

Escrito por Ramón Saquete
Índice
Tras la aparición de AJAX o, como se llama ahora, API Fetch, surgen los frameworks SPA (Single Page Application), que mediante el uso de peticiones Fetch generan parte del en el cliente, lo que impide que las arañas puedan indexar correctamente todo el contenido y, sobretodo, rastrearlo, porque además, este tipo de webs, se pueden implementar sin enlaces rastreables mediante el uso de URLs con fragmentos (uso de #) o directamente sin usar URLs en los enlaces (que sólo funcionan para el usuario al hacer click encima).
Con la denomación «SPA», surge el término Multiple Page Application (MPA), para referirse a los frameworks clásicos que generan todo el HTML en el servidor, que es lo que necesitan las arañas para poder indexar y rastrear las páginas sin problemas.
 Hay muchísimos frameworks de tipo SPA: por parte de Google tenemos Angular (anteriormente llamado AngularJS), por parte de Facebook, React y un sinfín más de código abierto como Vue, Meteor, Lazo, Rendr, Ember, Aurelia, Backbone, Knockout, Mercury, etc. Estos frameworks inicialmente solo podían ejecutarse en el cliente, pero ya veremos más adelante que la mejor solución es que no sea así.
Hay muchísimos frameworks de tipo SPA: por parte de Google tenemos Angular (anteriormente llamado AngularJS), por parte de Facebook, React y un sinfín más de código abierto como Vue, Meteor, Lazo, Rendr, Ember, Aurelia, Backbone, Knockout, Mercury, etc. Estos frameworks inicialmente solo podían ejecutarse en el cliente, pero ya veremos más adelante que la mejor solución es que no sea así.

¿Cómo funciona un framework SPA sin Universal JavaScript?
Como ya he comentado, los frameworks SPA se basan en el uso de la API Fetch, ya que trabajan cargándose en el navegador junto a un shell o caparazón que contiene las partes que no cambian durante la navegación, además de una serie de plantillas HTML, que se irán rellenando con las respuestas de las peticiones Fetch que se lanzarán al servidor. Hay que diferenciar cómo ocurre esto en la primera petición a la web y en la navegación por los enlaces una vez que ya ha sido cargada, ya que el funcionamiento es distinto:
- Primera petición: se envía la Shell por la red. Después, con una o varias peticiones Fetch (que también viajan por la red), se obtienen los datos para generar el HTML del contenido principal de la página. En consecuencia la primera carga se hace más lenta debido el trasiego de peticiones por la red, que es lo que suele tardar más. Por eso, en una primera carga, es más rápido enviar todo el HTML generado en el servidor en una sola petición, como hacen los frameworks MPA.
- Carga de las siguientes páginas después de la primera petición: en los frameworks SPA la carga es mucho más fluida y más rápida, puesto que no se tiene que generar el HTML entero. Además, se pueden añadir transiciones o barras de carga entre la visualización de una página y otra, lo que da una sensación de mayor velocidad. Sin embargo, contamos con un gran problema añadido: al generar parte del HTML en el cliente con JavaScript después de una petición Fetch que se hace igualmente con JavaScript, las arañas no pueden indexar estas páginas, sobre todo cuando el usuario puede llegar a páginas donde la araña ni siquiera tiene una URL que pueda indexar.
¿Cómo se intentaba hacer indexable un framework SPA antes de Universal JavaScript?
Inicialmente aparece la idea de utilizar una herramienta en el servidor que actúe como un navegador. Este navegador en el servidor entraría en acción ante la petición de una araña. Funcionaría de la siguiente forma: primero detectaríamos que la petición viene de la araña filtrándola por el user agent de la misma (por ejemplo «Googlebot») y después se la pasamos a una especie de navegador dentro del propio servidor. Éste, a su vez, pediría esa URL al servicio web, también dentro del mismo servidor. A continuación, al recuperar la respuesta de la petición al servicio web, ejecutaría el JavaScript, que haría las peticiones Fetch y generaría el HTML entero, para que de esa forma podamos devolvérselo a la araña y guardarlo en caché. Así, la próxima petición de la araña a esa URL, se devolverá desde la caché y, por lo tanto, funcionará más rápido.
Para hacer esto bien, en los enlaces que lanzan peticiones Fetch, deben existir URLs amigables (no se deben utilizar técnicas obsoletas como las URLs con hashbang «#!») y cuando el usuario pinche en un enlace, el desarrollador debe pintar la misma URL con JavaScript, usando la API del historial. De esta forma nos aseguramos que el usuario puede compartir y guardarse esa URL en favoritos. Esta URL debe devolver la página completa cuando la pida una araña al servidor.
Esta no es una buena técnica, porque presenta los siguientes problemas:
- Estamos haciendo cloacking, así que nuestra web sólo se indexará con las arañas que hayamos filtrado.
- Si no tenemos el HTML cacheado la araña percibirá que el tiempo de carga es muy lento.
- Si queremos que la araña perciba un tiempo de carga más rápido, tendremos que generar una caché con el HTML de todas las URLS, lo que implica tener una política de invalidación de caché. Esto puede resultar inviable por los siguientes motivos:
- Que la información deba de actualizarse continuamente.
- Que el tiempo de generar toda la caché sea inasumible.
- Que no dispongamos de espacio en el servidor para almacenar todas las páginas de la caché.
- Que no dispongamos de capacidad de procesamiento para poder generar la caché y mantener la página online al mismo tiempo.
- Hay que tener en cuenta que el problema de la invalidación de caché es muy complejo, ya que la caché se debe actualizar cuando cambia algo en la base de datos. Sin embargo, en la caché, no es fácil borrar exactamente los datos que se han actualizado, ya que al no ser una base datos, sino algo más simple y más rápido, no podemos seleccionar fácilmente lo que queremos regenerar, por lo que se siguen estrategias que borran más de lo necesario o dejan datos inconsistentes. Dependiendo del caso, estos problemas pueden impedir optar por esta solución.
- Por último: las herramientas que actúan como navegador en el servidor son de pago (Prerender.io, SEO4Ajax, Brombone,…).
¿Cómo hacer indexable un framework SPA con Universal JavaScript?
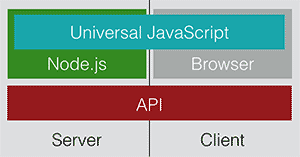
La idea de Universal JavaScript o JavaScript isomórfico (así se llamaba inicialmente), surge en el framework SPA de Facebook (React), y consiste en un utilizar una API universal que por debajo utilice APIs de JavaScript de navegador cliente o APIs de JavaScript de servidor con Node.JS, dependiendo de si esta API universal se ejecuta en el cliente o en el servidor, respectivamente. De esta forma, al escribir código en JavaScript usando esta API, podremos ejecutarlo tanto en el cliente como el servidor. Si unimos esto a un framework SPA que está pensado para funcionar sólo en el cliente, tenemos un framework universal que puede funcionar tanto en el cliente como en el servidor de la siguiente manera:
En primer lugar, hay que tener en cuenta que podemos distinguir entre tres tipos de código JavaScript distintos en nuestro desarrollo web, según donde se vaya a ejecutar:
- Sólo en el cliente.
- Sólo en el servidor, aunque este JavaScript se podría sustituir por cualquier lenguaje de servidor como PHP.
- Tanto en el cliente como en el servidor (JavaScript Universal).
Si utilizamos JavaScript en el bloque de código que se ejecuta sólo en el servidor, estaremos utilizando este lenguaje para los tres casos y, por tanto, se dice que usamos un framework Full-Stack.
Al igual que cuando no teníamos Universal JavaScript, el comportamiento va a ser distinto para la primera petición y las siguientes:
- Primera petición: independientemente de si la petición viene de una araña o de un usuario, se generará el HTML entero en el servidor haciendo uso del bloque de JavaScript Universal que lanza peticiones Fetch al JavaScript que se ejecuta sólo en el servidor. El funcionamiento es similar a cuando no se usa Universal JavaScript, pero con la diferencia de que las peticiones Fetch se hacen desde el servidor hacía sí mismo y no desde el cliente, ahorrando el trasiego inicial de peticiones por la red.
- Carga de las siguientes páginas después de la primera petición: si es un usuario y pincha en un enlace, el JavaScript que se ejecuta sólo en el cliente interceptará el click y pasará la petición al JavaScript Universal (el mismo del punto anterior). Éste hará una petición Fetch al JavaScript que se ejecuta sólo en el servidor, con la URL solicitada, y al recuperar los datos desde el servidor, mostrará la nueva página al usuario. En este caso, la petición Fetch va desde el cliente al servidor, evitando que se recargue la página entera.
De esta forma tenemos páginas que funcionan rápido tanto en la primera carga como durante la navegación posterior y las arañas no tienen problemas de indexarlas, porque para éstas siempre se va a generar la página completa en el servidor sin necesidad de hacer cloacking.
Conclusión
Si una empresa de desarrollo te ofrece una web con Angular, React u otro framework de desarrollo SPA, asegúrate de que conocen Universal JavaScript y que tienen algún proyecto que se esté indexando correctamente, ya que pueden no saber de su existencia o no saber utilizarlo, puesto que no es raro que usen una versión antigua del framework que no tenga Universal JavaScript. En Angular, por ejemplo, inicialmente apareció como un añadido independiente llamado Universal Angular y, más adelante, se incorporó al framework. En cambio, si lo conocen, no habrá ningún problema con la indexabilidad del sitio.
Otra historia es si conocen JavaScript, los frameworks y la problemática de este tipo de webs lo suficientemente bien para hacer el código mantenible y que los errores sean fáciles de probar y de arreglar. Un buen indicio de que saben a lo que se enfrentan, puede ser conocer si utilizan otros frameworks, junto a los ya mencionados, para manejar los estados de la aplicación, como Redux o Ngrx, ya que ésta es una tarea que sin este tipo de frameworks adicionales, puede derivar en código con poco mantenibilidad.



