

Escrito por Fani Sánchez
Índice

¿Qué es el archivo robots.txt?
 Robots.txt es un archivo de texto con extensión .txt, que creamos y subimos a nuestro sitio Web y que utilizamos para impedir que los robots de ciertos buscadores rastreen contenido que no deseamos que indexen ni muestren en sus resultados.
Robots.txt es un archivo de texto con extensión .txt, que creamos y subimos a nuestro sitio Web y que utilizamos para impedir que los robots de ciertos buscadores rastreen contenido que no deseamos que indexen ni muestren en sus resultados.
Es decir, es un archivo público que usamos para indicar a esos rastreadores o arañas qué parte o partes no deben entrar a rastrear e indexar de nuestra página web. En él, podemos especificar de manera sencilla, los directorios, subdirectorios, URLs o archivos de nuestra web que no deberían ser rastreados o indexados por los buscadores.
Debido a que está íntimamente relacionado con la indexación del sitio web, es fundamental programar adecuadamente este archivo, sobre todo si nuestra web está hecha con un gestor de contenidos (CMS) que lo genere automáticamente, ya que puede suceder que accidentalmente se incluyan como no indexables partes que sí deberían ser rastreadas.
También llamado protocolo de exclusión de robots o protocolo robots.txt, es consultivo y no garantiza el pleno hermetismo, pero a veces lo encontramos utilizado para mantener privadas partes de un sitio web. Debido a que ese aislamiento no es pleno se desaconseja su uso para mantener privadas cierta áreas, pues sirve como recomendación y no como obligación, siendo una golosina para hackers que con un navegador y los conocimientos necesarios, pueden fácilmente acceder a ellos.
Normalmente los usos más habituales son para evitar la accesibilidad a determinados partes del sitio web, impedir la indexación de contenidos duplicados (por ejemplo las versiones imprimibles de la web), o para indicarle a Google cuál es nuestro sitemap, incluyendo su URL en el archivo.
http://www.ejemplo.com/sitemap.xml
¿Cómo creamos el archivo robots.txt?
Para poder crearlo, necesitamos acceso a la raíz del dominio y subir el archivo en formato texto con nombre “robots.txt”, al directorio raíz de primer nivel del servidor de nuestra web.
http://www.ejemplo.com/robots.txt
Elementos del archivo Robots.txt
Comandos
Los principales comandos que emplearemos en un robots.txt serán
- User-agent o agente de usuario son los robots o arañas de los motores de búsqueda. Puedes ver a la mayoría de ellos en esta base de datos de robots web. Su sintaxis sería:
Usser-agent: [nombre del robot al que aplicaremos la regla] - Disallow indica al agente de usuario o user agent que no debe acceder, rastrear ni indexar una URL, subdirectorio o directorio concreto.
Disallow: [directorio que quieres bloquear] - Allow surge como contra al anterior, con él indicas al rastreador una URL, subdirectorio o directorio al que si debe entrar, rastrear o indexar.
Allow: [URL de un directorio o subdirectorio bloqueado que quieres desbloquear]
Reglas específicas
La reglas especificadas en el Disallow y Allow solo se aplican a los agentes de usuario que hayamos especificado en la línea anterior a ellas. Se pueden incluir varias líneas Disallow a diferentes agentes de usuario.
Otros elementos
- Barra inclinada “/”, debe adjuntarse antes del elemento que quieres bloquear.
- Reglas de concordancia, son patrones que pueden usarse para simplificar el código del archivo robots.txt.
Ejemplo: *, ?, $
Asterisco (*): bloquea una secuencia de caracteres
Símbolo del dólar ($): para bloquear URLs que terminen de una forma concreta
Sintaxis de comandos más utilizados en robots.txt
- Indicaciones a un bot concreto:
User-agent: [nombre del bot]
User-agent: Googlebot
- Indicaciones a todos los bots:
User-agent: *
- Bloqueo de todo el sitio web, utilizando una barra inclinada “/”:
Disallow: /
- Bloquear un directorio y su contenido, incluir tras la barra inclinada el nombre del directorio:
Disallow: /directorio/
- Bloquear una página web específica, indicar tras la barra la página concreta:
Disallow: /pagina-privada.html
- Bloquear todas las imágenes del sitio web:
User Agent: Googlebot-Image
Disallow: /
- Bloquear una sóla imagen, especifica la imagen detras de la barra inclinada:
User-agent: Googlebot-Image
Disallow: /imagen/privada.jpeg
- Bloquear un tipo de archivo concreto, mencionando, tras la barra, la extensión:
User-agent: Googlebot
Disallow: /*.png$
- Bloquear una secuencia de caracteres, usar el asterisco:
User-agent: Disallow: /directorio-privado*/
- Bloquear URLs que terminen en una forma concreta, añadir al final el símbolo $:
User-agent: *
Disallow: /*.pdf$
- Permitir acceso completo a todos los robots:
User-agent: *
Disallow:
Otra forma sería no usar el archivo robots.txt o dejarlo vacío.
- Bloquear un robot o bot concreto:
User-agent: [nombre del bot]
Disallow: /
- Permitir el rastreo a un bot concreto:
User-agent: [nombre del bot]
Disallow:
User-agent: *
Disallow: /
A la hora de escribirlos debes tener en cuenta que existe la distinción entre mayúsculas, minúsculas y espacios.
Probando el archivo robots.txt en Google
Para comprobar el funcionamiento del archivo robots.txt, tenemos la herramienta de prueba para robot.txt en Google Search Console, donde puedes probar y ver como lo leerá el Googlebot, de forma que te mostrará posibles errores o defectos que el archivo tenga o pueda ocasionar.
Para realizar la prueba dirígete por tanto a Google Search Console y en su panel de control, en la sección de Rastreo, elige la opción «Probador de robots.txt«.

Dentro del probador, aparecerá tu archivo robots.txt actual, puedes editarlo, o copiar y pegar el que quieras probar. Una vez escrito el archivo robots a probar, selecciona la URL que quieres comprobar si va a ser bloqueada y el robot rastreador con el que quieres probarla.
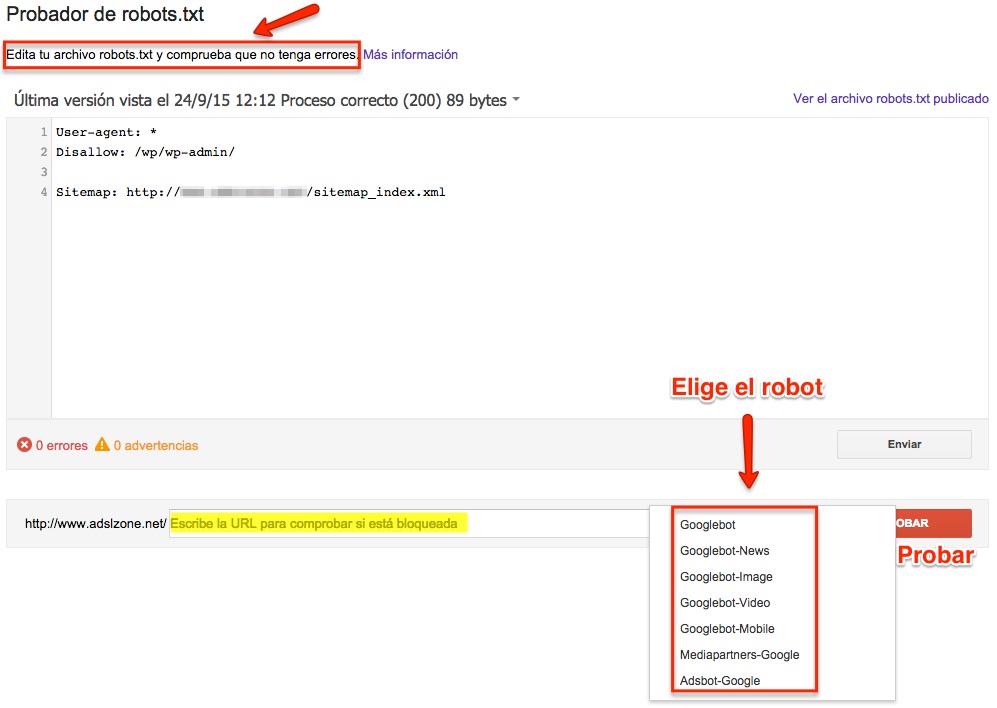
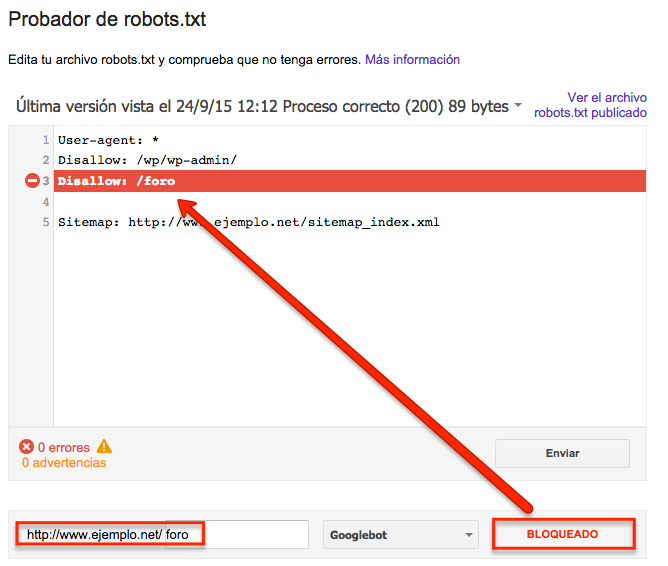
La herramienta te dará dos opciones: «permitido», es decir, la URL no queda bloqueada, o «bloqueado» indicándote la línea de código que está bloqueando esa URL.
Referencias
Información sobre al archivo robots.txt en la página web de los robots
