitemap XML: en caso de que nuestro gestor de contenido sea capaz de generar un archivo sitemap XML con la lista de todas las páginas que genera nuestro CMS.
- Con Search Console: de esta herramienta obtendremos las páginas que generan impresiones aunque no generen tráfico SEO. Por ello, es una vía para descubrir páginas que, pese a no estar enlazadas son mostradas en los resultados de búsqueda en algún momento.
- Google Analytics: obtendremos las páginas que generan tráfico desde cualquier fuente, no necesariamente tráfico orgánico.
- Importando URLs con enlaces externos: se trata de páginas que están enlazadas desde otros dominios, independientemente de que generen tráfico. Esto podemos hacerlo con Google Search Console o cualquier tipo de herramienta como Majestic o Ahrefs.
- Obteniendo el listado de URLs HTML solicitadas a nuestro servidor desde el Log del servidor.
Con esto conseguimos disponer de todas las URLs posibles y, sobre todo, de las que obtienen tráfico o reciben autoridad desde otros dominios. Si unificamos estas URLs en una lista y la comparamos con la lista de URLs obtenida desde un rastreo completo del sitio, identificaremos como páginas huérfanas las páginas que aparecen en el listado completo de páginas pero no en el rastreo.

Esta es una labor que, aunque podemos resolver con relativa facilidad con un archivo Excel, resulta muy trabajosa. Podemos llevarla a cabo de forma más sencilla con crawlers como Screaming Frog y Ryte.
Con Screaming Frog
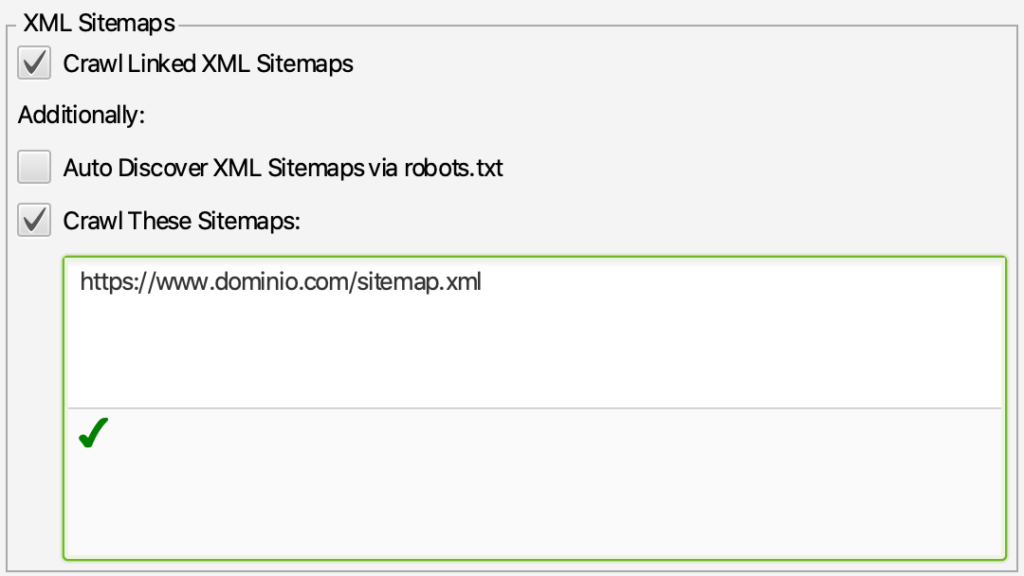
Screaming Frog nos permite seleccionar el archivo sitemap XML durante el rastreo para descubrir todas las páginas de nuestro sitio, solo debemos ir al menú Configuration —> Spider —> Pestaña Crawl y en este cuadro de diálogo hacer scroll hasta el bloque de XML Sitemaps donde:
- Activaremos la opción Crawl Linked XML Sitemaps
- Activamos Crawl These Sitemaps y en la caja inferior introduciremos el sitemap o sitemaps con el listado completo de las URLs nuestro sitio.
Pero además nos permite obtener más URLs de las herramientas Search Console y Analytics de Google. Para hacer esto tendremos que ir a la opción de menú Configuration y dentro de esta desplegar las distintas opciones de API Access. Entre estas opciones nos interesan las de Google Analytics y Google Search Console, en donde podremos conectar Screaming Frog con ambas y seleccionar en ambos casos la opción Crawl New URLs Discovered en la pestaña General de ambas opciones de menú. De esta forma, Screaming Frog rastreará las URLs que descubra a través de ambas herramientas.
Una vez tenemos toda la configuración, solo tenemos que rastrear nuestro sitio con el agregado de URLs de estas tres fuentes y, al terminar, ejecutar un Crawl Analysis. Una vez terminado el análisis en las pestañas Sitemaps, Analytics y Search Console, podremos obtener las URLs huérfanas si aplicamos en los tres casos el filtro Orphan URLs. Así, podremos saber qué URLs huérfanas se han detectado desde cada fuente de datos.
Con Ryte
La herramienta Ryte también cuenta con una opción para descargar nuestro sitemap XML. Tras el rastreo y la comparación con el listado de URLs, obtendremos las páginas huérfanas en la opción de menú Website Success -> Enlaces -> Páginas sin enlaces.
En este caso la herramienta no permite obtener URLs de otras fuentes, pero en la mayoría de ocasiones nos será suficiente para detectar este tipo de páginas sin enlaces siempre que el archivo sitemap XML esté correctamente implementado.
Cómo solucionar las páginas huérfanas
Solucionaremos las páginas sin enlaces de distinta forma en función de sus posibilidades de atracción de tráfico para nuestro sitio:
- Páginas con thin content o no relevantes: si estas páginas no son necesarias en nuestro sitio, lo más recomendable es proceder a su desindexación, borrándolas del inventario de contenidos del CMS o simplemente despublicándolas. En cualquier caso, deberán devolver un código 410 o 404 si se intenta acceder a ellas.
- Páginas relevantes en nuestro sitio: en este caso la solución es que dejen de ser huérfanas. Hay que integrarlas en la arquitectura de información de nuestro sitio, enlazándolas desde las secciones y contenidos que sean relevantes con ella. Con esto aumentaremos las opciones de atraer tráfico con ellas.
- A medio camino tendremos las páginas huérfanas que, aunque su contenido no sea de calidad, reciben enlaces de otros dominios: deberemos plantearnos si es posible mejorar su contenido e integrarlas en la arquitectura de información de nuestro sitio. Si no podemos mejorarlas, sería buena idea que la página devuelva un código 301 hacia la página más parecida posible de nuestro sitio para aprovechar su autoridad.
En resumen, se trata de integrar en la arquitectura de información las páginas que sean relevantes para nuestro sitio incluyendo enlaces adecuados hacia ella desde otras secciones del sitio. En caso de que no podamos hacer esto, procederemos a la eliminación de este contenido de la forma más amigable para los robots de los buscadores.
Se trata de acciones on page relativamente sencillas y que nos ayudarán a aprovechar al máximo el potencial para conseguir tráfico de nuestro sitio.



Muy bueno José,
con screaming frog la verdad es que es súper rápido. Sumas los 3 excel resultantes de sitemaps, analytics y search console, quitas duplicados… e voila !!
Muchas gracias por compartir siempre tan buena información
Un aspecto básico, que por tal, pasamos desapercibido. Gracias por recordar.