

Escrito por Ramón Saquete
Índice
- ¿Cuándo queremos enlaces reconocibles por Google?
- ¿Cuándo querremos enlaces irreconocibles por Google?
- ¿Cómo no aplicar Link Sculpting?
- ¿Cómo aplicar Link Sculpting sin aplicar rel=”nofollow”?
- ¿Es black hat SEO usar los botones que se comportan como enlaces?
- ¿Es posible evitar también el descubrimiento de la URL?
- Conclusión
Conocer la respuesta a esta pregunta es muy útil para saber si los contenidos indexables son rastreables y aplicar la técnica Link Sculpting. Entenderlo sirve para mejorar el posicionamiento y la indexación de nuestras páginas web. Veamos por qué.
A continuación, vamos a diferenciar dos tipos de enlaces o hiperenlaces: los que son detectados por Google y los que no. Su comportamiento de cara al usuario seguirá siendo el mismo, es decir, llevar al usuario a otra página, pero tendrán efectos distintos en el posicionamiento. Optaremos por unos u otros dependiendo de la situación.
¿Cuándo queremos enlaces reconocibles por Google?
Querremos enlaces rastreables cuando las URLs a las que apuntan sean interesantes para el posicionamiento, sean indexables y, por tanto, deseemos transmitirles parte del flujo de popularidad desde la página en la que se encuentran enlazadas.
¿Cuándo querremos enlaces irreconocibles por Google?
A veces, tenemos páginas útiles para los usuarios, como filtros de ordenación o rangos de precio, que no aportan valor al posicionamiento del sitio. Si hemos hecho nuestros deberes SEO, evitaremos la indexación de esas páginas añadiendo la meta etiqueta robots con valor noindex.
Sin embargo, quedan otros problemas y uno de ellos es justo el que trata de solucionar el Link Sculpting. Es el relacionado con la forma en que Google distribuye equitativamente la puntuación de popularidad o PageRank de la página entre todos los enlaces salientes. Si esos enlaces incluyen páginas que no interesa posicionar, el resultado es que el resto de ellos se llevarán menos puntuación.
Otro problema que intenta solucionar el Link Sculpting, es el enlazado a páginas indexables a las que no queremos pasar más PageRank, para no darles más importancia de la que ya tienen, cuando ya están enlazadas desde otras partes de la web o desde la propia página y solo se han añadido por usabilidad.
Por lo tanto, el Link Sculpting consiste en escoger determinados enlaces para hacerlos irreconocibles para Google y forzar así que el PageRank fluya hacia los enlaces que nos interesan.
Aunque no se suele nombrar actualmente y parece algo anticuado, Google sigue usando internamente el PageRank, tal y como afirma Gary Illyes en este podcast del 10 de diciembre de 2020.
¿Cómo no aplicar Link Sculpting?
Los enlaces con el atributo rel=»nofollow» no sirven para hacer Link Sculpting. Tampoco sirve el atributo para contenido generado por usuarios (rel=»ugc»), ni el atributo para contenido de anuncios y patrocinadores (rel=»sponsored»), ya que tienen el mismo efecto que rel=»nofollow».
Por lo tanto, la única manera de hacer Link Sculpting es añadiendo enlaces que en realidad no son tenidos en cuenta como tales.
¿Cómo aplicar Link Sculpting sin aplicar rel=”nofollow”?
Podéis corroborar esta información tanto en la conferencia anual de desarrolladores Google I/O de 2018 como en los siguientes tweets de John Mueller:
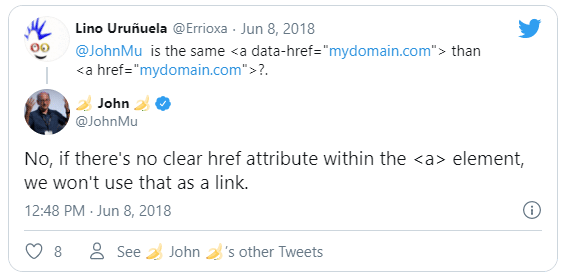
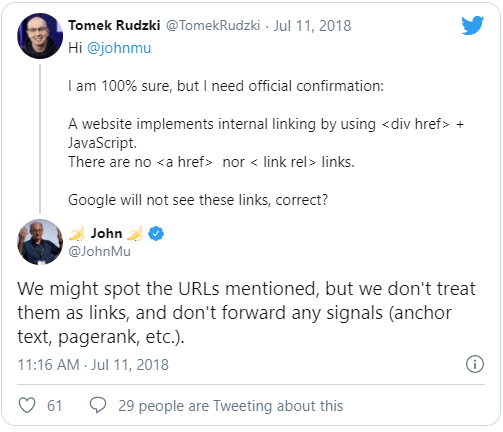
Por tanto, si tenemos una etiqueta <a> sin atributo href o una etiqueta <button>, <span>, <div> o cualquier otra que requiera JavaScript para enviar al usuario a la página solicitada al hacer click en ella, no nos contará como enlace y no perderemos PageRank.
Según esta definición, veamos ejemplos de lo que Google considera un enlace y lo que no. Algunos son del Google I/O de 2018 , otros de esta charla de la WMConf de 2020 y otros «cosecha propia».
Enlaces que lo son realmente
<a href="/enlace-real">Pasa PageRank</a>
Enlace normal con su etiqueta <a> y atributo href.
<a href="/enlace-real" onclick="funcionDeJavaScript('/enlace-real')">Pasa PageRank</a>Enlace con etiqueta <a> y atributo href. Los elementos adicionales no hacen que el código genere problemas.
<a href="/enlace-bueno#fragmento">Pasa PageRank a la URL sin fragmento</a>
Los fragmentos (la parte con # de la URL) son ignorados por las arañas, por lo que, si cambian el contenido de la página de destino, éstas no serían indexables, pero sus enlaces sí pasarían PageRank a la URL principal sin el fragmento. Sólo en raras ocasiones, los fragmentos se muestran en los resultados de búsqueda cuando se utilizan en una tabla de contenidos como ancla a una parte del documento.
Falsos enlaces: son implementaciones que se comportan como enlaces, aunque no lo son.
Los siguientes ejemplos involucran el uso de JavaScript para cambiar de página. Partimos del supuesto de que tenemos una función “cambiarPagina” que envía al usuario a la URL pasada como parámetro. Esta función se puede implementar como expongo a continuación (si no sabéis JavaScript os la podéis saltar, ya que no es necesaria para comprender lo importante):
<script>
function cambiarPagina(enlace){
window.location = enlace;
}
</script>
O si queremos abrir el enlace en una nueva pestaña o página, en su lugar, usaríamos la siguiente función:
<script>
function cambiarPagina(enlace){
var win = window.open(enlace, '_blank');
win.focus();
}
</script>
No son las únicas formas de implementar esta función. Por ejemplo, en una SPA (Single Page Application) realizaríamos una petición fetch o AJAX para recuperar el nuevo contenido y cambiar la URL con la API del historial por JavaScript, sin tener que recargar la página.
Veamos algunos ejemplos de falsos enlaces utilizando la función anterior:
<span onclick="cambiarPagina('/enlace-falso')"> No pasa PageRank </span>No se considera enlace porque no usa la etiqueta <a>. En lugar de <span> podríamos haber usado <button> o cualquier otra etiqueta.
<a onclick="cambiarPagina('/enlace-falso')"> No pasa PageRank </a>No se considera enlace porque no tiene atributo href.
<a data-href="/enlace-falso" onclick="cambiarPagina(this.dataset.href)"> No pasa PageRank </a>
No se considera enlace porque tampoco tiene atributo href.
<div href="/enlace-falso" onclick="cambiarPagina(this.getAttribute('href'))"> No pasa PageRank </div>En este caso hay atributo href pero no es una etiqueta anchor (<a>), por lo que tampoco pasa PageRank.
<a href="javascript:cambiarPagina('/enlace-falso')">No debería pasar PageRank</a>Este enlace tiene etiqueta <a> y atributo href pero no tiene una URL a la que pasar PageRank. En este caso, aunque no hay información clara al respecto, es posible que la página de origen sí le aporte PageRank, y por ello es mejor usar una de las implementaciones anteriores cuando queramos falsos enlaces.
Si en cualquiera de los ejemplos anteriores, al cargar la página, transformamos con JavaScript el código del enlace a una de las implementaciones de un enlace real (con una URL válida, con su atributo href y etiqueta <a>), entonces sí se considerará enlace y pasará PageRank, siempre que Google ejecute con éxito el correspondiente código JavaScript en la segunda pasada de indexación.
Debemos recordar que si encontramos cualquiera de los ejemplos anteriores sin el atributo onClick, seguirán sin ser enlaces, ya que el evento onClick se puede asignar desde un JavaScript externo sin usar dicho atributo. Si de todas formas no existe este evento ni en el HTML ni en el JavaScript externo, al hacer click sobre ellos no pasará nada. Es decir, seguirán sin ser enlaces y además no funcionarán como tales.
¿Es black hat SEO usar los botones que se comportan como enlaces?
Actualmente Google no especifica si se puede considerar black hat SEO la utilización de botones o enlaces por JavaScript en lugar de utilizar un enlace normal.
Si consideramos que no estamos ocultando visualmente enlaces (lo que sí se consideraría black hat SEO) sino poniendo botones visibles y que se comportan como tales, no tiene por qué ser visto como un intento fraudulento de manipulación de los resultados, ya que estos botones se usan para enlazar páginas o funcionalidades cuya indexación no aportaría ningún beneficio a los usuarios y empeorarían la calidad de los resultados del buscador. Esto nos lleva a pensar que no hay razón para que aplicar estas técnicas deba ser considerado en ningún momento black hat SEO.
¿Es posible evitar también el descubrimiento de la URL?
Usar enlaces irreconocibles no evita el rastreo, solo la pérdida de PageRank en el resto de enlaces de la página en la que se encuentran, ya que Google puede descubrir la URL igualmente (por ejemplo, si por error se incluye en el archivo Sitemap o a través de enlaces externos). Si la descubre, la incluirá en la cola de rastreo y la indexará como una URL huérfana o sin enlace (siempre que no esté bloqueada a la indexación con la meta-etiqueta «robots», con valor «noindex»).
Para evitar el descubrimiento de una URL dentro de nuestro propio sitio, podemos usar muchas técnicas de ocultación y ofuscación. Cuantas más usemos, más difícil será para una araña detectarla y más complicaremos el desarrollo. No obstante, siempre se puede dar el caso de que un usuario copie la URL en algún sitio y la comparta, así que la única forma 100% efectiva de evitar el descubrimiento de una URL es que no exista y esto se implementa cargando por AJAX el contenido que mostraría el enlace, sin cambiar de URL.
Si de todas formas, queremos evitar el descubrimiento de la URL en nuestro propio sitio, aunque luego Google pueda descubrirla por otros medios, aplicaremos las siguientes técnicas:
- Al hacer click, que se recupere la URL a ocultar con una petición AJAX o Fetch. Como Google no ejecuta los clicks, no verá la URL. Si en lugar de AJAX, enviamos un mensaje con un WebSocket, mejor todavía, porque Google no es capaz de indexar esta tecnología de ninguna manera.
- Si hemos optado por usar una petición AJAX, para mayor ocultación, podríamos bloquear la URL de la petición con el archivo robots.txt (sin bloquear peticiones necesarias para renderizar la página). También añadiríamos el parámetro de la cabecera HTTP «X-robots-tag:noindex» y enviaríamos la petición por el método POST en lugar de GET, ya que Google solo rastrea peticiones por GET.
- Si además, desde la respuesta a la petición AJAX o mensaje de WS, devolvemos la URL ofuscada con algún tipo de codificación o cifrado, mejor todavía.
- Por último, ofuscamos el JavaScript que realiza todos los puntos anteriores, para que el código sea indescifrable sin ejecutarlo.
Veamos un ejemplo de implementación bastante simple con la API Fetch. El siguiente código deberá estar en un archivo JS externo:
function cambiarPagina(id){
fetch('/get-url-from-id.php', {
method: 'POST',
body: id
})
.then(response => response.text())
.then(function(texto) {
window.location = atob(texto);
});
}
En este ejemplo, la petición Fetch devolvería la URL que le corresponde en la base de datos, al identificador pasado como parámetro. Esta URL estaría codificada en base64. Podría ser, por ejemplo, para el identificador 31 la URL: “aHR0cHM6Ly93d3cuaHVtYW5sZXZlbC5jb20v”. Después, esta cadena sería descodificada por la función «atob» y quedaría la URL «https://www.humanlevel.com/» a la que redirigiremos al usuario.
Finalmente, usando una herramienta de ofuscación de JavaScript, el código quedaría así:
<script>
var _0x31d5=['then','location','/get-url-from-id.php','POST','text'];(function(_0x49ef13,_0x340068){var _0x31d5a4=function(_0x1edee6){while(--_0x1edee6){_0x49ef13['push'](_0x49ef13['shift']());}};_0x31d5a4(++_0x340068);}(_0x31d5,0xdb));var _0x1ede=function(_0x49ef13,_0x340068){_0x49ef13=_0x49ef13-0x11e;var _0x31d5a4=_0x31d5[_0x49ef13];return _0x31d5a4;};function cambiarPagina(_0x476133){var _0x1333d0=_0x1ede;fetch(_0x1333d0(0x121),{'method':_0x1333d0(0x122),'body':_0x476133})[_0x1333d0(0x11f)](_0x168e00=>_0x168e00[_0x1333d0(0x11e)]())['then'](function(_0x57eaf4){var _0x5e0eb6=_0x1333d0;window[_0x5e0eb6(0x120)]=atob(_0x57eaf4);});}
</script>
El HTML del bóton podría ser el siguiente (aunque estaría mejor aún enlazar el evento desde el JavaScript, vamos a dejarlo así por simplificar):
<button onclick="cambiarPagina(31);">URL indetectable</button>
La ofuscación se puede complicar todo lo que queramos, pero cuanto más ofuscado esté el código más costará mantenerlo, por lo que, a no ser que estemos participando en una competición de ofuscación de JavaScript, no recomiendo pasarse demasiado si se opta por esta vía.
Conclusión
Ya sabéis cómo detectar enlaces que traspasan PageRank y son indexables y enlaces que no, para poder validar si se está usando la implementación correcta en cada caso y cambiarla en consecuencia, siempre que previamente se hayan tomado las decisiones SEO apropiadas para establecer en cuales de esas situaciones es conveniente usar cada una.



