

Escrito por Alberto Fernández
Índice
Son sistemas que mejoran los resultados de los LLM utilizando internamente un índice clásico de resultados ordenados, construido a partir de información propia para generar respuestas más precisas, relevantes y con menos alucinaciones. Su nombre procede de combinar el concepto de recuperación de la información empleado por los buscadores tradicionales (sistemas de IR o Information Retrieval) con el de generación, en referencia a la capacidad generativa de los grandes modelos de lenguaje (LLM).
En muchos escenarios de búsqueda, el problema principal no es generar una respuesta, sino hacerlo con información correcta y actualizada. Políticas que cambian, catálogos que se actualizan, documentación que crece cada semana son un reto para consultas que exigen información al día.
¿Qué pasa cuando la respuesta correcta depende de un PDF interno, una ficha técnica o una guía que no se encontraba en los datos originales del modelo cuando fue entrenado? Ahí es donde la RAG aparece para solucionar el problema.
¿Cuál es el objetivo de la generación aumentada por recuperación?
Su objetivo es sencillo: antes de responder, recupera los documentos correctos y los usa como parte del prompt para dar una respuesta fundamentada en lugar de confiar exclusivamente en sus datos de entrenamiento, ya que incluso teniendo la respuesta en sus datos de entrenamiento, esta podría no haberse aprendido con el suficiente peso.
De este modo, la RAG extiende las capacidades de un LLM más allá de sus datos de entrenamiento originales, proporcionando respuestas más precisas y específicas. Sin necesidad de reentrenar por completo el modelo para cada nuevo conjunto de datos, ofrece respuestas de mayor calidad, especialmente en contextos especializados.
Un ejemplo podría ser un asistente virtual de soporte técnico donde se incorporen nuevos productos con asiduidad.
En este caso, si un cliente pregunta por instrucciones de un producto muy reciente, un LLM tradicional podría no disponer de esa información.
Con la RAG, el asistente buscaría en la base de datos de manuales y encontraría la instrucción concreta para ese producto, incorporando esos datos en su respuesta. Así, el modelo combina sus capacidades lingüísticas generales con información actual y verificada tomada de fuentes fiables.
¿Cómo funciona la Retrieval-Augmented Generation?
El funcionamiento de la RAG consiste básicamente en un proceso compuesto por dos fases principales: recuperación de información y generación de la respuesta.
Veamos cómo sería un flujo típico:
- Consulta del usuario: un usuario plantea una pregunta o petición en lenguaje natural.
- Búsqueda de información (IR): el sistema RAG toma esta consulta y la pasa por un componente de búsqueda o recuperación. Este componente está diseñado para buscar los datos relacionados con la pregunta en una base de conocimiento relevante. Puede tratarse de documentos internos, bases de datos de productos, archivos legales, etc.Más técnicamente, esa consulta del usuario se transforma internamente en un vector (embedding), normalmente del tipo dense vector, que representa el significado del texto, y se usa para buscar los fragmentos más parecidos dentro de una base de conocimiento. Esta base no es más que un conjunto de documentos previamente indexados como vectores. Es común aplicar un proceso llamado chunking que divide el texto en pasajes, para que el buscador pueda encontrar más eficientemente los fragmentos más relevantes, en lugar del documento completo.
- Reordenamiento y selección: una vez recuperados un número k de fragmentos más relevantes (el número se define manualmente y se llama hiperparámetro top-k), puede aplicarse un re-ranking, es decir, una reorganización de los resultados para mejorar su calidad. Por ejemplo, realizando una segunda búsqueda sobre los resultados iniciales con otro tipo de vectores que, en lugar del significado, tienen en cuenta las palabras clave (sparse vectors), como hacía la búsqueda clásica.
- Montaje del prompt: con la consulta original y los fragmentos seleccionados, se construye el prompt final ampliado que se le pasa al LLM. A este prompt lo llamamos ampliado porque contiene tanto la pregunta original como los datos recuperados, y opcionalmente puede también incluir una instrucción explícita como, por ejemplo, “cita la fuente utilizada”, “responde solo si hay información suficiente”, etc.
- Generación de la respuesta: el LLM recibe este prompt ampliado y genera una respuesta en lenguaje natural. Dado que ahora sí dispone de datos específicos del tema, el modelo puede elaborar una respuesta mucho más precisa.
- Entrega al usuario: finalmente, la respuesta generada se muestra al usuario y, si corresponde, puede incluir referencias o citas de la fuente consultada para una mayor transparencia.
Aunque parezcan muchos pasos, este proceso completo ocurre normalmente en pocos segundos.
Hay que tener en cuenta que, aunque la mecánica parece en principio sencilla, un sistema RAG en producción requiere ciertas capas de control. Veamos algunas de ellos:
- Filtros de acceso: cada usuario debe recibir solo la información que le corresponde.
- Plantillas de salida: para mantener el formato y citar fuentes de forma consistente.
- Política de rechazos: si no hay documentos adecuados o suficientes, el sistema debería saber cuándo no contestar.
- Métricas de evaluación del sistema IR: las métricas clásicas habituales son precisión, cobertura y exactitud, obtenidas a partir de la llamada matriz de confusión. Se obtienen de forma estadística:
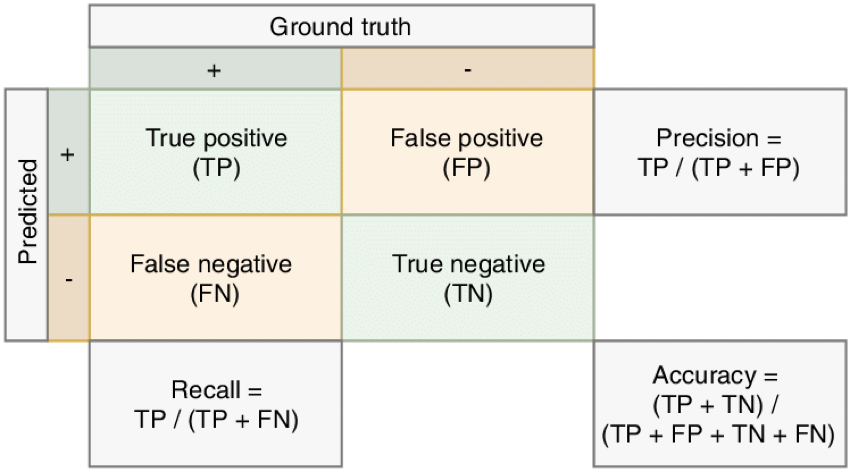
- Métricas de evaluación del RAG completo: por ejemplo, la triada RAG, que consta de tres métricas que miden la relevancia de la respuesta respecto a la pregunta, relevancia del contexto aportado por el sistema IR respecto a la pregunta y uso que hace la respuesta del contexto). Se obtienen con un LLM.
- Mantenimiento de la base de conocimiento: añadir nuevos documentos, corregir errores o cambiar políticas requiere un proceso ordenado y mantener un registro de los cambios efectuados.
Resumiendo, un RAG funciona añadiendo un paso de búsqueda de información útil y conocimiento antes de la generación de texto. De esta forma el modelo ya no depende solo de lo que sabe por su entrenamiento, sino que se apoya en datos externos para fundamentar sus respuestas y acercar su pensamiento a los datos de entrenamiento que más nos interesan, reduciendo de esta forma la probabilidad de errores y dando respuestas más relevantes para el usuario.
¿Cuándo se recomienda su uso?
El uso de RAG es especialmente recomendable en situaciones donde se requiere que una IA ofrezca respuestas precisas, actualizadas y específicas de un dominio.
Algunos casos típicos donde la RAG es especialmente útil podrían ser:
- Atención al cliente: los chatbots de soporte se benefician enormemente de la RAG. Si un cliente pregunta algo específico sobre un producto o servicio, el chatbot podría recuperar la información exacta desde manuales, preguntas frecuentes, guías internas de la empresa, un registro de respuestas previas…
- Comercio electrónico: en un e-commerce, un asistente virtual de compras con RAG podría aportar muchísimo valor, pues podría consultar en tiempo real la base de datos de productos para responder preguntas sobre disponibilidad, características o precios actualizados.
- Sector legal: en entornos jurídicos, donde la exactitud de la información es crítica y existen numerosos cambios de normativa o nueva jurisprudencia, la RAG es, sin duda, muy útil. Un asistente legal impulsado por RAG podría buscar cláusulas en leyes, regulaciones o jurisprudencia relevantes y utilizarlas para responder una consulta.
- Banca y finanzas: En el sector financiero, la RAG permite a los asistentes virtuales manejar información sensible y cambiante con mayor fiabilidad. Un bot bancario interno podría, por ejemplo, recuperar las últimas políticas de crédito o los tipos de interés actuales de una base de datos interna para responder preguntas de un empleado o cliente.
En términos generales, se recomienda usar RAG cuando:
- La información requerida no está en el entrenamiento del modelo: Si el modelo necesita conocimiento muy específico de una empresa o datos posteriores a su fecha de fin de entrenamiento, RAG es una opción excelente.
- Es vital mantener las respuestas actualizadas: para dominios donde los datos cambian frecuentemente (como en los ejemplos anteriores que hemos visto), la RAG permite incorporar esos cambios sin tener que reentrenar el modelo cada vez.
- Se busca reducir errores y alucinaciones del modelo: al anclar las respuestas en datos verificables, una RAG disminuye el riesgo de alucinaciones. No las evita del todo, pero es un avance muy importante.
- El coste o tiempo de entrenamiento es un factor crítico: hay que tener en cuenta que ajustar finamente un LLM puede ser muy costoso en tiempo, recursos computacionales y dinero, además de que requiere repetir el ajuste fino con cada nuevo documento. Por otro lado, entrenar un LLM desde cero es algo reservado sólo a centros de datos gigantescos, debido a que añadir documentos nuevos una vez entrenado, produciría lo que se llama un olvido catastrófico. RAG es una solución mucho más barata al poder incorporar información sin tener que reentrenar el sistema con todos los datos, con cada nuevo documento que se añade.
¿Cuándo no compensa utilizar RAG?
Aunque hemos visto lo útil que es la RAG en muchos casos, no siempre es la opción ideal.
Hay situaciones en las que implementar un sistema de recuperación puede no justificar los recursos o la complejidad añadida. Veamos algunos ejemplos:
- Consultas generales resueltas por el modelo base: Si las preguntas de los usuarios se pueden responder correctamente con el conocimiento general que el LLM ya tiene, añadir una RAG podría ser innecesario. Por ejemplo, para un asistente genérico que responde definiciones sencillas o preguntas de cultura general.
- Dominio de datos pequeño o estático: Si la información especializada cabe en un conjunto de datos manejable, a veces es más sencillo incorporar ese conocimiento directamente en prompts. Por ejemplo, si sólo se tiene un manual de 50 páginas que casi nunca cambia.
- Limitaciones de rendimiento y latencia: RAG añade pasos adicionales (búsqueda en base de datos, procesamiento de documentos) antes de generar la respuesta. En entornos donde la velocidad es crítica esta latencia extra puede ser un problema. Un sistema RAG puede ser menos eficiente y escalable que un LLM solo, especialmente si la base de conocimiento es muy grande y las búsquedas son costosas.
- Recursos técnicos limitados: Implementar RAG requiere disponer de infraestructura para almacenar y gestionar la base de conocimientos y para ejecutar las consultas de recuperación. No todas las empresas cuentan con esas capacidades. Si no se dispone de un equipo técnico para mantener actualizado el repositorio de datos y afinar el sistema de búsqueda, un proyecto RAG podría ser complejo de sostener. Para empresas muy pequeñas o proyectos simples, podría no compensar la inversión frente a usar un modelo preentrenado tal cual o con un ajuste fino básico.
- Casos donde la creatividad importa más que la exactitud: Si la tarea principal del modelo es creativa (por ejemplo, escribir una historia de ficción, generar ideas de marketing, etc.), el uso de RAG podría ser incluso contraproducente, mientras que el ajuste fino es la solución ideal para dotar al modelo de la capacidad de escribir con un estilo particular.
En esencial, podemos ver que el uso de RAG, siendo muy recomendable en algunos casos, no es algo aconsejable de forma universal.
Cuando el conocimiento requerido es estable, de alcance limitado o la simplicidad del sistema es clave, otras soluciones como prompt engineering o fine-tuning ligero podrían resultar más adecuadas.
Asimismo, si no se dispone de un contenido de calidad para recuperar, un RAG tendrá muy poco que ofrecer. Por lo tanto, siempre conviene evaluar el uso que se va a hacer en cada caso: si la complejidad adicional de un RAG no se traduce en una mejora sustancial en la calidad de las respuestas, probablemente no compensará esa inversión.
¿Qué riesgos tiene RAG?
Dependencia de la calidad de recuperación
RAG hereda el principio tan conocido de “garbage in, garbage out”.
Es decir, si el módulo de búsqueda recupera información irrelevante o incorrecta (en palabras llanas, basura), el modelo generará su respuesta basándose en eso (generará basura).
Por ejemplo, si la base de conocimiento está desactualizada o contiene errores, el asistente podría dar información equivocada con mucha confianza.
Por ello, es fundamental mantener las fuentes al día y filtrar aquellas que no sean confiables, porque hay que recordar que el modelo no juzga la veracidad, solo utiliza lo que se le proporciona.
Alucinaciones y coherencia
Aunque una de las ventajas que habíamos visto que tiene RAG es que reduce las alucinaciones al anclar respuestas en datos reales, no las elimina por completo.
El modelo podría aún inventarse conexiones entre la información recuperada y la pregunta, o mezclar datos de forma errónea.
Además, si se recuperan múltiples fragmentos, el modelo podría llegar a tener dificultad para sintetizarlos coherentemente.
Latencia adicional
Como mencionamos, el paso de búsqueda puede ralentizar la respuesta.
Para el usuario final, esto se percibe como un chatbot que tarda más en contestar.
Si la base de conocimiento es muy grande o las consultas son complejas, la latencia podría aumentar más y agravar este problema.
Por ello, hay que diseñar el sistema con cuidado para que siga siendo ágil. Por ejemplo, optimizando índices o limitando la cantidad de texto que se devuelve.
Si además nos encontramos con aplicaciones de alta demanda, la escalabilidad debe planificarse con aún más cuidado, ya que más usuarios y más datos pueden multiplicar la carga en la etapa de recuperación.
Complejidad y coste de mantenimiento
Como ya ha quedado claro, un sistema RAG es más complejo que un modelo aislado.
Requiere mantener actualizados tanto el modelo (si se va refinando) como las fuentes de donde obtenemos los datos, lo que supone un trabajo continuo: ingresar nuevos documentos, reindexar contenidos, etc.
También hay que tener claro que ejecutar búsquedas y manejar un vector DB puede incrementar los costes computacionales (más memoria para almacenar embeddings, más procesamiento para consultas), encareciendo todo.
Seguridad y privacidad de los datos
RAG a menudo implica alimentar al modelo con datos privados o sensibles de la empresa como, por ejemplo, datos de clientes, políticas internas…
Es crucial asegurarse de que esa información no se filtre.
Una ventaja de RAG es que los datos confidenciales no se “mezclan” permanentemente en el entrenamiento del modelo, sino que permanecen en una base separada, lo que permite cierto control.
Sin embargo, si la base de conocimiento externa se ve comprometida, existe riesgo de exposición.
Por ello, es fundamental implementar medidas de seguridad que sean lo más robustas posibles en el almacenamiento y acceso a las fuentes (cifrado, controles de acceso, anonimizaciones cuando proceda, etc).
Propiedad intelectual
Sin duda, uno de los puntos que más debate crean en torno a la IA es el tema de la propiedad intelectual, y en un sistema RAG este punto es aún más delicado.
Al recuperar texto de fuentes existentes, cabe la posibilidad de reutilizar contenido protegido por derechos de autor.
Si el modelo cita textualmente párrafos de un documento externo para crear su respuesta, podría tener implicaciones legales si ese contenido no es público o autorizado.
Esto requiere cuidar al máximo las políticas de uso de datos. Por ejemplo, usar RAG solo con documentos de la propia organización o fuentes públicas permitidas, o parafrasear la información recuperada en lugar de copiarla tal cual.
Falsa sensación de confianza
Un caso común es que las respuestas de un sistema RAG pueden percibirse como totalmente fiables solo porque incluyen datos externos.
Los usuarios pueden pensar que, al provenir de alguna fuente, la respuesta va a ser siempre correcta. Sin embargo, y como ya hemos visto, si la fuente estaba sesgada o si el modelo interpretó mal la información, la respuesta puede seguir siendo errónea.
Esta falsa sensación de confianza implica que los usuarios podrían no cuestionar una respuesta equivocada porque viene acompañada de datos. Por ello, es bueno que el sistema indique las fuentes y anime a verificar, especialmente en ámbitos críticos (salud, finanzas, legal) por el usuario o por expertos a los que pueda recurrir.
La transparencia ayuda, pero debemos recordar que la RAG no garantiza la infalibilidad. Simplemente mejora las probabilidades de acierto.

