

Escrito por Ramón Saquete
Índice
- ¿Cómo se recomienda que se implemente JavaScript?
- ¿Cómo se comprueba el comportamiento del robot de Google?
- ¿Hay tecnologías que dejan de funcionar con cada nueva versión del robot?
- ¿Cómo afecta el evergreen Googlebot a los polyfills y al código transpilado?
- ¿A qué tecnologías JavaScript debemos prestar especial atención?
- ¿Está permitido AJAX?
- ¿Cómo se comporta Google con las variables de sesión y datos en el cliente?
- Conclusiones
En mayo de 2019, Googlebot dejó de usar el motor de JavaScript de la versión 41 de Chrome, para mantenerlo siempre actualizado a la última versión, pasando a llamarse evergreen Googlebot. Aunque con este cambio mejora la situación, hay tecnologías JavaScript que el robot no puede ejecutar y se deben tener en cuenta para indexar todo el contenido en lugar de un mensaje de error.
Como ya sabréis, Googlebot no siempre indexa el JavaScript, pero cuando lo hace hay tecnologías que no puede ejecutar. Vamos a ver qué se debe tener en cuenta para manejar estas situaciones.

¿Cómo se recomienda que se implemente JavaScript?
Por lo general, siempre debemos detectar qué tecnologías permite usar el navegador y, en caso de no estar soportada, debe existir un contenido alternativo accesible para el usuario y el robot. Supongamos que en lugar de mostrar un contenido alternativo, se muestra una página de error: si el robot de Google ejecuta el JavaScript y no habilita el uso de esta tecnología, indexaría este mensaje de error.
Si usamos características avanzadas, siempre resulta recomendable probar a desactivarlas en el navegador (esto se puede hacer desde chrome://flags en Chrome) y ver cómo se comporta la página en estos casos.
En la implementación, los desarrolladores pueden seguir una de estas dos estrategias:
- Mejora progresiva o progressive enhancement: consiste en partir de un contenido básico de texto e imágenes e ir añadiendo funcionalidades avanzadas.
- Degradado grácil o graceful degradation: consiste en partir del contenido con funcionalidades avanzadas e ir degradando a funcionalidades más básicas, hasta llegar al contenido básico.
Google recomienda la mejora progresiva, porque así es más probable que no nos dejemos ninguna situación sin cubrir. El nombre de las PWA (Progressive Web Applications) viene de ahí.
También es recomendable implementar en la web el evento onerror para retornar por AJAX al servidor los errores de JavaScript. De esta forma, se podrán guardar en un log que nos sirva para ver si hay algún problema con el renderizado de las páginas.
¿Cómo se comprueba el comportamiento del robot de Google?
Google actualiza la versión de Googlebot no solo en la araña, sino también en todas sus herramientas: la comprobación de URLs en Google Search Console, Mobile Friendly Test, Rich Results test y AMP test.
Por lo que si queremos ver el renderizado de la página con el último motor de renderizado de Googlebot o Web Rendering Service (WRS) y los errores de JavaScript, podemos hacerlo o bien desde Google Search Console en la opción “Inspeccionar URL” y, después del análisis, pinchar en “probar URL publicada”; o también se puede hacer desde la herramienta mobile friendly test.
¿Hay tecnologías que dejan de funcionar con cada nueva versión del robot?
Google Chrome a veces elimina características en sus actualizaciones (de las que podemos estar informados aquí y aquí), características que, normalmente, son experimentales y no han estado activas por defecto. Por ejemplo, la API WebVR para realidad virtual que ha quedado obsoleta en la versión 79, en favor de la API WebXR para realidad virtual y aumentada.
Pero, ¿qué ocurre cuando la característica no es tan experimental? Está el caso de los Web Components v0: cuando Google anunció que los iba a eliminar en la versión 73 (ya que Chrome era el único navegador que los soportaba y los Web Components v1 son soportados por todos los navegadores), los desarrolladores “early adopters” pidieron a Google más tiempo para actualizar sus desarrollos, por lo que han tenido que retrasar su eliminación completa hasta febrero de 2020. No obstante, es inusual que una web deje de renderizarse bien por una actualización de Googlebot ya que los ingenieros de Google siempre intentan mantener la retrocompatibilidad de las APIs, por lo que normalmente no debemos preocuparnos por esto. De todas formas, si hemos implementado en la web el evento onerror, como hemos comentado antes, podremos ver en los logs si surge algún error.
Si queremos ser muy precavidos, podemos tener localizados los URLs de cada plantilla que use la web y comprobarlos todos, con cada actualización de Googlebot, usando la herramienta mobile friendly test. En cualquier caso, deberíamos comprobar el renderizado de todas las plantillas siempre con cada actualización del código de la web.
¿Cómo afecta el evergreen Googlebot a los polyfills y al código transpilado?
Cuando una característica de JavaScript no funciona en todos los navegadores, los desarrolladores usan polyfills, que rellenan el código no implementado por el navegador con bastante código JavaScript adicional.
Al tener el motor del robot más actualizado, no es necesario que carguemos polyfills con la intención de que el robot vea bien la página, pero sí debemos hacerlo si queremos que usuarios de otros navegadores incompatibles la vean correctamente. Si queremos dar soporte solo a navegadores modernos, con el evergreen Googlebot se pueden usar menos polyfills y así la web cargará más rápido.
Del mismo modo, puede que no sea necesario transpilar o convertir el código JavaScript a una versión anterior para dar soporte a Googlebot (a no ser que estemos usando una versión de JavaScript muy moderna o extendida como TypeScript). Pero, de nuevo, sí para dar soporte a todos los navegadores.
¿A qué tecnologías JavaScript debemos prestar especial atención?
Con el cambio de Googlebot con la versión 41 de Chrome al evergreen Googlebot, hay tecnologías que antes provocaban errores de renderizado en las páginas y ahora funcionan correctamente. Nos estamos refiriendo a los Web Components v1, la CSS Font API loading para elegir cómo cargamos las fuentes, a WebXR para realidad virtual y aumentada, a WebGL para gráficos 3D, a WebAssembly para ejecutar código casi tan rápido como en una aplicación nativa, a la API Intersection Observer y al atributo loading=”lazy” para aplicar la técnica lazy loading de las imágenes y a características nuevas añadidas a JavaScript del estándar EcmaScript 6.
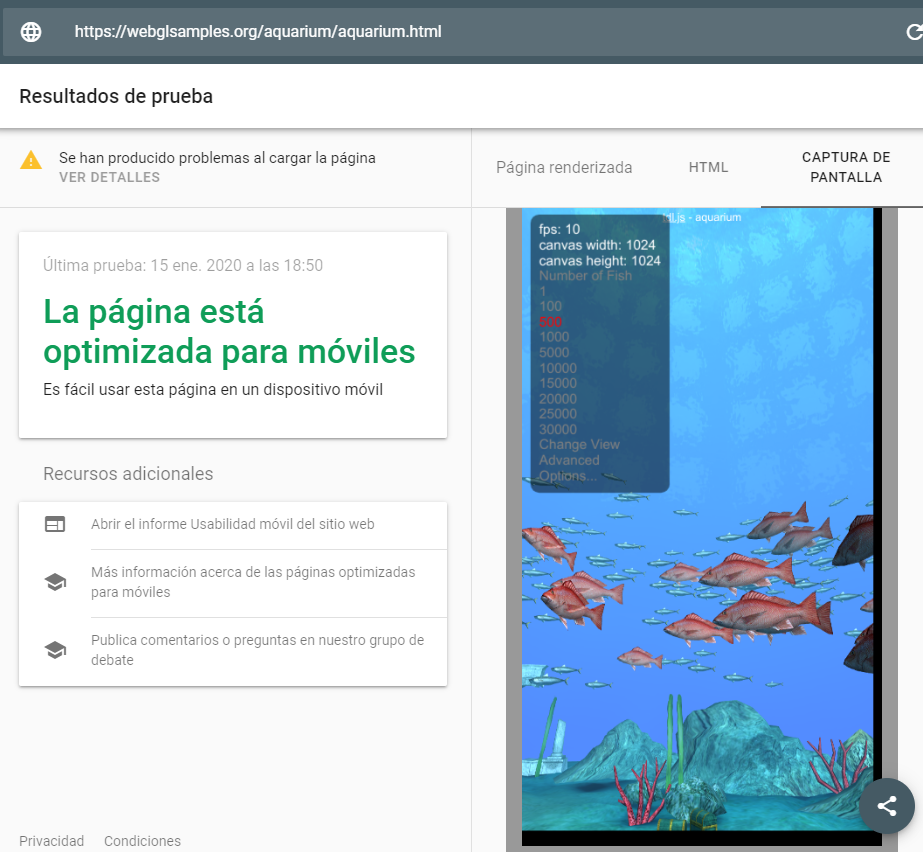
Pero ojo con algunas de estas tecnologías: cuando se usan, siempre es recomendable comprobar que Googlebot las renderiza por si queda alguna característica que no haya sido implementada por el robot. Además, aunque se renderice, esto no quiere decir que Google vaya a ser capaz de indexar el contenido mostrado dentro de una imagen 3D o en realidad aumentada, sino que el robot no va a bloquear el renderizado y no va a dar error.
Hay tecnologías con las que Googlebot no da error pero no las usa por razones lógicas, debido a que Googlebot no es un usuario, sino una araña. Estas tecnologías son:
- Tecnologías que necesitan permisos del usuario: por ejemplo, cuando mostramos un determinado contenido, dependiendo de la geolocalización del usuario, mediante la API Navigator.geolocation y, al denegar el permiso, presentamos un mensaje de error. Este error se indexará porque Googlebot deniega por defecto todos los permisos solicitados, así que será mejor mostrar una advertencia y un contenido genérico.
- Service Workers: se instalan en el navegador en la primera petición para ofrecer servicios propios de una PWA, como guardar páginas en el objeto Cache para ofrecerlas en modo desconectado u ofrecer al usuario notificaciones Push. Estas funcionalidades no tienen sentido para una araña. En consecuencia, Googlebot simplemente los ignora.
- WebRTC: no tendría sentido que el robot indexara el contenido de una tecnología útil para la comunicación P2P entre los navegadores. Habitualmente, esto es usado por aplicaciones web como Skype o Hangouts una vez que el usuario ha iniciado sesión, pero Googlebot no inicia sesión ni realiza videoconferencias.
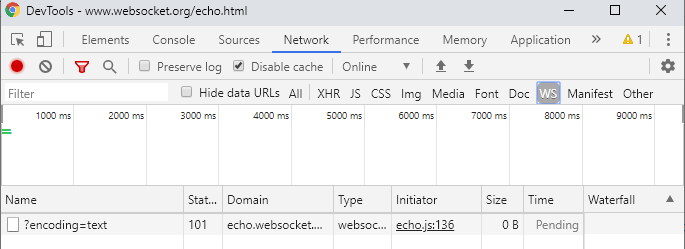
- WebSockets: los web sockets sirven para enviar actualizaciones de contenido desde el servidor sin que la web los solicite desde el navegador. Esto permite implementar chats o contenidos actualizares mientras navega el usuario, aunque también se pueden usar como sustituto de AJAX. Pero Googlebot no permite conexiones con websockets, por lo que si la web carga el contenido principal con WebSockets, no se indexará aunque Googlebot llegue a ejecutar el JavaScript.
Para saber si se usan websockets en una web, podemos recurrir a la pestaña WS de las herramientas para desarrolladores de Google Chrome:
Websocket en las herramientas para desarrolladores de Google Chrome De nuevo, esto no quiere decir que Googlebot no soporte la tecnología, sino que no la utiliza al no permitir conexiones:
Googlebot implementa websockets pero no permite inicializar la conexión.
¿Está permitido AJAX?
Cuando Googlebot ejecuta JavaScript, no tiene problemas en ejecutar la API fetch o XmlHTTPRequest con las que se implementa AJAX. Pero cuidado: cada petición AJAX cuenta en el crawl budget (por lo que si tenemos muchas bajará la indexación del portal).
Por otro lado, si en la carga inicial se recuperan contenidos por AJAX, estos no se indexarán si Google no tiene render budget para ejecutar JavaScript en esa página.
¿Cómo se comporta Google con las variables de sesión y datos en el cliente?
En una web, para mantener el estado entre peticiones (mantener el estado es saber qué acciones ha realizado antes el usuario, como iniciar sesión o añadir productos al carrito) se pueden utilizar cookies donde guardar un identificador, llamado valor de la cookie de sesión. Este valor identifica una zona de memoria donde almacenar variables de sesión en el servidor.
Sin embargo, usando las APIs SessionStorage, LocalStorage e IndexedDB, podemos guardar información en el navegador para mantener el estado y, si se trata de una SPA o Single Page Aplications, se puede mantener el estado en la memoria del cliente simplemente mediante variables JavaScript.
Si el comportamiento de Googlebot con las cookies se basa en que con cada petición se considera como si se tratase de un usuario nuevo que no envía ninguna cookie, con el SessionStorage y el resto de tecnologías para mantener el estado es igual.
Aunque Googlebot soporta SessionStorage, LocalStorage e IndexedDB y si programamos con estas tecnologías, no dará ningún error, en cada petición tiene estos almacenes de datos vacíos, como si se tratase de un usuario nuevo, por lo que no se indexará nada que dependa del estado y los URLs tendrán siempre el mismo contenido. Igualmente, si es una SPA, el robot no navegará por los enlaces haciendo clic, sino que cargará cada página desde el principio, inicializando todo el código JavaScript y sus variables con cada petición.
Conclusiones
Siempre es mejor que las webs se implementen de forma que todo su contenido se pueda indexar sin el uso de JavaScript, pero si se usa emplea esta tecnología para ofrecer funcionalidades que ofrezcan valor añadido al usuario, se debe tener cuidado con la forma en que éstas se implementan, para evitar errores de renderizado y la indexación de mensajes de error.



