


Tabla de contenidos
Its name comes from combining the concept of information retrieval used by traditional search engines (IR systems or Information Retrieval) with that of generation, referring to the generative capacity of large language models (LLMs). These are systems that enhance the results of LLMs by internally using a classic ranked index built from proprietary information to generate more accurate, relevant responses with fewer hallucinations.
In many search scenarios, the main challenge isn’t generating an answer but doing so with correct and up-to-date information. Policies that change, catalogs that are constantly updated, and documentation that grows every week are a challenge for queries that require current information.
What happens when the correct answer depends on an internal PDF, a technical sheet, or a guide that wasn’t part of the model’s original training data? That’s where RAG comes in to solve the problem.
What is the goal of Retrieval-Augmented Generation?
Its goal is simple: before answering, it retrieves the correct documents and uses them as part of the prompt to provide a grounded response instead of relying solely on its training data, since even if the answer exists in its training set, it may not have been learned with enough weight.
This way, RAG extends the capabilities of an LLM beyond its original training data, delivering more accurate and specific responses. Without the need to fully retrain the model for every new dataset, it offers higher-quality answers, especially in specialized contexts.
An example could be a virtual technical support assistant where new products are frequently introduced.
In this case, if a customer asks for instructions about a very recent product, a traditional LLM might not have that information.
With RAG, the assistant would search the manual database and find the specific instruction for that product, incorporating that data into its response. Thus, the model combines its general language abilities with current, verified information taken from reliable sources.
How does Retrieval-Augmented Generation work?
The functioning of RAG basically consists of a process made up of two main phases: information retrieval and response generation.
Let’s see how a typical flow works:
- User query: a user poses a question or request in natural language.
- Information search (IR): the RAG system takes this query and passes it through a search or retrieval component. This component is designed to find data related to the question within a relevant knowledge base. It could be internal documents, product databases, legal files, etc. Technically, that user query is internally transformed into a vector (embedding), usually a dense vector, representing the meaning of the text, and used to search for the most similar fragments within the knowledge base. This base is nothing more than a set of documents previously indexed as vectors. It’s common to apply a process called chunking, which divides the text into passages, allowing the search engine to find the most relevant fragments more efficiently rather than the entire document.
- Reordering and selection: once a number k of the most relevant fragments are retrieved (the number is manually defined and called the top-k hyperparameter), a re-ranking can be applied—that is, a reorganization of the results to improve their quality. For example, performing a second search over the initial results using another type of vector that, instead of meaning, takes into account keywords (sparse vectors), as traditional search did.
- Prompt assembly: with the original query and the selected fragments, the final expanded prompt is built and passed to the LLM. We call this prompt expanded because it contains both the original question and the retrieved data, and it may also optionally include an explicit instruction such as “cite the source used” or “answer only if there is enough information.”
- Response generation: the LLM receives this expanded prompt and generates a natural language response. Since it now has specific data about the topic, the model can produce a much more accurate answer.
- Delivery to the user: finally, the generated response is shown to the user and, if applicable, may include references or citations of the consulted sources for greater transparency.
Although it may seem like many steps, this entire process usually occurs in just a few seconds.
It’s important to note that, while the mechanics may seem simple at first, a production-ready RAG system requires several control layers. Let’s look at some of them:
- Access filters: each user should only receive the information they are authorized to access.
- Output templates: to maintain consistent formatting and citation of sources.
- Rejection policy: if there aren’t enough suitable documents, the system should know when not to answer.
- IR system evaluation metrics: common classic metrics include precision, recall, and accuracy, obtained from the so-called confusion matrix. These are statistically derived:
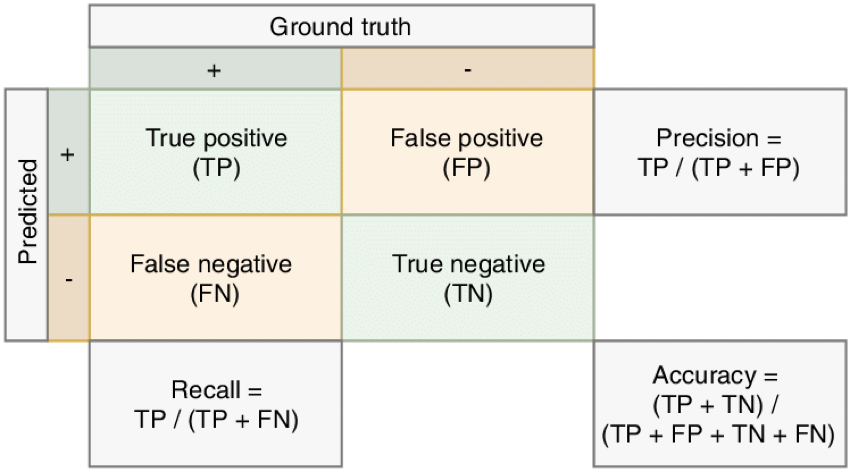
- Full RAG evaluation metrics: for example, the RAG triad, which consists of three metrics that measure the relevance of the response to the question, the relevance of the IR system’s context to the question, and the response’s use of that context. These are obtained using an LLM.
- Knowledge base maintenance: adding new documents, correcting errors, or changing policies requires an organized process and keeping a record of changes made.
In summary, a RAG works by adding an information retrieval and knowledge search step before text generation. This way, the model no longer depends solely on what it knows from training but relies on external data to support its responses and align its reasoning with the most relevant training data, thereby reducing the likelihood of errors and providing more relevant answers for the user.
When is it recommended to use?
The use of RAG is especially recommended in situations where AI is required to provide accurate, up-to-date, and domain-specific answers.
Some typical cases where RAG is particularly useful include:
- Customer service: support chatbots benefit greatly from RAG. If a customer asks something specific about a product or service, the chatbot could retrieve the exact information from manuals, FAQs, internal company guides, a record of previous responses, etc.
- E-commerce: in an online store, a RAG-powered virtual shopping assistant could add immense value, as it could query the product database in real time to answer questions about availability, features, or updated prices.
- Legal sector: in legal environments, where information accuracy is critical and there are frequent regulatory changes or new case law, RAG is undoubtedly very useful. A RAG-driven legal assistant could search for clauses in relevant laws, regulations, or case rulings and use them to answer a query.
- Banking and finance: in the financial sector, RAG allows virtual assistants to handle sensitive and changing information more reliably. For example, an internal banking bot could retrieve the latest credit policies or current interest rates from an internal database to answer questions from employees or customers.
In general terms, RAG is recommended when:
- The required information isn’t in the model’s training data: if the model needs highly specific company knowledge or data after its training cutoff date, RAG is an excellent option.
- It’s vital to keep answers up to date: for domains where data frequently changes (as in the examples above), RAG allows incorporating those updates without having to retrain the model each time.
- The goal is to reduce model errors and hallucinations: by grounding responses in verifiable data, RAG lowers the risk of hallucinations. It doesn’t eliminate them completely, but it’s a significant improvement.
- Training cost or time is a critical factor: keep in mind that fine-tuning an LLM can be costly in terms of time, computational resources, and money—and it must be repeated every time new documents are added. Training an LLM from scratch is something only massive data centers can afford, since adding new documents post-training would lead to what’s known as catastrophic forgetting. RAG is a much cheaper solution, as it can incorporate information without retraining the system every time new data is added.
When is it not worth using RAG?
Although we’ve seen how useful RAG can be in many cases, it’s not always the ideal option.
There are situations where implementing a retrieval system may not justify the added complexity or resources. Let’s look at some examples:
- General queries solved by the base model: if user questions can be correctly answered with the LLM’s general knowledge, adding RAG might be unnecessary. For example, for a generic assistant that provides simple definitions or general knowledge questions.
- Small or static data domain: if the specialized information fits within a manageable dataset, sometimes it’s simpler to embed that knowledge directly into prompts. For instance, if you only have a 50-page manual that rarely changes.
- Performance and latency limitations: RAG adds extra steps (database searches, document processing) before generating the answer. In environments where speed is critical, this additional latency can be an issue. A RAG system can be less efficient and scalable than an LLM alone, especially if the knowledge base is large and searches are expensive.
- Limited technical resources: implementing RAG requires infrastructure to store and manage the knowledge base and to execute retrieval queries. Not all companies have such capabilities. If there isn’t a technical team to maintain the data repository and fine-tune the search system, a RAG project could be difficult to sustain. For very small businesses or simple projects, it may not be worth the investment compared to using a pre-trained model as is or with basic fine-tuning.
- Cases where creativity matters more than accuracy: if the model’s main task is creative (for example, writing fiction, generating marketing ideas, etc.), using RAG could even be counterproductive, while fine-tuning is the ideal solution for giving the model a particular writing style.
Essentially, we can see that while RAG is highly recommended in certain cases, it’s not universally advisable.
When the required knowledge is stable, limited in scope, or system simplicity is key, other solutions like prompt engineering or light fine-tuning may be more appropriate.
Likewise, if there’s no high-quality content to retrieve, a RAG system will have little to offer. Therefore, it’s always wise to assess each case: if the added complexity of a RAG doesn’t translate into a substantial improvement in answer quality, the investment may not be worthwhile.
What risks does RAG have?
Dependence on retrieval quality
RAG inherits the well-known principle of “garbage in, garbage out.”
That is, if the retrieval module pulls irrelevant or incorrect information (plainly speaking, garbage), the model will generate its response based on that (producing garbage).
For example, if the knowledge base is outdated or contains errors, the assistant might confidently provide incorrect information.
Therefore, it’s essential to keep sources up to date and filter out unreliable ones, since the model doesn’t judge truth—it just uses what it’s given.
Hallucinations and coherence
Although one of RAG’s advantages is that it reduces hallucinations by grounding answers in real data, it doesn’t eliminate them entirely.
The model could still invent connections between the retrieved information and the question or mix data incorrectly.
Additionally, if multiple fragments are retrieved, the model might struggle to synthesize them coherently.
Additional latency
As mentioned, the retrieval step can slow down response time.
For the end user, this appears as a chatbot that takes longer to reply.
If the knowledge base is very large or queries are complex, latency could increase further and worsen the issue.
Therefore, the system must be designed carefully to remain agile—for example, by optimizing indexes or limiting the amount of text returned.
Moreover, in high-demand applications, scalability must be planned even more carefully, as more users and data can multiply the load during retrieval.
Complexity and maintenance cost
As is already clear, a RAG system is more complex than a standalone model.
It requires keeping both the model (if being refined) and the data sources up to date, which involves continuous work: adding new documents, reindexing content, etc.
It’s also important to note that performing searches and managing a vector database can increase computational costs (more memory to store embeddings, more processing for queries), driving overall costs up.
Data security and privacy
RAG often involves feeding the model private or sensitive company data, such as customer information or internal policies.
It’s crucial to ensure that this information isn’t leaked.
One advantage of RAG is that confidential data isn’t permanently “mixed” into the model’s training but remains in a separate database, allowing for some control.
However, if the external knowledge base is compromised, there’s a risk of exposure.
Therefore, it’s vital to implement robust security measures for storing and accessing sources (encryption, access controls, anonymization where appropriate, etc.).
Intellectual property
Undoubtedly, one of the most debated issues around AI is intellectual property—and in a RAG system, this issue becomes even more sensitive.
By retrieving text from existing sources, there’s a possibility of reusing copyrighted content.
If the model quotes entire paragraphs from an external document verbatim to create its answer, it could have legal implications if that content isn’t public or authorized.
This requires extreme care in data usage policies—for example, using RAG only with the organization’s own documents or permitted public sources, or paraphrasing the retrieved information instead of copying it verbatim.
False sense of confidence
A common issue is that RAG system responses may appear entirely reliable simply because they include external data.
Users may assume that, since the response comes from a source, it must always be correct. However, as we’ve seen, if the source was biased or the model misinterpreted the information, the response could still be wrong.
This false sense of confidence means users might not question an incorrect answer simply because it includes data. Therefore, it’s best if the system cites sources and encourages verification—especially in critical fields (health, finance, legal)—by users or domain experts.
Transparency helps, but we must remember that RAG doesn’t guarantee infallibility. It simply increases the likelihood of getting it right.

