

Written by Fani Sánchez
Index
The Latent Semantic Indexing is a form of information analysis used by search engines in which it is assumed that words found at a certain distance, in the same portion of text or area, have similar meanings or there is a close relationship between them.
Latent Semantic Indexing is not a new topic for those of us working in the Search Marketing world. For some time now, search engines have been trying to understand not only the lexical or grammatical logic of our searches, but also to delve into their semantic relationships and meanings. This article is intended as an introduction to the world of Semantic Latent Indexing (SLI) and its collateral effects, from which to extract some recommendations for adapting content optimization in your search engine optimization strategy.
A bit of history
Latent Semantic Indexing is not another Google invention. At least not strictly speaking. ISL is just a certain application of Latent Semantic Analysis (LSA ), which was conceived in the late 1980s in the heads of Dr. Thomas K. Landauer (Pearson Knowledge Technologies) and Dr. Susan Dumais (Microsoft) among others. You can consult the patent with a little encouragement.
ASL consists of the decomposition of the contents (matrix) into singular values (SVD) which, through certain calculations, manages to relate the similarities between groups of words, words and passages and other areas of the document.
This is to determine the relevance of a term or value in relation to the whole document or other parts or terms and values of the same, based on their occurrence or distance between them.
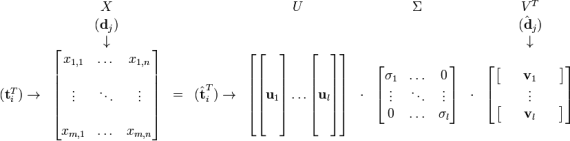
Years later, when sufficiently powerful computers became available, these calculations could be extended to larger volumes of data, in direct proportion to the capacity of the computers. Since then, its use has spread to multiple disciplines.
Although, like almost everything else surrounding Google, we have no “official statement” on the matter and some of the programmers I know who are versed in the subject of the natural language processing would claim that these are pure assumptions, we believe that Google has integrated ASL into its indexing system. and has known how to use ASL to their benefit or, as they would claim, to the benefit of the user.
What is Latent Semantic Indexing?
Latent Semantic Indexing is used by search engines for processing and analyzing information in vast proportions. Broadly speaking, ISL assumes that words found at a certain distance, in the same portion of text or area, have similar meanings or there is a close relationship between them. It tries to approach many aspects of language and human understanding, and learns from us every time it analyzes texts and documents or every time we refine a search. Therefore, we would do well to take it into account when approaching the strategy of creation and optimization of our web content.
ISL relates and identifies concepts through occurrence and proximity between words.
We believe that ISL connects topics and words by establishing relationships between semantic fields, between synonyms, verb forms, plurals and singulars or related terms although with different meanings.
These connections have been created after repeated analysis of sites and sites. The relationships between the terms within the different paragraphs, the entire document or site and the internal or external links of the site are studied. Search engines begin to take these references and define a theme according to what has been studied. They are integrated into your system as a further attempt to empathize with the user and to rank and rate pages for different user searches.
Relationships between terms or semantic fields
Some of the relationships we believe ISL can establish are within semantic fields (van-car-bike-car) or between synonyms (job-job, ball-ball), abbreviations (bike-bike), verb conjugations or simply words related to a common denominator (bottle-baby-bottle-cradle, clouds-cloudy, swimming-swimming).
To get some clue as to what terms Google presumably relates, it has been recommended more than once to use the ~ command (followed by the keyword in question) to get clues as to what terms Google considers to be related to your keyword. But this does not always work. Many times you will be able to verify with this method that their equivalences or compatibilities are not so frequent and some of them are even somewhat crazy:
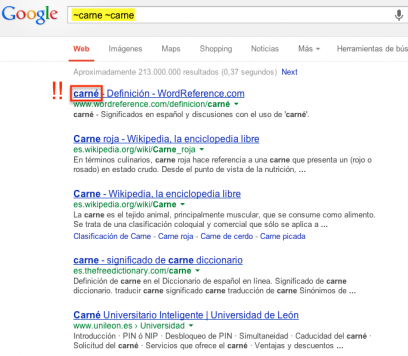
Search results after ISL
That search engines are trying to approach semantic analysis is a fact. The degree of success is very relative depending on the language or subject matter. Of course, the spiders are still machines that I personally believe are far from understanding certain nuances of language.However, its attempts to get closer to understanding certain searches and to improve the classification of certain sites or pages in the relevant categories beyond a few keyword The target is gradually improving.
Let’s take an example: if spiders were to crawl a page offering vacation packages, it would not be difficult for them to find terms such as ‘tourism’, ‘vacation’, ‘travel’ or ‘travel’ among the content. If you find a portal that talks about beaches in Spain, it would be common to find names of Spanish coasts and terms such as ‘sea’, ‘sand’ or ‘sunny’.
Little by little, it will be filing the relationships between these words and in the ideal future it will be able to offer the user the most relevant web in the face of an ambiguous search, appreciating the subtle difference that exists between someone looking for a holiday package on the Costa Blanca and someone looking for the best destinations on the Costa Blanca for a holiday. self-managed tour.
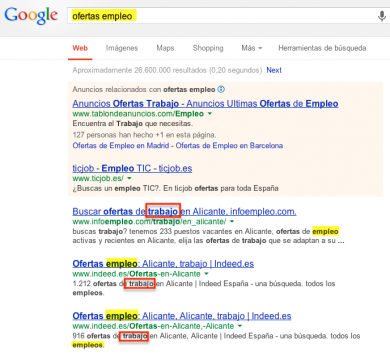
Today we already see some established relationships (much simpler) such as those that arise when doing a search for ‘job offers’: in addition to highlighting the words included in the search, it highlights those that it considers to be related and may be of interest to the user.
Advantages of Latent Semantic Indexing
Latent Semantic Indexing, far from being a palpable and real reality, is a trend that suggests new ways to expand our on-page search engine optimization strategy. It presents some advantages that we should take advantage of, such as:
- Positioning reinforcement: if we assume the ISL principle, we must also assume that semantically close keywords help to reinforce the positioning of the page, confirming to Google that your page deals with X topic, and offering you the possibility of appearing in the SERPS with another related term.
- More natural texts: Latent Semantic Indexing should allow you to write more natural and less “forced” texts and contents. Although it is advisable to continue to comply with the estimated density of your keyword, you can reinforce the text by writing synonyms and variants and not shoehorn the keyword between lines.
- Longer texts: possibly, by using other words of the same semantic field you will produce more text since related ideas will come to mind that otherwise you would not have thought of mentioning. By doing so, you will also provide valuable content to the user and you will be killing two birds with one stone.
Recommendations
- Lexical richness: write your texts with care and exploit the vocabulary related to your target keyword.
- Use your head: although we talk about matrices, mathematical formulas, and multiple tools, the truth is that what Google seeks is to approach the language of the user, who is neither more nor less than a person like you and me. Use your head. Think about how you talk when you treat or write a friend, your boss or an article for the pure pleasure of writing and not positioning (remember that?). Our vocabulary is richer than we think, we just have to make practice a habit.
If you are interested in this topic and want to know more, you can visit the explanation of Latent Semantic Analysis at Schoolarpedia.




