

Escrito por Merche Martínez
Índice
Uno de los problemas de indexabilidad más comunes cuando realizo una auditoría SEO de un sitio web es el contenido duplicado. El objetivo de este artículo es definir una guía con algunos puntos a revisar que hemos detectado en Human Level gracias a la experiencia adquirida después de muchos años realizando consultorías SEO.
¿Qué es el contenido duplicado?
Los buscadores indexan cada contenido con un identificador único que es la URL de la página.
Es esencial que haya una correspondencia unívoca entre un contenido y una URL.
Presentar el mismo contenido bajo dos URLs distintas puede ser detectado como contenido duplicado por los buscadores que consideran el contenido duplicado como un intento de acaparar más posiciones en la página de resultados. Por ello seleccionan una URL (generalmente, la más antigua o popular) como la fuente “original” del contenido y la posicionan mejor, mientras que las demás que presentan el mismo contenido son relegadas a los últimos puestos. Un ejemplo sería:
www.example.com/prueba
www.example.com/prueba-2 -> Mismo contenido
Revisión de los resultado de búsqueda en Google
Contenido duplicado detectado por Google
Un indicador importante nos lo ofrece Google en sus resultados de búsqueda. Para ello debemos introducir el comando “site:” seguido de la URL del dominio, de este modo: site:www.example.com. Esta búsqueda nos muestra todas las páginas indexadas del dominio introducido, y lo que nos interesa a este respecto está en la última página. Un truco para llegar a la última página de los resultados de búsqueda de Google es el siguiente. En la URL podemos ver el parámetro start, si estamos en la página 2 el valor es 10, si estamos en la tercera es 20 y así sucesivamente. Pues si introducimos el valor 990 nos lleva a la última página. Quedaría así, start=990.
En caso de tener contenido duplicado aparece el siguiente mensaje donde nos indica que hay 490 páginas que no se han mostrado en los resultados de búsqueda porque son consideradas por Google como “muy similares a las que ya se muestran”.

Si clicamos en el enlace para repetir la búsqueda incluyendo los resultados que no se muestran podremos ver esas páginas que se consideran contenido duplicado. Por desgracia no están marcadas con un fondo llamativo ni nada que las destaque, ojalá. Así que aquí llegamos al punto de revisión de los resultados de búsqueda.
Contenido duplicado detectado por revisión
También se puede detectar contenido duplicado revisando las distintas páginas de los resultados de búsqueda fijándonos en los títulos y los snippets.
El título es uno de los elementos más importantes para calcular la relevancia on-page de una página. Si nos fijamos en los resultados es posible que nos llamen la atención varios títulos iguales. Este puede ser un indicador de contenido duplicado.
Si detectamos varios títulos iguales podemos comprobarlo con el comando:
site:www.example.com intitle:texto del título
Lo mismo ocurre con el snippet, es el fragmento de texto que describe brevemente el contenido de la página en las páginas de resultados de los buscadores (SERPs). Por defecto, este texto suele coincidir con el contenido de la metaetiqueta description de la página. Este punto es muy importante porque si vemos snippets repetidos es muy posible que nos encontremos ante contenido duplicado.
Listado de productos “No existen resultados”
Navegando por el sitio web podemos detectar páginas de listados que no tienen resultados. Si estas páginas muestran un mensaje del tipo “No existen resultados” lo que hacemos es introducir en Google el comando:
site:www.example.com “No existen resultados”
Y veremos las páginas indexadas de los listados sin resultados. Si las páginas no tienen contenido que las diferencie pueden ser consideradas como contenido duplicado.
Herramientas para detectar el contenido duplicado
Google Search Console
En Google Search Console tenemos la opción de mejoras de HTML. En esta sección vemos los títulos y las metadrescripciones que Google ha detectado como duplicados.
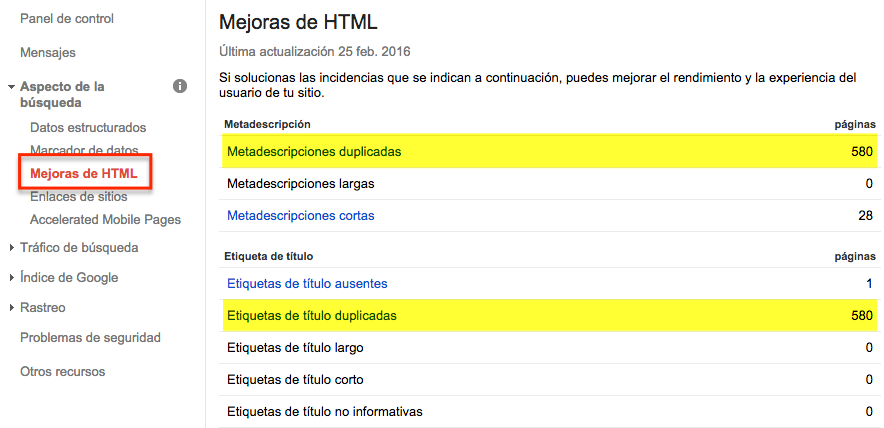
Si clicamos en etiquetas de título duplicadas vemos las páginas con etiquetas de título duplicadas y si desplegamos el título vemos en que páginas está incluido ese título. Ocurre lo mismo con la opción de metadescripciones duplicadas.
Screaming Frog
La herramienta Screaming Frog es un recurso SEO muy útil que entre otras muchas funcionalidades tiene la opción de mostrar el contenido duplicado. Screaming Frog es una herramienta de pago, pero tiene una versión gratuita que permite rastrear hasta 500 URLs de un dominio. En esta versión gratuita tenemos disponible la opción de ver el contenido duplicado que es lo que nos interesa.
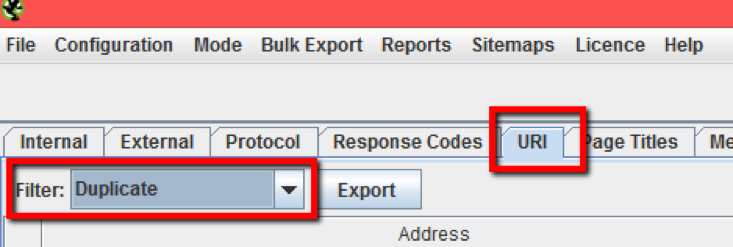
En primer lugar debemos capturar las URLs existentes en el sitio. Para ello introducimos el dominio de nuestro sitio web.

Una vez finalizado el rastreo, en la pestaña URI seleccionamos el filtro duplicate y al hacerlo vemos un listado de páginas con distinta URL y elementos duplicados como title, metadescripción, H1, etc.
Dominios espejo
El contenido duplicado también se puede dar entre dominios, cuando el contenido es exactamente el mismo, se les llama dominios espejo. El caso más común de dominios espejo es entre el dominio principal (example.com) y el subdominio www.example.com. Con el comando site:example.com –www verás las páginas indexadas de los subdominios, si es que los tiene.
También nos hemos encontrado con entornos de desarrollo publicados e indexados que generan contenido duplicado. Estos entornos pueden estar en subdominios como dev.example.com, pre.example.com o también pueden estar en un dominio totalmente distinto.
Paginador
Los paginadores son carne de cañón para el contenido duplicado. Algunos casos que podemos encontrarnos de contenido duplicado en paginadores son los siguientes:
- Primera página: es posible que el contenido de la primera página se muestre con y sin el parámetro de pagina=1.
www.example.com/listado
www.example.com/listado?pagina=1
- Última página: he detectado casos en los que no se controla correctamente el valor del parámetro del paginado para la última página y se devuelve el mismo resultado para cualquier valor superior.
www.example.com/listado?pagina=4 -> Última página
www.example.com/listado?pagina=10
www.example.com/listado?pagina=100
Con respecto a las páginas de listado hemos detectado un error común y es que suelen tener el mismo title y metadescripción. Esto lo podemos detectar fácilmente en la revisión de los resultados de búsqueda y en la sección de mejoras de HTML de Google Search Console.
Es posible que podamos llegar a un mismo contenido desde diferentes rutas de navegación. Es lógico que las fichas de producto, servicio o listados de un sitio web pueden pertenecer a distintas categorías. Pongo un ejemplo para que se entienda este caso: para alquilar un apartamento en Alicante podríamos seguir las siguientes rutas de navegación:
www.example.com ->
www.example.com/alquilar/ ->
www.example.com/alquilar/alicante/
o bien
www.example.com ->
www.example.com/alicante/ ->
www.example.com/alicante/alquilar/
En este caso las páginas www.example.com/alquilar/alicante/ y www.example.com/alicante/alquilar/ devolverían el mismo contenido y sería contenido duplicado.
Índice de parámetros
Este punto lo hemos visto de manera específica cuando he hablado de los paginadores. Pero puede darse con cualquier parámetro.
Es posible que para una URL con parámetros nos encontremos que para cualquier valor que pongamos en el parámetro nos devuelva el mismo resultado. Por ejemplo, para ordenar un listado existen las opciones orden=ascendente y orden=descendente, pero si no está bien programado puede darse el caso de que para el valor orden=blablabla devuelva el mismo resultado que para alguna de las opciones anteriores. En ese caso sería contenido duplicado.
Contenido de la home duplicado
El contenido de la home es fácil que se muestre en distintas URLs. Pongo algunos ejemplos que nos solemos encontrar:
www.example.com
www.example.com/home.php
www.example.com/index.html
Estas páginas pueden estar enlazadas desde el menú principal (inicio, home, etc.), desde el enlace del logo, desde el pie de página o desde cualquier página. Y sí, lo has adivinado, también sería contenido duplicado.
Etiquetas
Un mal uso de los tags o etiquetas puede generar páginas con el mismo contenido. Por ejemplo en los blogs, he detectado que es común crear nuevas etiquetas para cada artículo y es posible que estas etiquetas no se vuelvan a asignar a otros artículos. Cada una de estas etiquetas genera una página de listado con un único artículo. Estas páginas pueden considerarse contenido duplicado.
Enlaces externos
Para varios de los casos que he comentado, como el de orden=blablabla, puedes pensar ¿pero como se va a indexar esa URL si no existe un enlace desde mi web hacía ella? Pues muy sencillo, te pueden enlazar simplemente por error desde otro sitio web y si esa URL devuelve un código de servidor 200 OK la página se va a indexar.
Recomendaciones para evitar el contenido duplicado
Entonces, ¿qué hago si tengo contenido duplicado? Pues lo siento, no existe una fórmula única, pero os pongo algunas posibles soluciones:
- Canonical: para algunos casos la recomendación es incluir el elemento de enlace canonical correctamente. De este modo podemos sugerir a Google la página que queremos que se indexe. Aquí verás algunos casos en los que es recomendable usar el elemento de enlace canonical.
- Redirección 301: para algunos casos es recomendable realizar un redireccionamiento permanente 301 de una URL con contenido duplicado hacía la URL que consideramos correcta para ese contenido.
- Código de servidor 404: en algunos casos es posible que la página con contenido duplicado no deba existir. En ese caso debe devolver un código de servidor 404.
Cómo has visto el contenido duplicado es un error muy común en los sitios web que puedes detectar de forma relativamente sencilla y solucionar con las recomendaciones que te he dado. Ahora que has leído el artículo te invito a que revises tu sitio web y compruebes que el contenido duplicado no es un problema para ti.




Hola Merche,
enhorabuna por el post.
Me ha quedado una duda respecto a las etiquetas y las categorias, a mi Google me detecta que tengo las etiquetas con el mismo title que las categorias al igual que las metadescripciones. La pregunta es: creo que mediante el pluginde YOAST hay formas de cambiar los titles y metadescripciones de forma automatizada……sabes cual el codigo que he de utilizar en el campo a diferenciar?¿
Gracias
Saludos
Hola Alejandro,
En este caso entiendo que el problema lo podrías tener en la arquitectura del sitio ya que las categorías y las etiquetas no deberían ser las mismas. Las categorías deberían contener términos más genéricos y las etiquetas más específicos. Te pongo un ejemplo sencillo: para un sitio web de fotografía una categoría podría ser «fotógrafo de bodas» y dentro de esa categoría se podría incluir la etiqueta «fotógrafo de bodas en Alicante».
Con respecto al plugin Yoast SEO tienes la opción de automatizarlo desde el menú SEO -> Títulos y metas -> Taxonomías. Pero como te comento, mi recomendación es que revises la arquitectura del sitio.
Aquí tienes unos consejos para sacarle partido al plugin Yoast SEO.
Muchas gracias por tu comentario. 😉
Un saludo,
Hola, me ha encantado el post. 😀
Las páginas que archiva Google al final de los resultados de búsqueda… ¿se consideran páginas que posicionan o sólo indexado? ¿Deja Google de rastrearlo hasta que reciba clics? ¿Cómo se puede saber desde Search Console y otras como Screaming Frog cuáles son?
Muchas gracias de antemano!!
Hola Antonio,
Las primeras posiciones de los resultados de búsqueda son las que reciben el tráfico. El porcentaje de clics fuera de la primera página es mínimo. Te dejo un enlace a un artículo sobre un estudio que han realizado en Sistrix, https://www.sistrix.es/blog/probabilidades-de-click-en-las-serps-de-google/
Google rastrea e indexa todo lo que puede de nuestro sitio Web, aunque no todas las páginas serán igual de relevantes para nosotros.
En Google Search Console tienes la sección de análisis de búsqueda si marcas el filtro de página, el de posición y visualizas las posiciones en orden descendente verás las páginas que ocupan las últimas posiciones. Aunque para la búsqueda de contenido duplicado lo recomendable es hacer un site:www.dominio.com y mirar en las últimas páginas de los resultados de búsqueda.
Muchas gracias por tu comentario 😉
Muy bueno posteo Merche. Felicidades!
Muchas gracias. Espero que te haya sido útil 😉