

Escrito por Ramón Saquete
Índice
Entender la documentación de schema.org no es una tarea sencilla, ya que para seguirla debemos tener claras abstracciones que son derivadas del modelo de datos RDF y que son, en gran medida, equiparables al modelo de datos orientado a objetos, materia que se estudia transversalmente junto al diseño de software, la programación orientada a objetos y a las bases de datos objetuales. Pero si tenemos los conceptos claros, podremos crear la estructura de datos que mejor se ajuste a la información de nuestra web y al modelo de datos de schema.org, sin estar limitados a lo que aparece en los ejemplos y sin perder la capacidad de que Google pueda entender la información semántica que éstos ofrecen.
Los datos estructurados nos permiten decirle al robot de Google el significado de la información de nuestra web, para que pueda mostrar resultados enriquecidos, incorporar información al knowledge graph, interpretar mejor la información para mostrar resultados más relevantes e incluso para responder directamente a preguntas en la posición cero. Todo esto nos debería traer mayor tráfico de buena calidad.
Los datos estructurados, también facilitan la tarea a los scrapers que quieran extraer el contenido de nuestra web para incorporarlo a sus bases de datos. Si tenemos información que pueda ser valiosa para otros, deberíamos evitar esto bloqueando los robots «malos» desde la configuración del servidor.
Con anterioridad, ya se explicó en este blog los conceptos básicos sobre datos estructurados y schema.org, os recomiendo que lo leáis si no sabéis de qué estoy hablando aquí. Si todo esto ya lo tenéis claro, vamos a profundizar en el tema.
Conceptos básicos del modelo de datos de schema.org
A continuación, vamos a ver los conceptos de clase, propiedad e instancia de una clase que son básicos para entender cómo se modela la información con datos estructurados, ya que schema.org es un vocabulario restringido a una serie de elementos, donde se usan estos conceptos para definir dichos elementos.
Clase
Los datos estructurados se usan para definir cosas, y éstas pueden ser de cualquier clase o tipo de cosa, como por ejemplo: personas, lugares, productos, acciones como crear o buscar, trabajos creativos como un blog o un libro, eventos como conciertos o partidos y cosas intangibles como ofertas o servicios. A estas clases de cosas, aquí las vamos a llamar simplemente clases, aunque también las podréis encontrar con el nombre de tipos o entidades.
Propiedad o atributo
La forma de definir cada uno de los tipos de información o clases, es haciendo uso de propiedades a las que podemos asignar el valor que queramos. Por ejemplo, si tenemos una clase de cosa «producto», dentro podría tener una propiedad «nombre», a la que se le podría asignar el valor «taza» y, otra propiedad «color», a la que se le podría asignar el valor «rojo».
Cada clase puede tener unas propiedades distintas y schema.org, lo que nos va a decir, es qué propiedades tiene cada una de las clases de cosas que podemos definir. Es decir, para la clase producto, nos va a decir que tiene la propiedad «nombre», la propiedad «color» y otras tantas que son propias de los productos. Para otro tipo de clase como «evento», podemos tener otras propiedades como «fecha de comienzo» y «fecha de finalización», que no tendrían sentido en un producto.
Objeto o instancia de una clase
Cuando cogemos una clase y le asignamos unos valores a cada propiedad para la que tengamos información, se dice que lo que estamos haciendo es crear una instancia de la clase. Por ejemplo si le damos datos a un producto concreto, como la taza de color rojo del ejemplo anterior, diríamos que esa taza es una instancia u objeto de la clase producto.
Así que las clases son como plantillas que nos dicen qué datos hay que rellenar y, cuando las rellenamos, tenemos los objetos o instancias concretas que queremos obtener.
Relaciones por composición de objetos
En este punto permitidme introducir nomenclatura que es más propia de la programación y el modelo de datos orientado a objetos, que del modelo RDF, pero que ayudan a simplificar la explicación.
Ya hemos visto que a una propiedad le podemos asignar valores, pero estos valores pueden ser de distintos tipos que aquí vamos a clasificar en: tipos simples o tipos compuestos. Los tipos simples, consisten en asignar un valor de un tipo concreto. Para que lo entendáis, lo más fácil es que le deis un vistazo a la siguiente lista, donde enumero todos los tipos simples de datos que permite schema.org:
- Valor de tipo booleano: la propiedad puede ser cierta o falsa. Por ejemplo la clase CreativeWork (trabajo creativo), tiene la propiedad isAccessibleForFree (esAccesibleGratuitamente), a la que podemos asignar el valor true o false, dependiendo de si es gratis o no.
- Valor de tipo fecha: se le asigna una fecha a la propiedad en formato ISO 8601. Por ejemplo, la clase Product, tiene la propiedad releaseDate (fecha de lanzamiento) a la que podemos asignar el valor 2018-01-30 que equivale a 30/01/2018.
- Valor de tipo fecha y hora: se le asigna una fecha y hora a la propiedad en formato ISO 8601.
- Valor de tipo número: puede ser un número entero o con decimales.
- Valor de tipo texto: esto es un texto arbitrario, como por ejemplo el texto «taza» que he utilizado en un ejemplo anterior para la propiedad «nombre». Este texto puede ser del tipo URL.
- Valor de tipo hora con el formato: hh:mm:ss[Z|(+|-)hh:mm].
Las propiedades que permiten el uso de valores con tipos compuestos, son aquellas a las que podemos asignar uno o varios objetos, de una o distintas clases, de forma que dentro de esa propiedad vamos a poder definir a su vez varías propiedades más. Veamos un ejemplo: la clase producto, tiene la propiedad review (reseña) a la que podemos asignar un valor, que será una instancia de la clase Review, donde, a su vez, podemos rellenar la propiedad «autor» como una instancia de la clase Person, donde finalmente podríamos rellenar la propiedad name de la persona con un tipo de dato simple de texto. Así que podemos decir, que tenemos un objeto producto que se compone de un objeto reseña que a su vez se compone de un autor. Esto es lo que se conoce en el modelo orientado a objetos como relación por composición.

Al crear una instancia de un producto, podríamos navegar por todas las relaciones de composición posibles y llegaríamos a especificar la información necesaria para rellenar casi todas las clases que están definidas en schema.org. Pero esto no sería correcto dado que la idea de los datos estructurados no es añadir toda la información posible, sino definir para Google sólo aquella información que estamos mostrando al usuario, por lo que no es recomendable añadir un JSON-LD con toda la información de la que dispongamos sólo para definir un producto.

A veces nos podemos encontrar propiedades marcadas en color azul, en lugar de en rojo. Éstas son propiedades que todavía no han sido aprobadas, así que tienen más papeletas de darnos problemas a la hora de que las interprete Google correctamente.
Schema.org nos dice el tipo o tipos de datos que puede tener cada propiedad, aunque no especifica algunas cosas que tiene en cuenta Google por su parte y que son las siguientes:
- No deja claro cuando podemos repetir varias veces la misma propiedad. Cuando esto ocurre, cada repetición puede tener valores con instancias de distintas clases.
- No especifica cuando una propiedad es obligatoria o recomendada para Google.
- No dice cuando un tipo de datos compuesto lo podemos reemplazar por un dato de tipo simple de texto y Google no va a tener problemas para leerlo. Aunque esto se puede hacer casi siempre, a pesar de que en la definición no se especifique.
Es normal que schema.org no especifique estos aspectos, puesto que es un vocabulario definido por varios buscadores y, después, cada uno puede añadir sus propias restricciones sobre este modelo.
En la documentación de Google sobre datos estructurados podemos encontrar algo de la información que nos faltaría en schema.org para hacer una implementación correcta para Google.
Por lo tanto, para saber si los datos estructurados que estamos escribiendo en base a schema.org, cumplen con los requisitos de Google, no nos queda más remedio que comprobarlo después de escribirlos, utilizando la herramienta de Google para comprobar los datos estructurados. Y si lo que nos interesa es crear datos estructurados para generar rich snippets, también podemos usar la herramienta de resultados enriquecidos.
Relaciones por herencia de clases
Hay propiedades que son iguales en varias clases y para evitar tener que definir la misma propiedad varias veces en cada clase, schema.org hace uso de un concepto llamado herencia de clases. Éste consiste en que una clase puede heredar de otra, estableciendo una relación de clase padre y clase hija, de forma que la clase hija hereda todas las propiedades de la clase padre. Así, una clase padre puede tener varias hijas que compartan las mismas propiedades.
En schema.org la clase padre por excelencia es la clase Thing (cosa), que define propiedades habituales, tales como: nombre, descripción, url e imagen. Como todas las clases de schema.org heredan de Thing, sus propiedades se pueden definir en cualquier objeto que instanciemos. Ejemplo:

Así mismo, podemos encontrarnos con clases que hereden de otra y que su vez hereden de otra más y así sucesivamente, de forma que hereden propiedades de varias clases, como en el ejemplo:
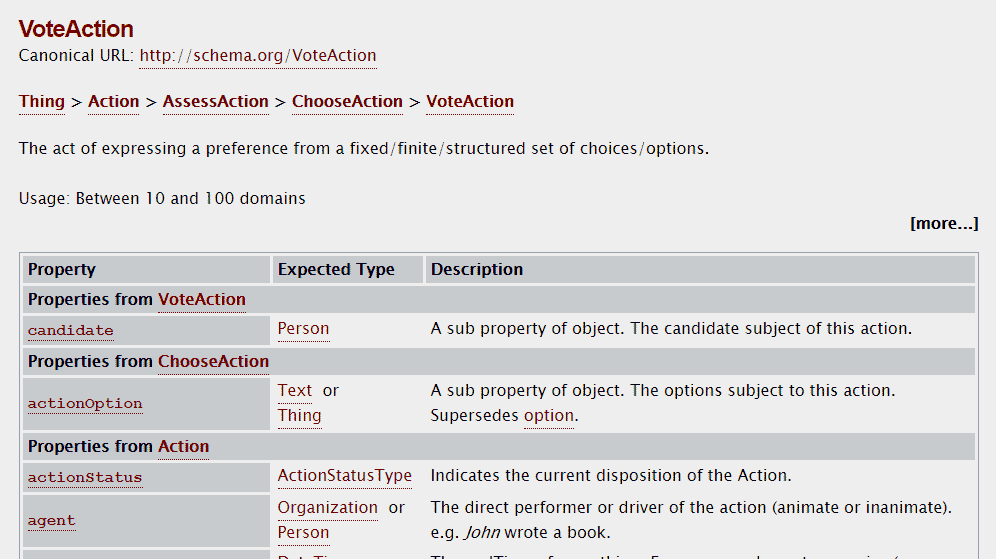
Si vamos al final de la definición de una clase, además podemos ver las clases hijas de la clase actual. En la siguiente captura vemos las clases hijas de la clase Product:
En este enlace tenemos la jerarquía de clases completa. Este recurso es útil a la hora de ayudarnos a decidir qué clase de objeto es el más adecuado para definir la información que aparece en la web.
Polimorfismo
Los datos estructurados permiten tipos de datos dinámicos u objetos polimórficos (del griego: que puede adoptar muchas formas). Que los objetos sean polimórficos, significa que un tipo de datos compuesto puede adoptar la forma de cualquiera de sus clases hijas o incluso de una clase padre. Por ejemplo, la clase SocialMediaPosting tiene la propiedad sharedContent que es del tipo CreativeWork. Éste, por su parte, hereda de Thing y tiene varias clases hijas, como por ejemplo Book, por lo que podríamos sin problemas asignar un objeto de tipo Thing o Book a la propiedad sharedContent (aunque la especificación diga que es un CreativeWork) y no sería incorrecto.
Esta característica, que pocas veces se tiene en cuenta a la hora de modelar nuestros datos, brinda un gran abanico de posibilidades, permitiéndonos definir nuestros datos con mayor detalle (usando clases hijas) o, con menos detalle (usando clases padre), si no tenemos claro lo que son en realidad.
Tipos enumerados
Los tipos enumerados son aquellos que admiten valores de una lista. Por ejemplo, la propiedad bookFormat de la clase Book, admite valores de la clase BookFormatType. Si vamos a su definición vemos que en realidad no es una clase, si no una enumeración, porque hereda de Enumeration y también porque las enumeraciones suelen llevar al final del nombre la palabra Type. Si vamos a la descripción, vemos que podemos asignarle los siguientes tipos de valores enumerados:
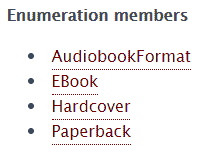
Para asignar un valor enumerado a una propiedad, debemos escribir la URL que representa el valor que queremos. Por ejemplo: «bookFormat=http://schema.org/Paperback».
Hay enumeraciones que no llevan la coletilla Type. Éstas cogen valores definidos en otro vocabulario distinto a schema.org llamado Good Relations, por ejemplo el tipo BusinessFunction, pero el funcionamiento es el mismo que el de cualquier otra enumeración.
También podemos inventarnos un valor de texto y asignárselo, pero entonces el robot no entenderá el significado de ese valor.
Pasar del modelo conceptual al código
Una vez que ya hemos elegido qué clase vamos a utilizar, con qué propiedades la vamos a rellenar y qué tipos de datos hemos elegido para cada una de las propiedades disponibles, tenemos que convertir este modelado de datos a uno de los formatos de datos estructurados que entiende Google. Vamos a ver un ejemplo suponiendo que tenemos el siguiente modelado de datos para un objeto libro compartido en una red social y además vamos añadir el autor del libro:
https://schema.org/SocialMediaPosting <= cogemos el tipo de datos publicación de red social
sharedContent = http://schema.org/Book <= aunque el tipo de datos de sharedContent es CreativeWork cogemos un tipo derivado haciendo uso del polimorfismo
name = Marketing online 2.0
isbn = 978-8441532649
bookFormat = http://schema.org/Paperback <= como bookFormat usa una clase que en realidad es una enumeración, le asignamos directamente el valor que le corresponde.
publisher = Anaya Multimedia <= según la especificación, la editorial debe ser de la clase organización o persona. Vamos a ver qué ocurre si nos saltamos la especificación y le asignamos un texto directamente.
author = https://schema.org/Person <= aquí la especificación nos dice que podemos poner una organización o una persona, así que ponemos una persona. Si fuera necesario, podríamos añadir varios autores y algunos podrían ser personas y otros organizaciones.
givenName = Fernando
familyName = Maciá
jobTitle = CEO
brand = https://schema.org/Organization
name = Human Level
Hay muchas formas de expresar el modelo de datos conceptual, en el presente caso he escogido esta representación textual simple pero también podría haberlo representado en UML.
Si Google tiene esta información puede responder, entre otras cosas, a la pregunta ¿quién es el autor del libro Marketing online 2.0? Pero para eso, necesitamos convertirlo a código, que puede ser JSON-LD, Microdatos o RDFa. Primero vamos a ver cómo hacerlo con microdatos y después con JSON-LD, que es el formato actualmente sugerido por Google como mejor opción.
Para transformalo a microdatos, simplemente tenemos que pensar que cada instancia de clase se define con «itemscope» e «itemtype=[URL de la clase en schema.org]» y las propiedades con «itemprop=[nombre de la propiedad]». Al crear relaciones de composición, tendremos que utilizar «itemscope», «itemtype» e «itemprop» a la vez, porque estamos declarando el tipo de clase que vamos a usar de una propiedad en concreto. A continuación tenéis el modelo de arriba escrito con microdatos, para que podáis compararlo:
<div itemscope itemtype="https://schema.org/SocialMediaPosting">
<div itemprop="sharedContent" itemscope itemtype="http://schema.org/Book">
<p>Libro: <span itemprop="name"> Marketing online 2.0</span></p>
<p>ISBN: <span itemprop="isbn"> 978-8441532649</span></p>
<p>
Formato: Tapa blanda <link itemprop="bookFormat" href="http://schema.org/Paperback" />
</p>
<!-- cuando que tenemos que definir una propiedad que no aparece igual al usuario y tiene un tipo de datos URL, se debe usar la etiqueta link con el atributo href, si es del tipo de datos Text, usaremos la etiqueta meta con el atributo content !-->
<p>Editorial: <span itemprop="publisher">Anaya Multimedia</span></p>
<div itemprop="author" itemscope itemtype="https://schema.org/Person">
<p><span itemprop="givenName">Fernando</span>
<span itemprop=" familyName">Maciá</span>
</p>
<p>
<span itemprop="jobTitle">CEO</span> de
<span itemprop="brand" itemscope itemtype="https://schema.org/Organization">
<span itemprop="name">Human Level</span>
</span>
</p>
</div>
</div>
</div>
Si ejecutamos este código en la herramienta de datos estructurados de Google, no nos sale ningún error, sólo un par de advertencias de propiedades recomendadas, por lo que Google sería capaz de interpretarlo correctamente.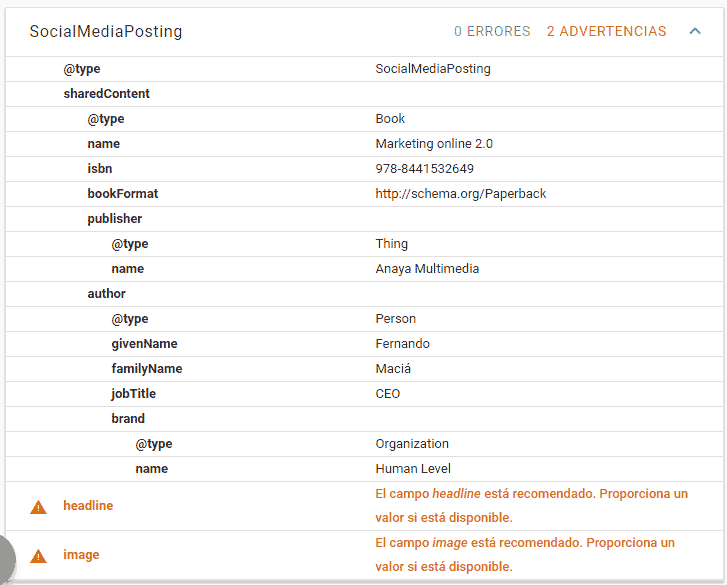
Otra cosa a tener en cuenta en este ejemplo, es que la propiedad Publisher, según schema.org debería ser de la clase Organization o Person, sin embargo, al asignarle un valor de tipo simple directamente, la herramienta para comprobar datos estructurados no nos da error, sino que le asigna la clase Thing, haciendo uso del polimorfismo sin darnos cuenta. Así que Google no sabe si es una organización o una persona pero sabe que es la editorial. Esto es útil saberlo, para cuando nosotros mismos no estemos seguros de qué significado darle a alguna propiedad.
Con JSON-LD el código es más simple, aquí tenéis como quedaría el código equivalente al de arriba:
<script type="application/ld+json">
{
"@context":"https://schema.org/",
"@type":"SocialMediaPosting",
"sharedContent":{
"@type":"Book",
"name":"Marketing online 2.0",
"isbn":"978-8441532649",
"bookFormat": "Paperback",
"publisher":"Anaya Multimedia",
"author":{
"@type":"Person",
"givenName":"Fernando",
"familyName":"Maciá",
"jobTitle":"CEO",
"brand":{
"@type": "Organization",
"name": "Human Level"
}
}
}
}
</script>
Aquí definimos el espacio de nombres del vocabulario al principio «https://schema.org/», así que no es necesario repetirlo después en el resto del código. También sería válido poner «http://schema.org», aunque la página esté bajo HTTPS, puesto que esto no es un enlace, sino una forma de decir que todas las clases que vamos a usar, pertenecen a schema.org. Los espacios de nombres se usan en RDF para evitar que dos clases con el mismo nombre y de distintos vocabularios se confundan, pero aquí, de momento, tendremos siempre un sólo espacio de nombres.
Si en alguna propiedad tuviésemos varios valores, en microdatos simplemente la repetiríamos, pero en JSON-LD lo ponemos con corchetes. Supongamos que queremos definir un libro con varias editoriales y varios autores, veamos cómo quedaría con microdatos y con su JSON-LD equivalente:
<div itemscope itemtype="http://schema.org/Book">
<p>Editorial: <span itemprop="publisher">editorial1</span>,
<span itemprop="publisher">editorial2</span></p>
<div itemprop="author" itemscope itemtype="https://schema.org/Person" >
<p><span itemprop="name"> autor1</span></p>
</div>
<div itemprop="author" itemscope itemtype="https://schema.org/Person" >
<p><span itemprop="name"> autor2</span></p>
</div>
</div>
<script type="application/ld+json">
{
"@context":"https://schema.org/",
"@type":"Book",
"publisher": ["editorial1", "editorial2"],
"author":[
{
"@type":"Person",
"name":"autor1"
},
{
"@type":"Person",
"name":"autor2"
}]
}
</script>
Conclusiones
Los datos estructurados (o semiestructurados como deberían llamarse técnicamente en realidad), son difíciles de modelar, pero lo serían aún más si utilizáramos otros vocabularios definidos con RDF u OWL. Me estoy refiriendo a los vocabularios de la web semántica, como FOAF, SIOC, SKOS o Dublin Core, ya que en estos aparecen relaciones más complicadas de las que ya hemos visto en el vocabulario propuesto por los buscadores en schema.org. Así que aplicando correctamente schema.org, lo tendremos más fácil y, con las herramientas de Google, vamos a poder estar seguros de que el robot va a saber interpretar el significado de nuestros datos.
Referencias adicionales
- Datos estructurados equivalentes a etiquetas semánticas de5 – Ramón Saquete.
- HTML5
- JSON
- Herramienta de validación de datos estructurados de Google
- Validador de implementación de Schema con marcado JSON
- Introducción a los datos estructurados – Google.
- Qué son los datos estructurados y schema.org – María Navarro.
- Datos estructurados – preguntas y respuestas con Google.
- Qué son los Featured Snippets – Rocío Rodríguez.
- Fragmentos enriquecidos para conseguir más tráfico – Jose E. Vicente.



