

Written by Ramón Saquete
Índice
Over time Google has greatly improved JavaScript and AJAX indexing. At first it did not index anything or follow the links that appeared in the content loaded in this way, but then it started indexing some implementations and gradually improved. It is currently capable of indexing many different implementations and following links that appear in content loaded by AJAX or the Fetch API, but nevertheless, there will always be cases where it may fail.

In order to analyze the cases in which Google may not index our website, we must first be clear about the concept of Client Side Rendering (CSR). This involves the HTML being painted on the client with JavaScript, usually making excessive use of AJAX. Originally, websites always painted HTML on the server(Server Side Rendering or SSR), but for some time now, CSR has become popular with the emergence of JavaScript frameworks such as Angular, React and Vue. The CSR, however, has a negative impact on indexing, on the performance of the website and, consequently, on the positioning.
As already explained in a previous post, for ensure indexing in all spiders and situationsand also have a good performance, the best solution is to use a universal framework. This approach employs what some people call hybrid painting (Hybrid Rendering), painting on the server on the first load y on the client with JavaScript and AJAX in the navigation to the following links. In reality, however, there are other situations in which the term Hybrid Rendering could also be used.
Sometimes it happens that the development company uses CSR and does not offer us the option of using a universal framework. In these CSR developments we will encounter problems that will be greater or lesser depending on the spider and its positioning algorithms. In this post, we are going to analyze what are those problems with the Google spider and how to fix them.
CSR problems on initial loading of a page
First we are going to analyze the indexing problems that occur as soon as a URL is entered from outside the web and when the HTML is painted on the client with JavaScript.
Problems due to slow painting time
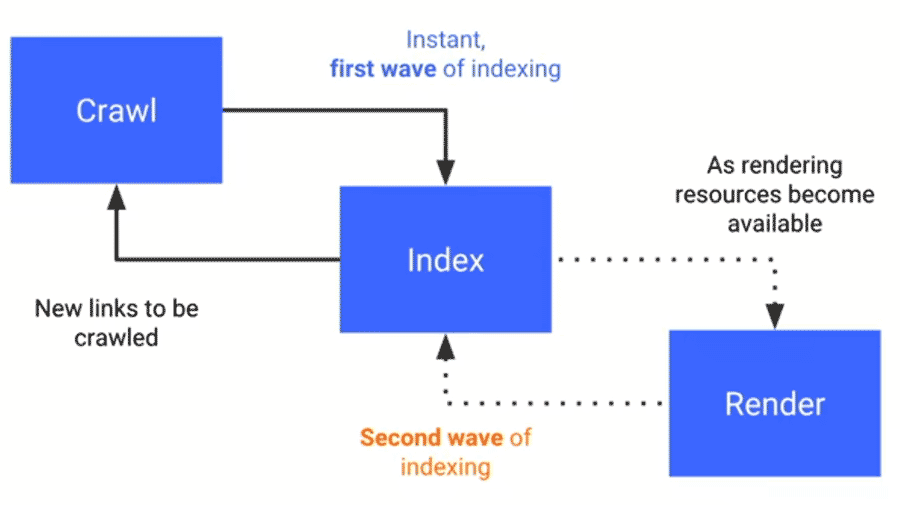
Google performs indexing as follows:
- Crawling: Googlebot requests a URL from the server.
- First wave of indexing: indexes the content that is painted on the server instantly and new links are obtained for crawling.
- Generates the HTML that is painted on the client by executing the JavaScript. This process is computationally very costly (it can be done on the spot or even take days, while waiting for resources to be available to do it).
- Second wave of indexing: with the HTML painted on the client, the missing content is indexed and new links are obtained for crawling.
Apart from the fact that pages may take longer to be fully indexed, thus delaying the indexing of pages linked from them, if a page is painted slowly, the Googlebot renderer may leave parts unpainted. In tests that we have performed from the “crawl as Google” option of Google Search Console, we have not seen anything that takes more than 5 seconds to be displayed in the screenshot it generates. However, it does index the generated HTML after these 5 seconds. To understand why this happens, it is necessary to take into account that the Google Search Console renderer first builds the HTML by running the JavaScript with the Googlebot renderer and then paints the pixels on the page.The first task is the one to be taken into account for indexing and is referred to by the term CSR. In Google Search Console we can see the HTML generated in the first wave of indexing and not the one generated by the Googlebot renderer .
In tests that we have performed, when the HTML painting has taken more than 19 seconds, it has not indexed anything. Although this is a long time, in certain cases it can be exceeded, especially if we make an intensive use of AJAX, since in these cases, the Google renderer, as in any renderer, has to wait for the following steps to occur:
- The HTML is downloaded and processed to request the linked files and create the DOM.
- The CSS is downloaded, processed to request the linked files and create the CSSOM.
- The JavaScript is downloaded , compiled and executed to launch the AJAX request(s).
- The AJAX request goes to a request queue, waiting to be served along with the rest of the requested files.
- The AJAX request is launched and has to travel through the network to the server.
- The server handles the request by returning the response over the network and, finally, you have to wait for the JavaScript to execute, so that it paints the content in the HTML template of the page.
The request and download times of the above process depend on the network and server load at the time, and Googlebot only uses the HTTP/1.1 protocol. This is slower than the HTTP/2 protocol because requests are handled one after the other and not all at once. Both the client and server need to allow HTTP/2 to be used, so Googlebot will use HTTP/1.1 even if our server supports HTTP/2. In short, this means that Googlebot waits for each request to finish before launching the next one and may not try to parallelize some requests by opening several connections, as browsers do (although we don’t know for sure how it does it). Therefore, we are faced with a situation in which we could exceed the 19 seconds we have estimated.
Imagine, for example, that between images, CSS, JavaScript and AJAX requests, more than 200 requests are launched, each taking 100 milliseconds. If AJAX requests are at the end of the queue, we will probably exceed the time required for their content to be indexed.
On the other hand, due to these CSR performance problems, we will obtain a worse score for PageSpeed’s FCP (First Contentful Paint) metric for the paint WPO and consequently worse positioning.
Indexing problems:
When indexing content that is painted on the client, Googlebot may encounter the following cases that will prevent the indexing of JavaScript-generated HTML:
- A version of JavaScript is used that is not recognized by the crawler.
- It uses a JavaScript API that Googlebot does not recognize (Web Sockets, WebGL, WebVR, IndexedDB and WebSQL are currently known to be unsupported – more information at https://developers.google.com/search/docs/guides/rendering).
- JavaScript files are blocked by robots.
- JavaScript files are served over HTTP and the web is in HTTPS.
- There are JavaScript errors.
- If the application asks the user for permissions to do something and it depends on this that the main content is painted, it will not be painted because Googlebot denies by default any permissions asked for.
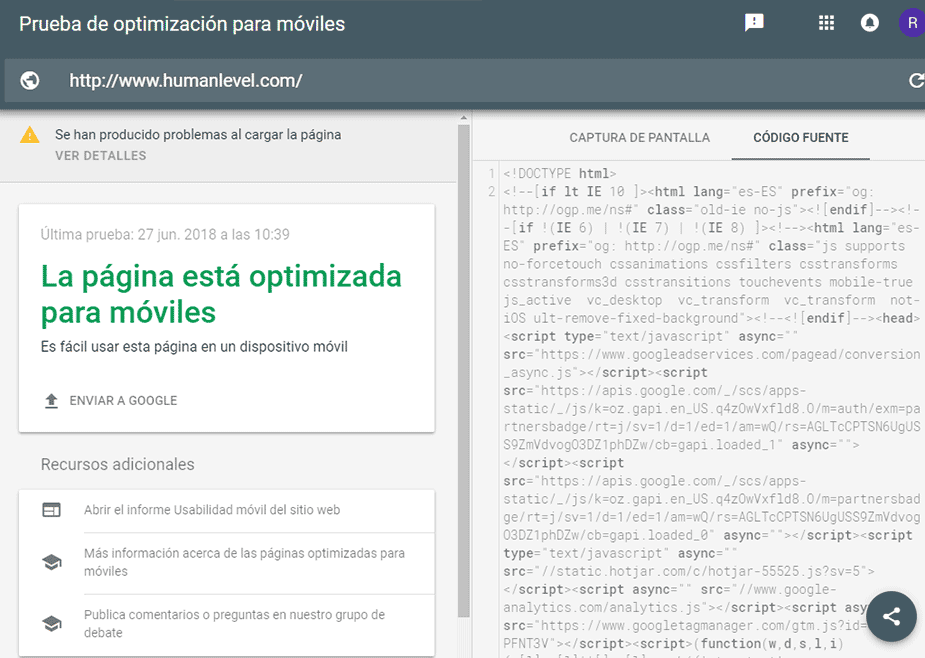
To find out if we have any of these problems, we must use Google’s “mobile friendly test“. It shows us a screenshot of how the page is painted on the screen. The same as Google Search Console does, but in addition, it also shows us the HTML code generated by the renderer (as we have already mentioned), the records of JavaScript error logs that the code may have and the JavaScript functionalities that the renderer does not yet know how to interpret. So we should apply this tool to the representative URLs of each page template of the site, in order to be sure that the site is indexable.
In the HTML generated by the previous tool, we have to take into account that all the metadata (canonical URL included) will be ignored by the robot since Google only takes this information into account when it is painted on the server.
Now let’s see what happens when we browse a link when we are already inside the web and the HTML painting is done in the client.
Indexing problems
In contrast to CSR on initial load, navigation to the next page by changing the main content to JavaScript is faster than SSR. But we will have problems indexing if:
- The links do not have a valid URL in their href attribute that returns 200 OK.
- The server returns error when accessing the URL directly without JavaScript or with JavaScript enabled and clearing all caches. Be careful with this, if we browse the page by clicking on a link, it may appear to work because the loading is done by JavaScript. Even when accessing directly, if the website uses a Service Worker, the website can pretend that it does respond correctly by loading the contents of the Service Worker’s cache. But Googlebot is a stateless spider, so it doesn’t take into account any Service Worker cache or any other JavaScript technology like Local Storage or Session Storage, so you will get an error.
In addition, for the web to be accessible, the URL must change using JavaScript with the history API as I explained in the entry AJAX accessible and indexable.
What happens to snippets now that Google can index AJAX?
The snippets are the part of the URL that may appear at the end of the URL and are padded. Example:
http://www.humanlevel.com/blog.html#ejemploThis type of URLs never reach the server.are managed only on the client, so that when requesting the above URL from the server, the request for “http://www.humanlevel.com/blog.html” would arrive and on the client the browser will move the scroll to the document fragment it refers to. This is the normal usage and the original intention of these URLs, which became popularized with the name anchor, although an anchor, in reality, is any link (the “a” tag in HTML comes from anchor). However, in the past, snippets have also been used to modify URLs by JavaScript in AJAX-loaded pages, with the intention of allowing the user to navigate through the history. This was implemented this way because previously the snippet was the only part of the URL that could be modified by JavaScript, so developers took advantage of this to give them a use for which they were not intended. This changed years ago with the appearance of the history API, since it already allowed the entire URL to be modified by JavaScript.
When Google was not able to index AJAX, if a URL changed its content using AJAX based on the snippet part of it, we knew that only the URL and the content without the snippet would be indexed. So what happens to pages with snippets now that Google is able to index AJAX? The behavior is exactly the same. If we link to a page with a snippet and it changes its content when accessed with the snippet, the content it had without the snippet will be indexed and the popularity will go to this URLbecause Google trusts that the snippet will be used as an anchor and not to change the content, as it should be.
However, Google does currently index URLs with hashbang (#!). This is implemented without having to do anything more than add the exclamation, and Google makes it work to maintain backward compatibility with an obsolete specification to make AJAX indexable. But it is not recommended to do this because it is now implemented with the history API and also because Google could stop indexing hashbang URLs at any time.
Blocking indexing of partial responses by AJAX
When an AJAX request is launched to URLs of a REST API or GraphQL, a JSON or a page snippet is returned that we do not want to be indexed. So the indexing of the URLs to which these requests are directed must be blocked .
In the past it was possible to block with robots.txt, but since the Googlebot renderer exists, we can no longer block any resource used for HTML painting.
Nowadays, Google is a little smarter and not usually try to index the responses with JSONs, but if we want to be sure that they are not indexed, the universal solution for all spiders is to make URLs used for AJAX only support POST requests, since it is not used by spiders. When a GET request arrives at the server, it should return error 404. For development purposes, this does not force you to remove the parameters in the QueryString part of the URL.
There is also the possibility of adding to AJAX responses the HTTP header “X-Robots-Tag: noindex” (invented by Google) or that these responses are returned with 404 or 410 codes. If these techniques are used with content that loads directly from the HTML, it will not be indexed, just as if we had blocked it through the robots.txt file. However, since it is the JavaScript that paints the response on the page, Google does not establish the relationship between this response and the JavaScript that paints the content, so it does exactly what we want. That is, do not index the partial response and index the entire generated HTML. But beware, this does not mean that someday this behavior will change and we will be deindexed the content loaded by AJAX if we apply this technique.
Conclusion
Google can now index JavaScript and AJAX, but this inevitably comes at a higher cost than indexing HTML already “chewed up” on the server, so SSR is and will be the best option for quite some time to come. But if you have no choice but to deal with a fully CSR website or with some part of it using CSR, you know how to deal with it.



