

Escrito por Anastasia Kurmakaeva
![]() Hoy vamos a hablar de cómo ha evolucionado el algoritmo de Yandex a lo largo de los últimos años y de sus últimas actualizaciones clave, las cuales han marcado un antes y un después en cómo el buscador analiza las consultas de búsqueda y devuelve resultados en base a las necesidades de los/as usuarios/as. Palekh (2016), Korolyov (2017), y Andromeda (2018) se apoyan en la inteligencia artificial de redes neuronales para entender mejor la intención de búsqueda del usuario, dando un paso más allá de analizar simplemente las palabras clave y preocupándose más por entender su significado.
Hoy vamos a hablar de cómo ha evolucionado el algoritmo de Yandex a lo largo de los últimos años y de sus últimas actualizaciones clave, las cuales han marcado un antes y un después en cómo el buscador analiza las consultas de búsqueda y devuelve resultados en base a las necesidades de los/as usuarios/as. Palekh (2016), Korolyov (2017), y Andromeda (2018) se apoyan en la inteligencia artificial de redes neuronales para entender mejor la intención de búsqueda del usuario, dando un paso más allá de analizar simplemente las palabras clave y preocupándose más por entender su significado.
A pesar del monopolio de Google en la gran mayoría de los países de todo el mundo, la cuota de mercado de Yandex en Rusia continúa predominando por encima del gigante californiano, y, dada su imparable expansión y desarrollo tecnológico, no parece que el escenario vaya a cambiar en los próximos años.
? Según SEJournal, en 2019 un 52% de usuarios/as rusohablantes siguen otorgando preferencia a Yandex, frente al 46% de los internautas que se decantan por Google.
En la misma entrevista concedida a SEJournal por el equipo de Yandex, hemos averiguado también que la penetración de las búsquedas móviles y búsquedas de voz en el motor de búsqueda ruso es cada vez mayor, siendo de aproximadamente 56% y 20% del total, respectivamente.
Palekh
Desde su introducción en noviembre de 2016 con Palekh, Yandex ha ido perfeccionando y afinando cada vez más su algoritmo basado en redes neuronales, para responder a intenciones de búsqueda y consultas más complejas con la ayuda de machine learning, haciendo especial hincapié en aquellas de tipo long tail. En su primer lanzamiento tenía capacidades más limitadas, ya que sólo era capaz de analizar los títulos de las páginas web, pero no el contenido en su totalidad, además de ser considerablemente más lento que su sucesor (sobre el que hablaremos enseguida), procesando alrededor de un 40% de las peticiones hechas al buscador de las 280 millones diarias.
La tecnología de los «vectores semánticos» utilizada por Palekh está basada en la semántica distribucional. Según lo explican en su blog (en ruso), las palabras de miles de millones de consultas son convertidas en números, o, mejor dicho, grupos de 300 números cada uno. Estos son distribuidos a través de un espacio de 300 dimensiones, donde cada documento tiene su propio vector. Si los números que corresponden a una consulta se encuentran cerca de los números que corresponden a un documento en ese espacio, el resultado se considera relevante. Cuanto más próximos estén uno al otro, más relevante será la página devuelta por el buscador.

Dentro de las palabras clave de tipo long tail Yandex distingue varias categorías, que van de más a menos específicas. No siempre las consultas y los resultados más relevantes tendrán palabras en común, lo que ciertamente dificulta el trabajo para el buscador. Por ejemplo:
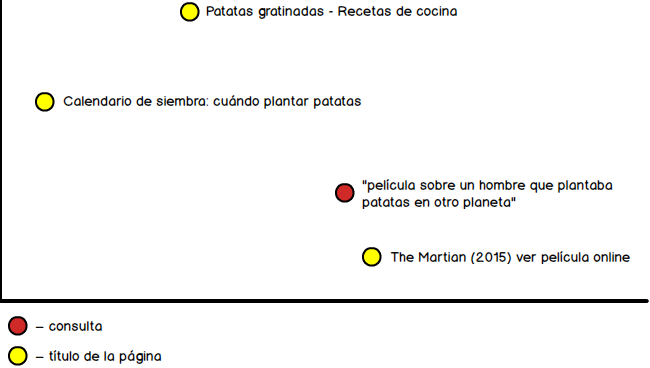
- Consultas donde una persona no recuerda el nombre de la película que ha visto recientemente, pero se le ha quedado grabada una escena muy concreta de ésta: «película sobre un hombre que plantaba patatas en otro planeta» > Marte (The Martian).
- Personas, frecuentemente niños, que todavía no entienden muy bien cómo dirigirse a un buscador y le hablan como si fuera una entidad en sí misma: «yandex, porfi recomiéndame juegos interesantes sobre hadas para la tablet» > Su intención de búsqueda podría resumirse, probablemente, en una página que recomiende juegos con un componente fantástico para las plataformas iOS o Android.
Y es ahí donde surge la necesidad de enseñar al algoritmo a poder dar respuesta a las búsquedas de usuario más naturales y «humanas».
Yandex nos ofrece la siguiente representación gráfica del funcionamiento del algoritmo Palekh, en dos dimensiones para los mortales:
Korolyov
Casi un año después, en agosto de 2017, vio la luz la siguiente gran actualización del algoritmo inteligente de Yandex: Korolyov.
Korolyov se basa en Palekh, pero es todavía más potente. Mientras la actualización anterior solamente se fijaba en la etiqueta title para encontrar correspondencias entre el término de búsqueda introducido por un usuario y los resultados, Korolyov lee y analiza todo el contenido de la página, para devolver resultados mucho más afines al search intent. No sólo eso, sino que su capacidad de tratamiento de documentos en tiempo real se multiplica por mil. Además, como es un sistema basado en inteligencia artificial, su red neuronal va aprendiendo cada vez más, gracias a un análisis minucioso del comportamiento de usuario ante los resultados ofrecidos. Compara la presente consulta con otras que han llevado a un usuario al mismo contenido, o se fija en el tiempo que alguien ha pasado en una página tras haber accedido a través de una consulta X, entre otros indicadores de relevancia.
Por otro lado, el cálculo de los vectores semánticos se realiza en el momento de la indexación de un contenido, permitiendo al buscador establecer conexiones de forma rápida y eficaz. Esto supone un ahorro considerable de recursos, pues sólo necesita procesar un contenido concreto una vez para poder comparar el vector de la consulta introducida con los vectores de las páginas ya conocidos.
El mismo año de la puesta en marcha de Korolyov también tuvo lugar el lanzamiento del asistente IA del Yandex: Alice, hecho que ha impulsado el uso de las búsquedas por voz en el buscador.
Andromeda
 Ya en 2018, llega Andromeda. Esta última actualización conlleva nuevas mejoras, además de seguir desarrollando y enriqueciendo el aprendizaje de su algoritmo inteligente para que la búsqueda de información resulte cada vez más fácil e intuitiva para los/as usuarios/as y el contenido ofrecido sea más relevante, más fiable, y provenga de fuentes de mayor calidad.
Ya en 2018, llega Andromeda. Esta última actualización conlleva nuevas mejoras, además de seguir desarrollando y enriqueciendo el aprendizaje de su algoritmo inteligente para que la búsqueda de información resulte cada vez más fácil e intuitiva para los/as usuarios/as y el contenido ofrecido sea más relevante, más fiable, y provenga de fuentes de mayor calidad.
Llegan nuevas funcionalidades como son las respuestas rápidas, que ofrecen resultados directos y claros a consultas sencillas. Por ejemplo:
- Qué día cae un festivo determinado.
- Qué encuentro de fútbol se celebra hoy.
- Cafeterías cerca de mí.
Otra novedad es Yandex.Experts, donde los/as usuarios/as pueden realizar preguntas sobre una amplia variedad de temáticas a expertos reales si no encuentran respuesta a su consulta en los resultados de búsqueda.
Conclusiones
¿Qué conclusiones podemos sacar de la dirección que está tomando Yandex en estos últimos años y cómo afecta al SEO? En pocas palabras, no observamos grandes diferencias entre Google y Yandex a ese efecto.
- La generación de contenido relevante y de calidad continúa siendo un pilar fundamental. A la hora de crear contenido en nuestra web, debemos orientarlo al usuario, y no al buscador. La redacción correcta y coherente que aporte información de valor es la clave.
- Los sitios web deben ofrecer la mejor experiencia de usuario, y funcionar de forma ágil y rápida para adaptarse a los dispositivos móviles, como hemos visto en este artículo, pues la navegación desde los smartphones también predomina entre los/as internautas rusohablantes.
- Las búsquedas por voz van a cobrar cada vez más protagonismo.
¿Qué novedades en el algoritmo de Yandex crees que nos esperan este año?




Hace poco conocí Yandex y me enamoré perdidamente.
El mapa de calor y otros datos que te permite optimizar todo