

Escrito por Ramón Saquete
Índice
Con el tiempo Google ha mejorado mucho la indexación de JavaScript y AJAX. Al principio no indexaba nada ni seguía los enlaces que aparecían en el contenido cargado de esta forma, pero después empezó a indexar algunas implementaciones y a mejorar poco a poco. Actualmente es capaz de indexar muchas implementaciones distintas y de seguir los enlaces que aparecen en el contenido cargado por AJAX o la API Fetch, pero no obstante, siempre habrá casos en los que pueda fallar.

Para poder analizar los casos en los que Google puede no indexarnos la web, primero tenemos que tener claro el concepto de Client Side Rendering (CSR). Éste implica que el HTML se pinta en el cliente con JavaScript, normalmente haciendo un uso excesivo de AJAX. Originalmente, las webs pintaban el HTML siempre en el servidor (Server Side Rendering o SSR), pero desde hace un tiempo, el CSR se ha popularizado con la aparición de frameworks de JavaScript como Angular, React y Vue. Sin embargo, el CSR, repercute negativamente en la indexación, en el rendimiento del pintado de la web y, en consecuencia, al posicionamiento.
Tal y como ya se explicó en una entrada anterior, para asegurar la indexación en todas las arañas y situaciones, además de tener un buen rendimiento, la mejor solución es utilizar un framework universal, ya que con esta aproximación empleamos lo que algunos llaman pintado híbrido (Hybrid Rendering), pintándose en el servidor en la primera carga y en el cliente con JavaScript y AJAX en la navegación a los siguientes enlaces. Aunque en realidad, hay otras situaciones en las que también sería válido usar el término Hybrid Rendering.
A veces ocurre que la empresa de desarrollo usa CSR y no nos ofrece la opción de usar un framework universal. En estos desarrollos CSR nos encontraremos con problemas que serán mayores o menores dependiendo de la araña y sus algoritmos de posicionamiento. En esta entrada, vamos a analizar cuáles son esos problemas con la araña de Google y cómo solucionarlos.
Problemas del CSR en la carga inicial de una página
En primer lugar vamos a analizar los problemas de indexación que se producen nada más entrar en una URL desde fuera de la web y cuando el HTML se pinta en el cliente con JavaScript.
Problemas debidos a la lentitud del pintado
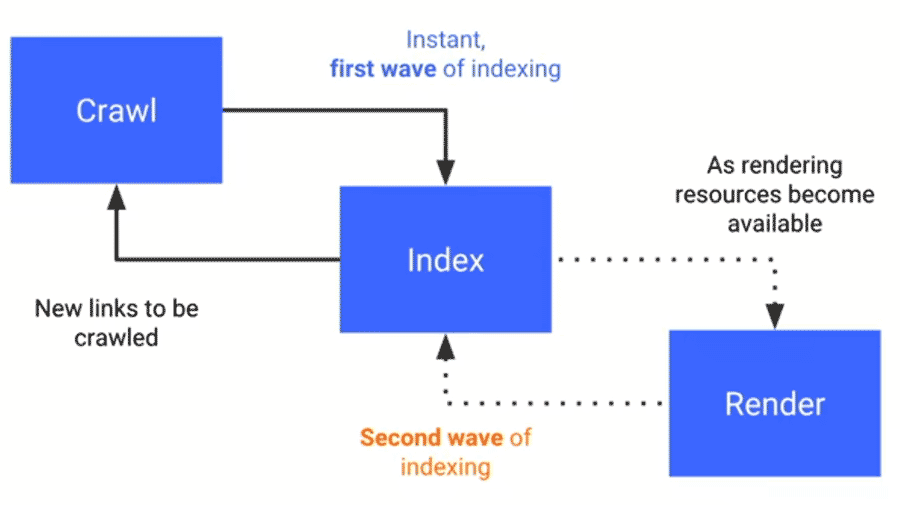
Google realiza indexación de la siguiente forma:
- Rastreo: Googlebot pide una URL al servidor.
- Primera ola de indexación: indexa el contenido que se pinta en el servidor instantáneamente y se obtienen nuevos enlaces para rastrear.
- Genera el HTML que se pinta en el cliente ejecutando el JavaScript. Este proceso es muy costoso computacionalmente (puede realizarse al momento o llegar a demorarse incluso días, a la espera de tener recursos disponibles para realizarlo).
- Segunda ola de indexación: con el HTML pintado en el cliente, se indexa el contenido que faltaba y se obtienen nuevos enlaces para rastrear.
A parte de que las páginas pueden tardar más tiempo en indexarse completamente, retrasando así la indexación de páginas enlazadas desde estas, si el pintado de una página es lento, el renderer de Googlebot puede dejar partes sin pintar. En pruebas que hemos realizado desde la opción de «rastrear como Google» de Google Search Console, en la captura que genera no hemos visto que pinte nada que tarde más de 5 segundos en mostrarse. Sin embargo, sí que indexa el HTML generado pasados estos 5 segundos. Para entender porque ocurre esto, hay que tener en cuenta que el renderer de Google Search Console primero construye el HTML ejecutando el JavaScript con el renderer de Googlebot y después pinta los píxeles de la página, siendo la primera tarea la que se debe tener en cuenta para la indexación y a la que nos referimos con el término CSR. En Google Search Console podemos ver el HTML generado en la primera ola de indexación y no el que genera el renderer de Googlebot.
En pruebas que hemos realizado, cuando el pintado del HTML ha tardado más de 19 segundos ya no ha llegado a indexar nada. Aunque este es un tiempo grande, en determinados casos se puede llegar a superar, sobre todo si hacemos un uso intensivo de AJAX, ya que en estos casos, el renderer de Google, al igual que en cualquier renderer, tiene que esperar a que ocurran los siguientes pasos:
- Se descarga el HTML y se procesa para solicitar los archivos enlazados y crear el DOM.
- Se descarga el CSS, se procesa para solicitar los archivos enlazados y crear el CSSOM.
- Se descarga el JavaScript, se compila y se ejecuta para lanzar la petición AJAX (o peticiones).
- La petición AJAX pasa a una cola de espera de peticiones, aguardando a ser atendida junto al resto de archivos solicitados.
- Se lanza la petición AJAX que tiene que viajar por la red hasta el servidor.
- El servidor atiende la petición devolviendo la respuesta por la red y, finalmente, hay que esperar a que el JavaScript se ejecute, para que pinte el contenido en la plantilla HTML de la página.
Los tiempos de las peticiones y descargas, del proceso anterior, dependen de la carga de la red y del servidor en ese momento, y además, Googlebot sólo utiliza el protocolo HTTP/1.1. Éste es más lento que el protocolo HTTP/2 porque las peticiones se atienden una detrás de otra y no todas a la vez. Es necesario que tanto el cliente como el servidor permitan HTTP/2 para que se utilice, por lo que Googlebot utilizará HTTP/1.1 aunque nuestro servidor admita HTTP/2. En definitiva, esto significa que Googlebot espera a que termine cada petición para lanzar la siguiente y es posible que no intente paralelizar algunas peticiones abriendo varías conexiones, tal y como lo hacen los navegadores (aunque no sabemos a ciencia cierta como lo hace). Por lo tanto, nos encontramos ante una situación en la que podríamos llegar a superar esos 19 segundos que hemos estimado.
Imaginad, por ejemplo, que entre imágenes, CSS, JavaScript y peticiones AJAX, se lanzan más de 200 peticiones que tardan 100 milisegundos cada una. Si a las solicitudes AJAX les toca al final de la cola, probablemente superaremos el tiempo requerido para que se indexe su contenido.
Por otro lado, debido a estos problemas de rendimiendo del CSR, obtendremos una nota peor para la métrica FCP (First Contentful Paint) de PageSpeed para el WPO del pintado y en consecuencia peor posicionamimento.
Problemas de indexación:
A la hora de indexar contenido que se pinta en el cliente, Googlebot se puede encontrar con los siguientes casos que evitarán la indexación del HTML generado con JavaScript:
- Se usa una versión de JavaScript que no reconoce el crawler.
- Se utiliza una API de JavaScript que no reconoce Googlebot (actualmente se sabe que Web Sockets, WebGL, WebVR, IndexedDB y WebSQL no están soportados – más información en https://developers.google.com/search/docs/guides/rendering).
- Los archivos JavaScript están bloqueados por robots.
- Los archivos JavaScript se sirven por HTTP y la web está en HTTPS.
- Hay errores de JavaScript.
- Si la aplicación pide permisos al usuario para hacer algo y de esto depende que se pinte el contenido principal, no se pintará porque Googlebot deniega por defecto cualquier permiso que se le pida.
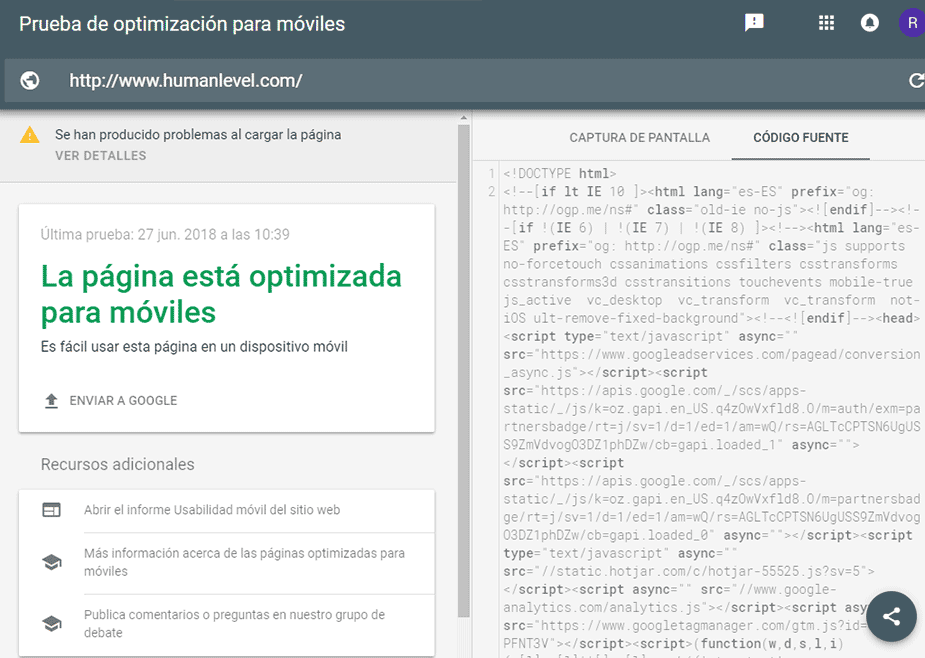
Para descubrir si tenemos alguno de estos problemas, debemos usar la herramienta de Google «mobile friendly test«. Ésta nos muestra una captura de cómo se pinta la página en la pantalla, al igual que hace Google Search Console, pero además, nos muestra el código HTML que genera el renderer (como ya hemos comentado), los registros de logs de errores de JavaScript que pueda tener el código y las funcionalidades de JavaScript que el renderizador no sabe interpretar todavía. Así que deberíamos aplicar esta herramienta a las URLs representativas de cada plantilla de página del sitio, para poder estar seguros de que la web es indexable.
En el HTML que nos genera la herramienta anterior, tenemos que tener en cuenta que todos los metadatos (URL canónica incluida), serán ignorados por el robot ya que Google sólo tiene en cuenta está información cuando se pinta en el servidor.
Ahora vamos a ver qué ocurre cuando navegamos por un enlace cuando ya estamos dentro de la web y el pintado del HTML se realiza en el cliente.
Problemas de indexación
Al contrario que con el CSR en la carga inicial, la navegación a la siguiente página cambiando el contenido principal por JavaScript es más rápido que el SSR. Pero tendremos problemas al indexar si:
- Los enlaces no tienen una URL válida en su atributo href que devuelva 200 OK.
- El servidor devuelve error al acceder a la URL directamente sin JavaScript o con JavaScript activado y borrando todas las caches. Cuidado con esto, si navegamos por la página pinchando desde un enlace puede parecer que funciona porque la carga la realiza el JavaScript. Incluso accediendo directamente, si la web usa un Service Worker, la web puede simular que sí responde correctamente, cargando el contenido de la cache del mismo. Pero Googlebot es una araña sin estado, por lo que no tiene en cuenta ninguna cache de Service Worker o cualquier otra tecnología de JavaScript como Local Storage o Session Storage, así que obtendrá un error.
Además, para que la web sea accesible, la URL debe cambiar utilizando JavaScript con la API del historial como ya expliqué en la entrada AJAX accesible e indexable.
¿Qué ocurre con los fragmentos ahora que Google puede indexar AJAX?
Los fragmentos son la parte de la URL que puede aparecer al final de estas y que lleva una almohadilla. Ejemplo:
http://www.humanlevel.com/blog.html#ejemploEste tipo de URLs no llegan nunca al servidor, se gestionan sólo en el cliente, de forma que al pedir la URL de arriba al servidor, llegaría la petición de «http://www.humanlevel.com/blog.html» y en el cliente el navegador moverá el scroll al fragmento del documento al que hace referencia. Este es el uso normal y la intención original de estas URLs, que se popularizó con el nombre ancla, aunque un ancla, en realidad, es cualquier enlace (la etiqueta «a» en HTML viene de anchor). Sin embargo, antiguamente también se han usado los fragmentos para modificar las URLs por JavaScript en las páginas cargadas por AJAX, con la intención de que el usuario pudiese navegar por el historial. Esto se implementaba así porque antes el fragmento era la única parte de la URL que se podía modificar por JavaScript, así que los desarrolladores aprovecharon esto para darles un uso para el que no estaban pensados. Esto cambió hace años con la aparición de la API del historial, puesto que ésta ya permitía modificar la URL completa por JavaScript.
Cuando Google no era capaz de indexar AJAX, si una URL cambiaba su contenido utilizando AJAX en base a la parte de su fragmento, sabíamos que sólo se iba a indexar la URL y el contenido sin el fragmento. Entonces, ¿qué ocurre con las páginas con fragmentos ahora que Google es capaz de indexar AJAX? Pues que el comportamiento es exactamente el mismo. Si enlazamos una página con un fragmento y ésta cambia su contenido al acceder con el fragmento, se indexará el contenido que tenía sin el mismo y la popularidad irá a esta URL, porque Google confía en que el fragmento se va a utilizar como ancla y no para cambiar el contenido, como debe ser.
Sin embargo, Google sí que indexa actualmente las URLs con hashbang (#!). Esto se implementa sin tener que hacer nada más que añadir la exclamación, y Google hace que funcione para mantener la retrocompatibilidad con una especificación obsoleta para hacer AJAX indexable. Pero no se recomienda hacer esto porque ahora se implementa con la API del historial y, además, porque Google podría dejar de indexar las URLs con hashbang en cualquier momento.
Bloqueo de la indexación de respuestas parciales por AJAX
Cuando se lanza una petición por AJAX a URLs de una API REST o GraphQL, se devuelve un JSON o un trozo de página que no queremos que se indexe. Así que se debe bloquear la indexación de las URLs a las que se dirigen estas peticiones.
Antiguamente se podía realizar el bloqueo con robots.txt, pero desde que existe el renderer de Googlebot, no podemos bloquear asi ningún recurso que se use para el pintado del HTML.
En la actualidad, Google es un poco más listo y no suele tratar de indexar las respuestas con JSONs, pero si queremos estar seguros de que no se indexan, la solución universal para todas las arañas, es hacer que las URLs que se usan para AJAX sólo admitan peticiones por el método POST, puesto que éste no es utilizado por las arañas. Cuando llegue una petición por GET al servidor, éste debería devolver error 404. De cara al desarrollo, esto no obliga a quitar los parámetros en la parte de la QueryString de la URL.
También existe la posibilidad de añadir a las respuestas AJAX la cabecera HTTP «X-Robots-Tag: noindex» (inventada por Google) o que estas respuestas se devuelvan con códigos 404 o 410. Si estas técnicas se usan con contenido que se carga directamente desde el HTML, no se indexará, al igual que si lo hubiésemos bloqueado a través del archivo robots.txt. Sin embargo, como es el JavaScript el que pinta la respuesta en la página, Google no establece la relación entre esta respuesta y el JavaScript que pinta el contenido, por lo que hace exactamente lo que queremos. Es decir, no indexar la respuesta parcial e indexar el HTML generado completo. Pero cuidado, esto no quiere decir que algún día cambie este comportamiento y se nos desindexe el contenido cargado por AJAX si aplicamos esta técnica.
Conclusión
Google ahora puede indexar JavaScript y AJAX, pero es inevitable que esto conlleve un coste superior a la indexación del HTML ya «masticado» en el servidor, por lo que el SSR es y será la mejor opción durante bastante tiempo más. Pero si no tenéis más remedio que enfrentaros a una web totalmente CSR o con alguna parte que use CSR, ya sabéis cómo lidiar con ello.




Genial tu explicación Ramón, estoy casualmente con un cliente que va a «la suya» y tengo estos problemas, el tio mete plugins y quita, como le viene en gana, pero de tanto análisis y mas códigos (sobre todo en la parte superior de la página), es que los resultados estan costando muchísimo, gracias por aclararme algunos conceptos.