

Written by Ramón Saquete
Índice
The shadow DOM is difficult to index, as it can only be created with JavaScript and there is no way to declare it in the HTML. However, it is a very useful technology to facilitate the work of developers, so it is increasingly common to find it in new developments. Here we will see what the shadow DOM is, what problems it creates for indexing and how you can try to make it indexable.
Before getting into the subject, let’s remember what web componentsare : they encompass several technologies, including the shadow DOM.
Web components
The shadow DOM is one of the technologies that we have been talking about for years, used by the web components. Since then, the specification has evolved from v0web components (which were only compatible with Chrome while requiring polyfills or frameworks for other browsers), to v1web components, which are compatible with all of them.
Web components do not bring anything new to the user, but they are an excellent way to isolate parts of the code of a website, facilitating the parallel work of different developers on the front end. Components prevent one developer’s code from affecting another developer’s code, by enabling their encapsulation, because the CSS and JavaScript code inside the shadow DOM is isolated from the rest of the page, within a new HTML tag or custom elementdefined with the name that the programmer wants to give it. For this reason, this technology is appearing more and more frequently in new developments, as can be seen in the following graph, which shows the use of custom elements in Chrome, which is one of the base technologies that form the web components:
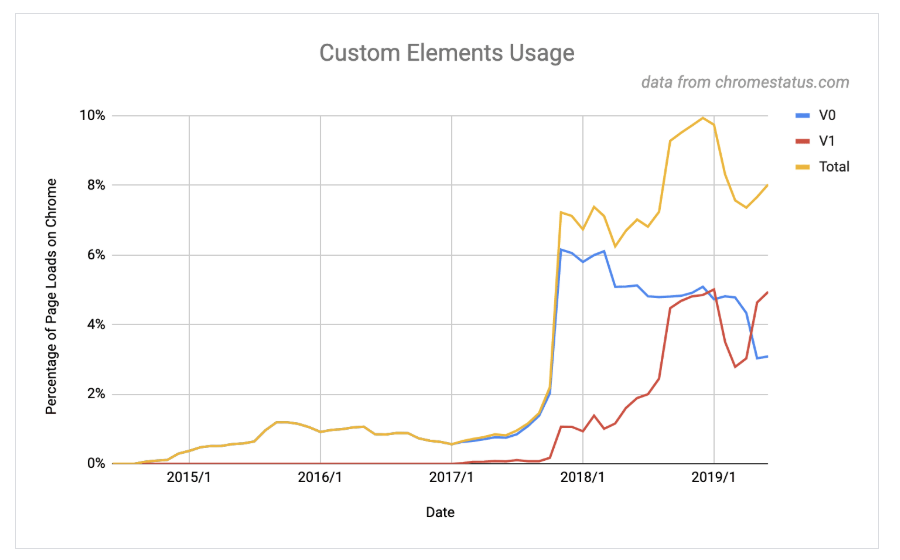
This type of components should not be confused with the components of a framework such as Vue, Angular JS or React, as they directly replace the component with HTML code in the DOM light and can do it on the server using their version of universal and therefore do not pose as many indexability problems as the real ones. web components.
Difference between light DOM, shadow DOM and composed DOM
In terms of indexability, the DOM light is the part of the component that is visible in the code without executing JavaScript and therefore indexable. On the other hand, the shadow DOM is the part of the implementation that remains hidden and creates the developer using JavaScript and, as we already know, Google does not always have render budget to execute the JavaScript of the pages it indexes and, therefore Google recommends that whenever possible, the content to be indexed should be in the light DOM..
The composed DOM is the mixture of both, since in the shadow DOM we can define holes, called slots, in which we can assign pieces of the light DOM.
Let’s see it with an example: let’s suppose we have a web component (these are recognized because they use an HTML tag with a hyphen in the name, in this case “my-component”). This is how the HTML code of this component, without executing JavaScript, would look like:
<mi-componente>
<span slot="titulo">Título en el light DOM pero con H3 en el shadow DOM</span>
<p>Texto en el light DOM</p>
</mi-componente>
In addition, we assume that the component has a template declared as follows, in which there is a slot with the name “title” and another, initially unnamed, which will take the contents of the component that has no slot name assigned to it:
<slot></slot> <h3><slot name="titulo"></slot></h3> <p>Texto en el shadow DOM</p>
If we run JavaScript in the above component, the browser will generate the following code, which is the shadow DOM composed with the light DOM, i.e. the composed DOM:
<p>Texto en el light DOM</p> <h3>Título en el light DOM pero con H3 en el shadow DOM</h3> <p>Texto en el shadow DOM</p>
In this case, if Google does not run JavaScript, it will not know that the title uses an h3 tag, it will not see the paragraph that says “Text in shadow DOM” and it will crawl the text in another orderThis is detrimental to the positioning of the page that uses this component, as it is not able to give sufficient importance to the header and loses part of the content and order of the same.
How to know which parts of a web component are in the shadow DOM?
If we disable JavaScript on a page, we will not see anything in the shadow DOM. or require JavaScript, but if we want to know specifically which parts of a component are in the shadow DOMwe can use the inspect element, with JavaScript enabled, and the browser will show us the shadow DOM and the light DOM separatelygiving a shading to the first one. Example:
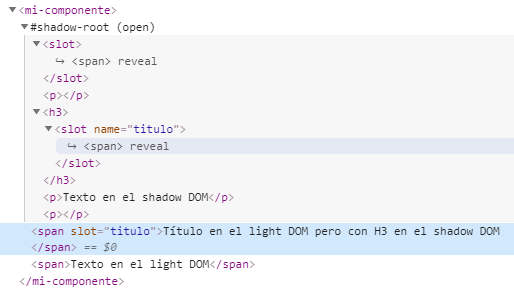
In this Google Chrome screenshot, where we see the component of the previous example with the inspect element tool, we can see that the shadow DOM appears inside the #shadow-root tag, indicating that it is the root of the shadow DOM. In addition, if we click inside a slot, it highlights the associated HTML in the DOM light.
How to make the shadow DOM indexable?
Currently, the only way to make the Shadow DOM indexable is to use a technique called DOM rehydration . This involves running code on the server that calculates the DOM composite of the component as the browser would, to replace the component with this code. In this way, everything stays generated in the HTML created on the server before reaching the client. One JavaScript library that implements this technique is skatejs. However, depending on the web component, this solution may cause problems.
Another option is, as suggested by Google, to bring all content likely to affect positioning to the light DOM. But we can do this only in certain cases. For example: if the component is a button that performs an action, such as sharing the page on a social network, it is not even necessary to have light DOM. If, on the other hand, it is a component that formats a question and answer block, it can be more problematic, especially if we want to keep the semantic markup of headers and other semantic HTML tags in the DOM light, and that the page styles do not affect these tags.
Conclusions
Web components are very useful for custom development and, if their use is extended to CMSs, it will be possible to better isolate the code of different plugins to avoid incompatibilities. However, to ensure the indexability of the pages, we must either not use web components or bring all the important code into the component’s light DOM or force developers to use the complex solution of rehydrating the DOM.
None of these approaches is good, because the ability to encapsulate the code is lost, which is the main reason for using web components. So it is to be expected that in the future the specification will evolve to allow declaring the shadow DOM in the HTML in an explicit and indexable way.



