

Written by Ramón Saquete
Índice
- How is JavaScript recommended to be implemented?
- How to check the behavior of the Google robot?
- Are there technologies that stop working with each new version of the robot?
- How does the evergreen Googlebot affect polyfills and transpiled code?
- Which JavaScript technologies should we pay special attention to?
- Is AJAX allowed?
- How does Google behave with session variables and data in the client?
- Conclusions
In May 2019, Googlebot stopped using the JavaScript engine from Chrome version 41, to keep it always updated to the latest version, changing its name from evergreen Googlebot. Although this change improves the situation, there are JavaScript technologies that the robot cannot execute and must be taken into account to index all content instead of an error message.
As you may already know, Googlebot does not always index JavaScript, but when it does there are technologies that it cannot execute. Let’s take a look at what should be taken into account to handle these situations.

How is JavaScript recommended to be implemented?
In general, we should always detect which technologies are supported by the browser and, in case they are not supported, there should be an alternative content accessible to the user and the robot. Suppose that instead of displaying alternative content, an error page is displayed: if the Google robot executes the JavaScript and does not enable the use of this technology, it would index this error message.
If we use advanced features, it is always advisable to try disabling them in the browser (this can be done from chrome://flags in Chrome) and see how the page behaves in these cases.
In implementation, developers can follow one of two strategies:
- Progressive enhancement: it consists of starting with a basic content of text and images and adding advanced functionalities.
- Graceful degradation: it consists of starting with content with advanced functionalities and degrading to more basic functionalities, until reaching the basic content.
Google recommends progressive enhancement, because this makes it more likely that we will not leave any situation uncovered. The name PWA (Progressive Web Applications) comes from there.
It is also advisable to implement the onerror event on the web to return JavaScript errors via AJAX to the server. In this way, they can be saved in a log that will help us to see if there is any problem with the rendering of the pages.
How to check the behavior of the Google robot?
Google updates the version of Googlebot not only in the spider, but also in all its tools: the URL check in Google Search Console, Mobile Friendly Test, Rich Results test and AMP test.
So if we want to see the rendering of the page with the latest rendering engine from Googlebot or Web Rendering Service (WRS) and JavaScript errors, we can do it either from Google Search Console in the “Inspect URL” option and, after the analysis, click on “test published URL”; or you can also do it from the mobile friendly test tool.
Are there technologies that stop working with each new version of the robot?
Google Chrome sometimes removes features in its updates (which we can be informed about here and here), features that are usually experimental and have not been active by default. For example, the WebVR API for virtual reality has been deprecated in version 79 in favor of the WebXR API for virtual and augmented reality.
But what happens when the feature is not so experimental? There is the case of the Web Components v0: when Google announced that it was going to remove them in version 73 (since Chrome was the only browser that supported them and the Web Components v1 are supported by all browsers), “early adopter” developers asked Google for more time to update their developments, so that have had to delay its complete phase-out until February 2020.. However, it is unusual for a website to stop rendering well because of a Googlebot update as Google engineers always try to maintain API backward compatibility, so we usually don’t have to worry about this. Anyway, if we have implemented in the web the onerror event, as we have commented before, we will be able to see in the logs if some error arises.
If we want to be very cautious, we can have located the URLs of each template that uses the web and check them all, with each Googlebot update, using the mobile friendly test tool. In any case, we should always check the rendering of all templates with every update of the web code.
How does the evergreen Googlebot affect polyfills and transpiled code?
When a JavaScript feature doesn’t work in all browsers, developers use polyfills which fill in the code not implemented by the browser with a lot of additional JavaScript code.
By having the most updated robot engine, it is not necessary to load polyfills with the intention that the robot sees the page well, but we must do it if we want users of other incompatible browsers to see it correctly. If we want to support only modern browsers, with the evergreen Googlebot less polyfills can be used and the web will load faster.
Similarly, it may not be necessary to transpile or convert JavaScript code to an older version to support Googlebot (unless we are using a very modern or extended version of JavaScript such as TypeScript). But again, yes to support all browsers.
Which JavaScript technologies should we pay special attention to?
With the switch from Googlebot with Chrome version 41 to the evergreen Googlebot, there are technologies that previously caused page rendering errors that now work correctly. We are referring to the Web Components v1, the CSS Font API loading to choose how we load fonts, a WebXR for virtual and augmented reality, a WebGL for 3D graphics, a WebAssembly to execute code almost as fast as in a native application, the Intersection Observer API and the loading=”lazy” attribute to apply the lazy loading technique to images, and new features added to JavaScript from the EcmaScript 6 standard.
But beware of some of these technologies: when they are used, it is always advisable to check that Googlebot renders them in case there are any features that have not been implemented by the robot. Furthermore, even if it is rendered, this does not mean that Google will be able to index the content displayed within a 3D or augmented reality image, but that the robot will not block the rendering and will not give an error.
There are technologies with which Googlebot does not give error but does not use them for logical reasons, because Googlebot is not a user, but a spider. These technologies are:
- Technologies that require user permissions: for example, when we display a certain content, depending on the user’s geolocation, through the Navigator.geolocation API and, when permission is denied, we present an error message. This error will be indexed because Googlebot denies by default all requested permissions, so it will be better to display a warning and generic content.
- Service Workers: they are installed in the browser on the first request to offer services typical of a PWA, such as saving pages in the Cache object to offer them in offline mode or offering the user Push notifications. These functionalities do not make sense for a spider. As a result, Googlebot simply ignores them.
- WebRTC: it would not make sense for the robot to index the content of a technology useful for P2P communication between browsers. Typically, this is used by web applications such as Skype or Hangouts once the user is logged in, but Googlebot does not log in or make video calls.
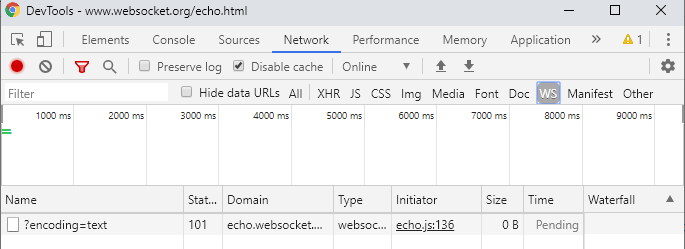
- WebSockets: web sockets are used to send content updates from the server without being requested by the web browser. This allows chats or content updates to be implemented while the user is browsing, although it can also be used as a substitute for AJAX. But Googlebot does not allow connections with websockets, so if the web loads the main content with WebSockets, it will not be indexed even if Googlebot gets to execute the JavaScript.
To find out if websockets are used on a website, we can resort to the WS tab of Google Chrome’s developer tools:
Websocket in Google Chrome Developer Tools Again, this is not to say that Googlebot does not support the technology, but rather that it does not use it by not allowing connections:
Googlebot implements websockets but does not allow connection initialization.
Is AJAX allowed?
When Googlebot runs JavaScript, it has no problem executing the fetch or XmlHTTPRequest APIs that implement AJAX. But be careful: each AJAX request counts in the crawl budget (so if we have many, the indexation of the portal will drop).
On the other hand, if content is retrieved by AJAX on initial load, it will not be indexed if Google does not have render budget to execute JavaScript on that page.
How does Google behave with session variables and data in the client?
On a website, to maintain status between requests (maintaining status is knowing what actions the user has performed before, such as logging in or adding products to the cart) you can use cookies where to store an identifier, called session cookie value. This value identifies a memory area in which to store session variables on the server.
However, using the SessionStorage, LocalStorage and IndexedDB APIs, we can store information in the browser to maintain state and, if it is a SPA or Single Page Applications, state can be maintained in the client’s memory simply by means of JavaScript variables.
If Googlebot’s behavior with cookies is based on the fact that with each request it is considered as if it were a new user that does not send any cookie, with SessionStorage and the rest of technologies to maintain the state is the same.
Although Googlebot supports SessionStorage, LocalStorage and IndexedDB and if we program with these technologies, it will not give any error, in each request has these empty data stores. The URLs will always have the same content, as if it were a new user, so nothing that depends on the status will be indexed and the URLs will always have the same content. Similarly, if it is an SPA, the robot will not navigate through the links by clicking, but will load each page from the beginning, initializing all the JavaScript code and its variables with each request.
Conclusions
It is always best if websites are implemented in such a way that all their content can be indexed without the use of JavaScript but if this technology is used to offer functionalities that provide added value to the user, care must be taken in the way they are implemented, to avoid rendering errors and indexing error messages.



